前段时间参加了一些比赛,自己重新整理了NLP的一些基础知识和现在的前沿技术。感觉越复杂的网络虽然效果大概率会越好,但是他的可解释性实在是差。。。
目录:
- 循环神经网络(RNN)
- 长短记忆神经网络(LSTM)
- Seq2Seq模型
- Attention机制在NLP中的应用
- Transformer
- 总结
RNN
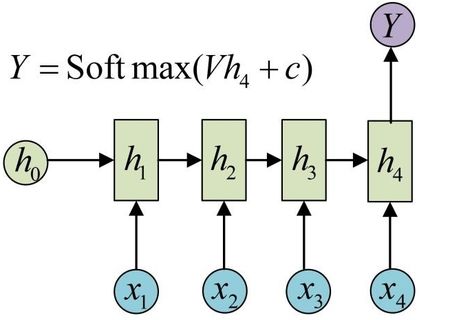
我对RNN的理解关键在于循环二字,t时刻的状态依靠t-1时刻的状态,而t-1时刻的状态又依靠t-2时刻的状态,因此t时刻的状态是由该单元前的所有状态所共同决定的。对于RNN整体的结构我们可以抽象成下图1所示:
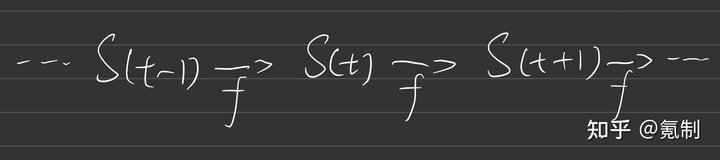
因此他的抽象函数为:
图中的
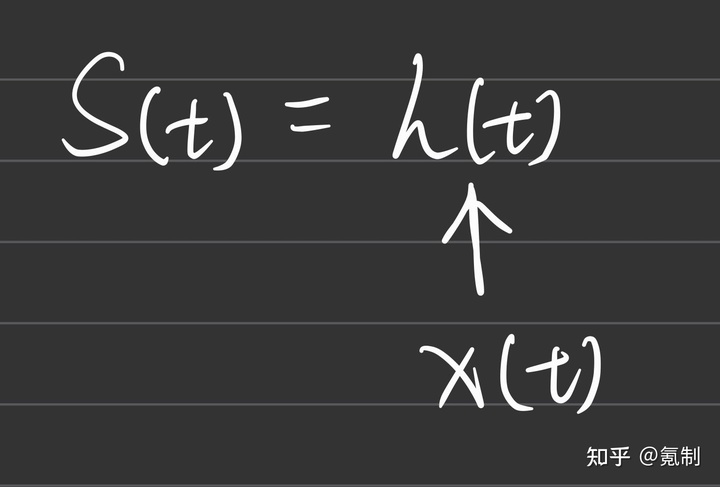
那么
在实际应用中RNN中当前的每个hidden-unit由前一个hidden-unit的输出和输入序列label所共同决定,
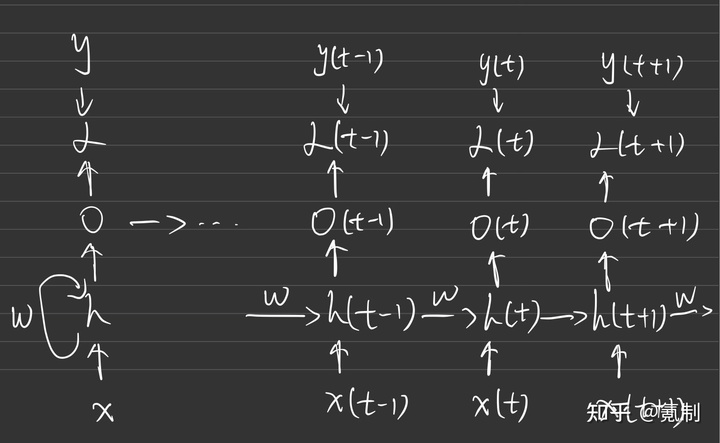
图三我们仔细分析,不过就是将一个个图二中的单元连接起来,每个单元又进行自己的输出,与y(Label)共同作用于损失函数上,得出损失值,在训练过程中不断地迫使损失函数朝收敛的方向前进。
以上就是RNN最基本结构的工作方式,设计思想就是认为序列中前面的每一个单元都会对其后面的预测产生影响,因此在生成下一个序列时要把全部的序列都考虑进去,然后不断循环。但是我们可以很容易的看出其问题在于“全部”,在数学层面上思考,由于训练的参数间会存在极大的相关性,因此其反向传播会有梯度消失的可能。而就主观地来说,一个句子里的任意一部分也都不会和这个句子的所有部分有关系,由此就有了LSTM模型。
LSTM
LSTM的出现主要为了解决长序列训练过程中梯度消失和爆炸的问题,LSTM提出了门的概念,其定义了三种门结构:
首先还是从其模型的结构进行解释,从宏观上来看,LSTM在RNN的hidden-unit中(
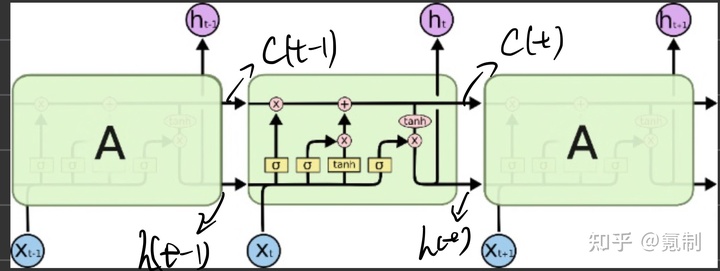
其主要目的在于使网络具有对序列信息提取的随机性和选择性,有效降低训练参数间的相关性。在数学层面上,每个cell都是三输入三输出单元,其结构图5会更清晰地展现:
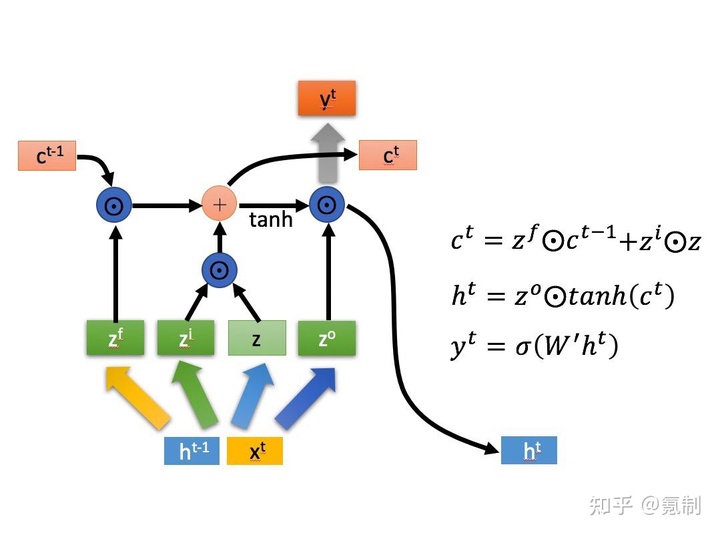
其中三个门控都有自己的控制函数和训练参数:
但是LSTM或是RNN进行序列分析都是基于某段序列之前的信息来对当前序列进行推断,而正常来说我们理解序列一般是根据全局的信息来进行判断得出的,由此下文会提到如何解决这种问题的普适方法,Attention机制。
Seq2Seq
在谈论Attention机制之前,我们先来了解以下encoder-decoder结构。
Seq2Seq其实就是非常典型的encoder-decoder结构,其基本思想就是通过两个RNN网络,一个作为encoder,另一个作为decoder。上面指的RNN结构其实是一种广义上的RNN结构,包括其各种各样的变体。encoder通过把输入序列转换成指定长的向量,decoder通过把encoder输出的向量映射成想要转换的目标序列。下面是Seq2Seq的两种结构:
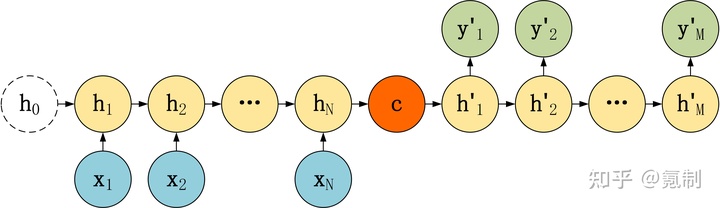
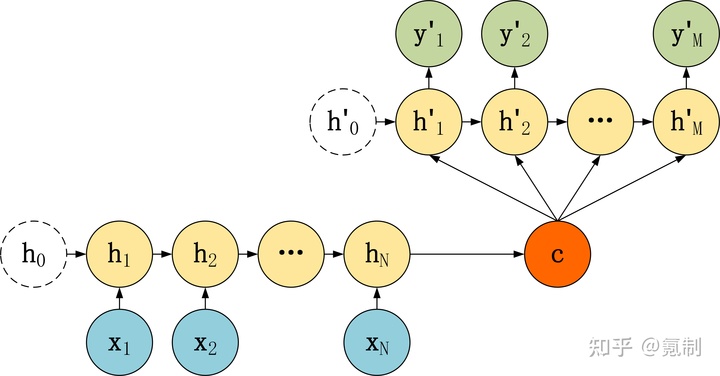
Seq2Seq由于是基于RNN做序列特征提取的,因此RNN对长序列处理效果不佳的缺陷也带到了该模型中去。接下来将会开始介绍Attention机制如何解决这个问题。
Attention机制在NLP中的应用
这里主要介绍Attention机制在NLP中的应用,关于CV上的介绍我会再另外开一篇文章。
在读完谷歌那篇论文《Attention Is All You Need》后,我认为Attention机制实际上是一种相当普适的方法,它能够直接嵌入原网络中加强对中心特征的选择。Attention机制其实也是一种Seq2Seq的方式,attention模型最大的区别就在于它不在要求编码器将所有输入信息都编码进一个固定长度的向量之中,在encoder和decoder中均有不同的地方。
- 在encoder中的hidden-state会堆叠起来,一起传给decoder。
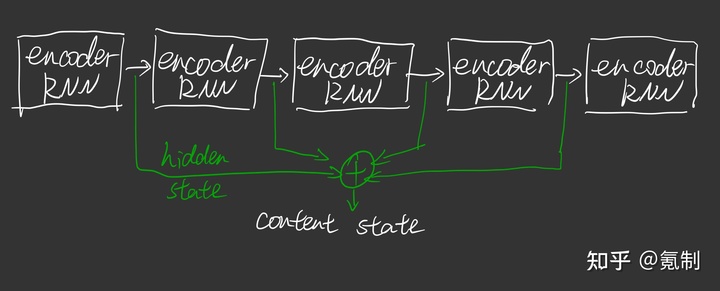
- decoder中每个节点通过对每个hidden state进行选择计算hidden state中对当前节点的关联程度。
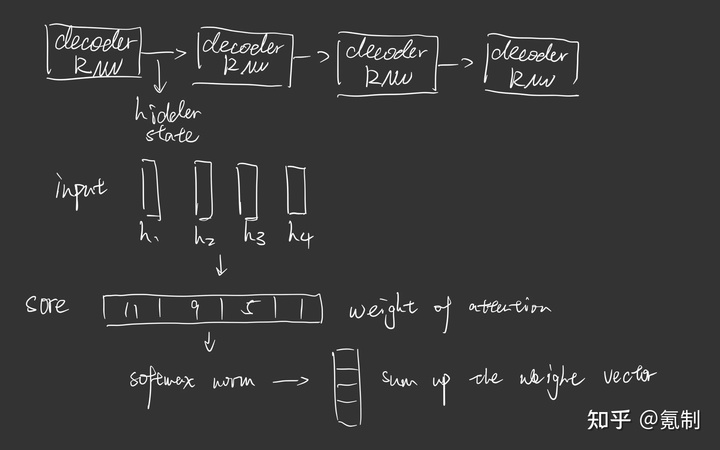
主要的工作原理大概就是这样,具体计算在下文的Transformer中有详细介绍。总结一下:Attention机制最重要的是对所有输入都会进行选择性采纳,类似于CV中的pooling,或者LSTM中的gate作用,但不同的是他是动态选择的概念。
Transformer
Transformer其实也是一个encoder-decoder模型,但是它是完全基于Attention机制的。首先我们先看模型图:
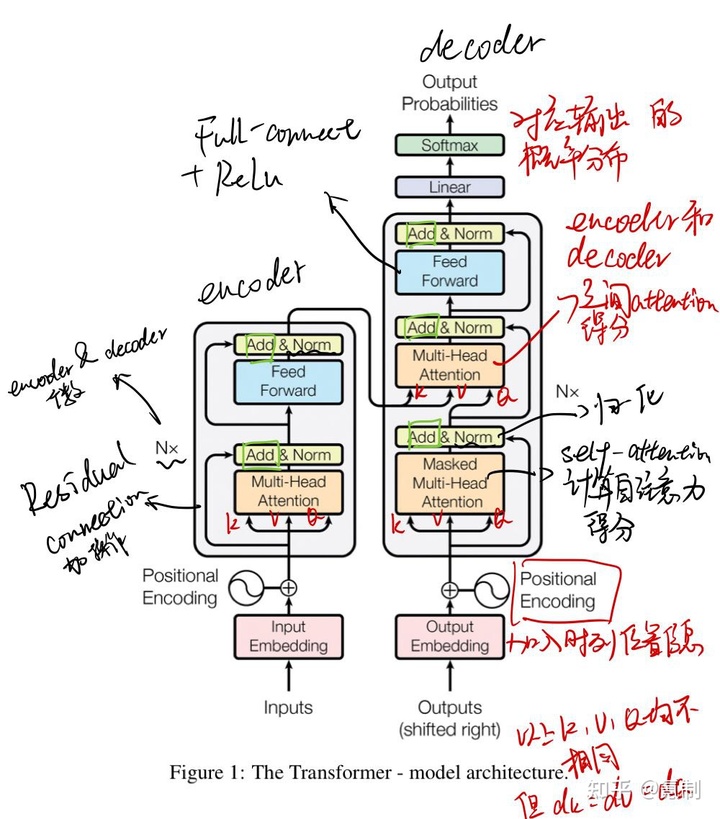
模型左边是encoder,右边是decoder,在input的一开始先把离散的序列通过Embedding全部联系起来。图中的Q(query),K(key)和V(Value)都分别由input序列于权重矩阵相乘获得,三者的值均不相同,但维度是一致的。由于要计算注意力得分因此图中的K,V和Q的顺序是固定的。经过词嵌入处理的KVQ会进入到Multi-Head Attention中:
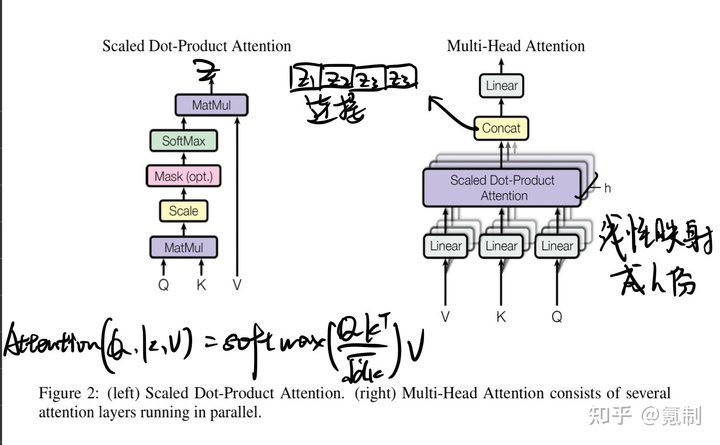
具体的工作方式我在图中标注的很清楚了,值得一提的是为了避免
Transformer中涉及到两种mask,在上两图中我并未编注出来。
padding mask类似于CNN中的padding修改输入图片尺寸的方法,为了使序列对齐,较短的序列会使用负无穷来进行补齐,同时Attention并不会关注到补齐位置,这种padding方法用在Scaled Dot-Product Attention中。
sequence mask用在decoder的self-attention部分,主要为了加入时序的信息,让注意力关注在
总结
总结一下,整个NLP学下来思路其实还是很清晰的,但是其数学方面上的解释却越来越模糊,以上都是在我在学习比赛过程中的一些收获,如果有观点不同的地方欢迎讨论。接下来会补上有关Attention机制CV上的应用和BERT的介绍。
Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems. 2017.Seq2Seq模型概述www.jianshu.com