如果我们想用自动化脚本操作前端页面,用什么方法获取到页面上的元素呢,可以用bs4或者xpath表达式对页面上的元素进行定位之后来操作他,我用火狐浏览器来操作xpath 表达式,在火狐浏览器上下载一个firepath 的工具,一个插件,他是专门来定位页面元素的工具,非常方便,

/ 从根节点选取 ,绝对路径的意思

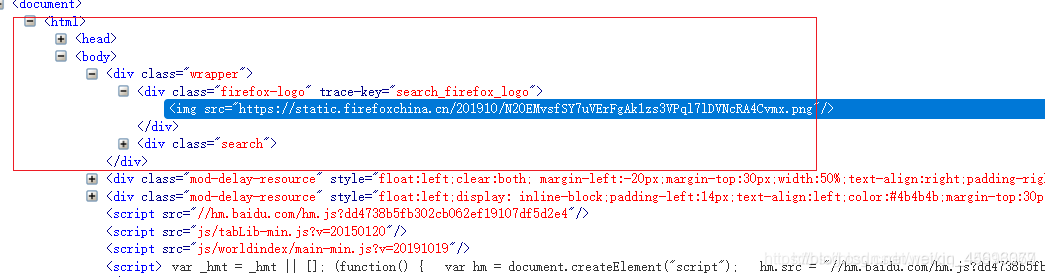
// 相对路径查找的意思
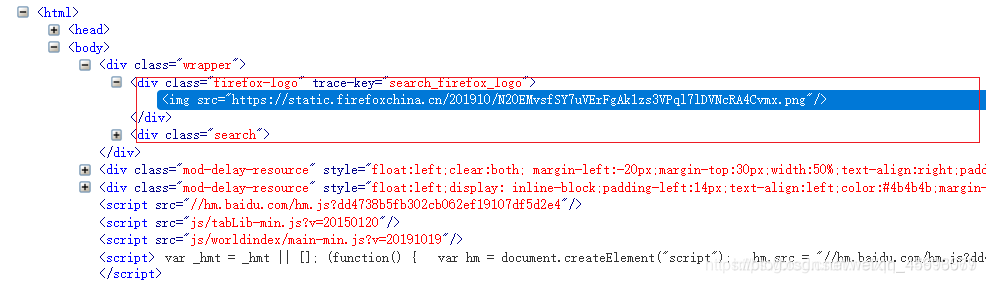
. 点选取当前节点
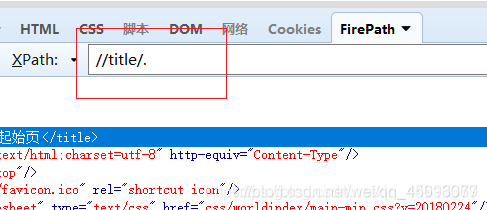
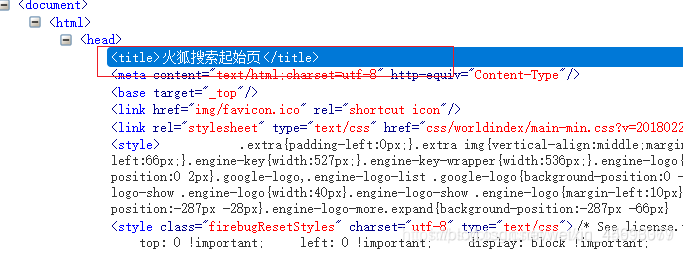
… 上个节点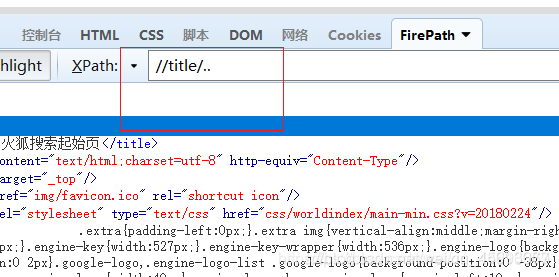

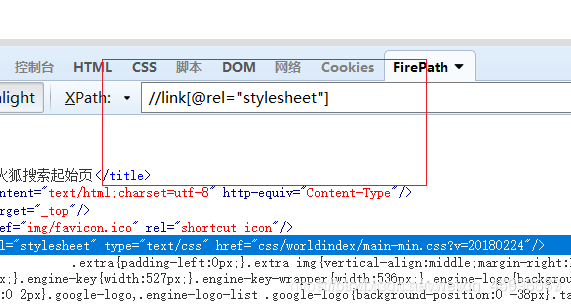
[@属性=之] 通过标签里的属性定位到元素
script[i] 选取第i个script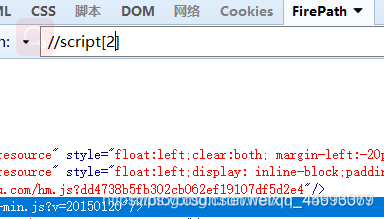

//script[last()] 选取最后一个 last()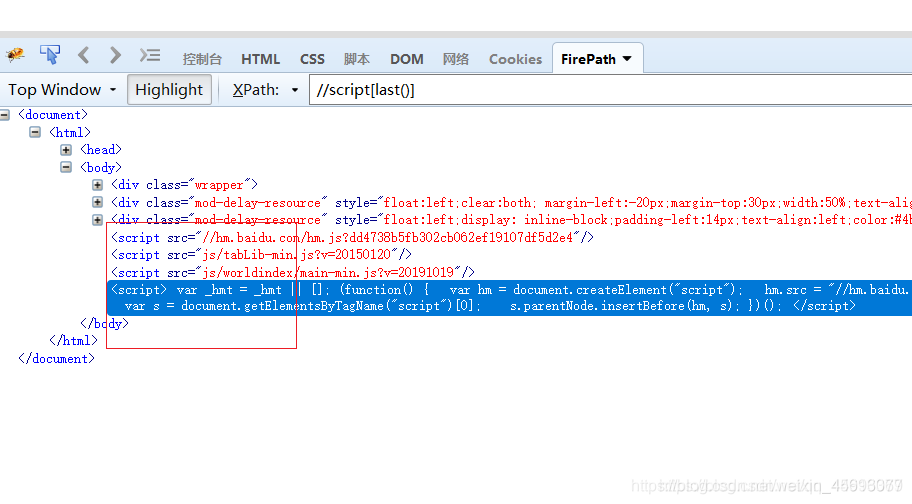
//* 匹配所有的节点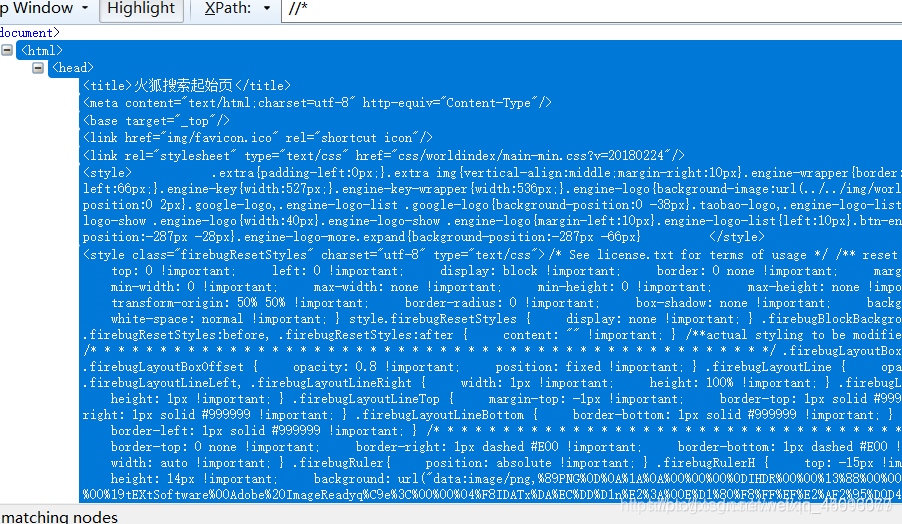
//@* 凡是元素里面有属性的都可以匹配到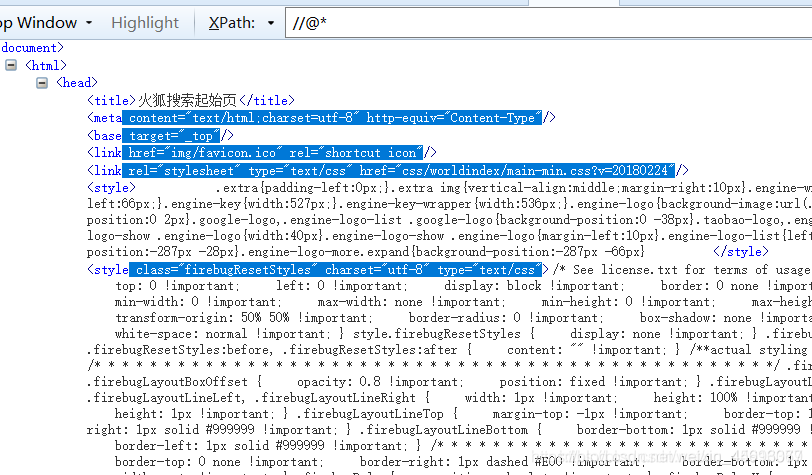
元素/* 一个元素下的所有结点
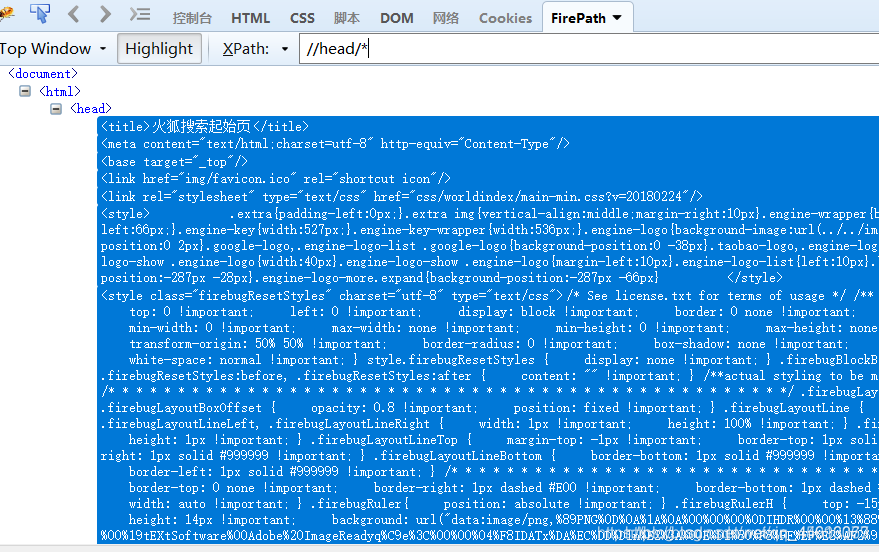
html/node()/div/@*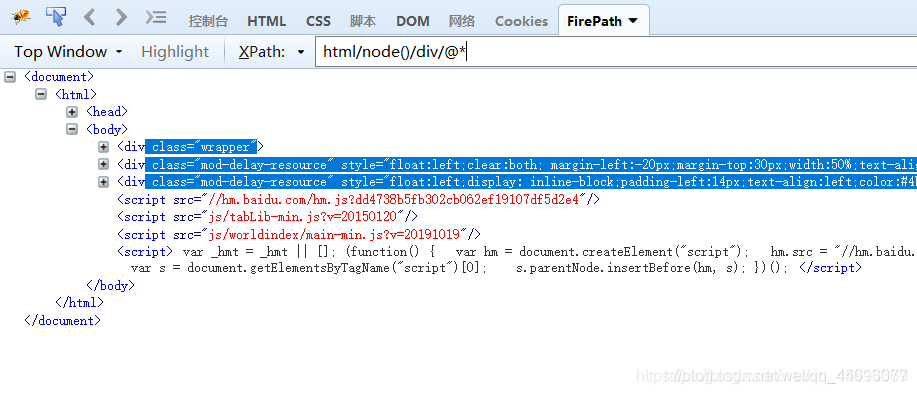
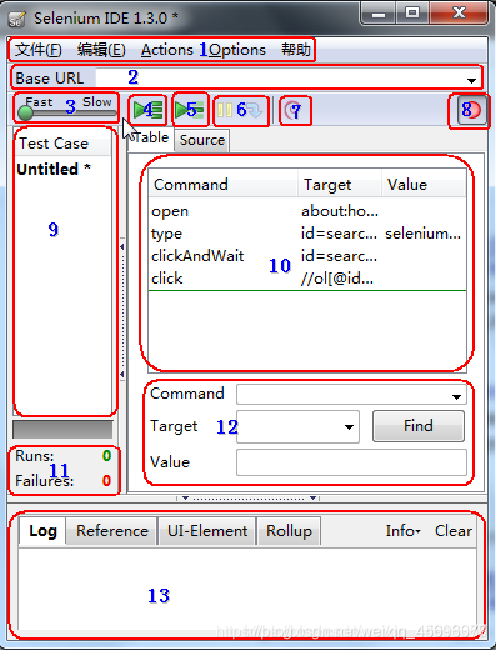
什么是Selenium-IDE?
Selenium的IDE(集成开发环境)是一个易于使用的Firefox插件,用于开发Selenium测试案例。它提供了一个图形用户界面,用于记录使用Firefox浏览器,用来学习和使用Selenium用户操作,但它只能用于只用Firefox浏览器不支持其它浏览器,
1.文件:创建、打开和保存测试案例和测试案例集。编辑:复制、粘贴、删除、撤销和选择测试案例中的所有命令。Options : 用于设置seleniunm IDE。
2.用来填写被测网站的地址。
3.速度控制:控制案例的运行速度。
4.运行所有:运行一个测试案例集中的所有案例。
5.运行:运行当前选定的测试案例。
6.暂停/恢复:暂停和恢复测试案例执行。
7.单步:可以运行一个案例中的一行命令。
8.录制:点击之后,开始记录你对浏览器的操作。
9.案例集列表。
10.测试脚本;table标签:用表格形式展现命令及参数。source标签:用原始方式展现,默认是HTML语言格式,也可以用其他语言展示。
11.查看脚本运行通过/失败的个数。
12.当选中前命令对应参数。
13.日志/参考/UI元素/Rollup
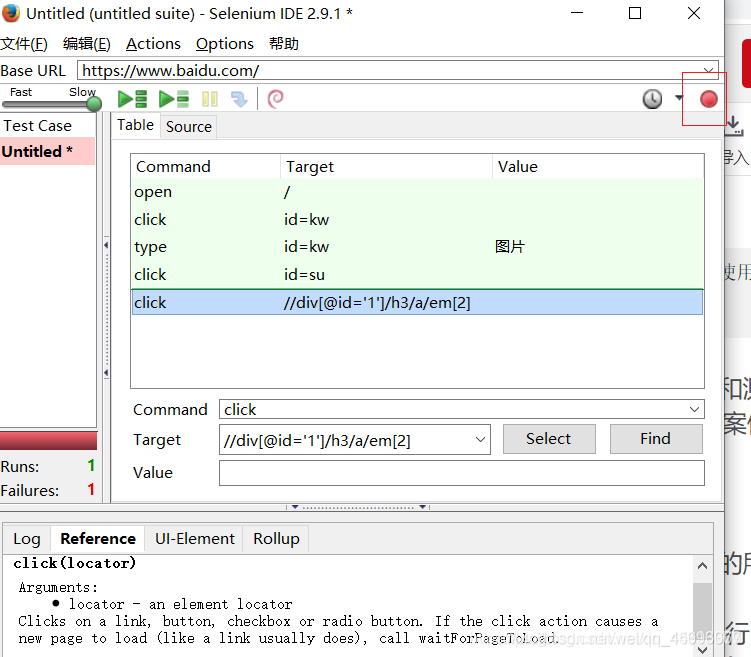
点击开始录制
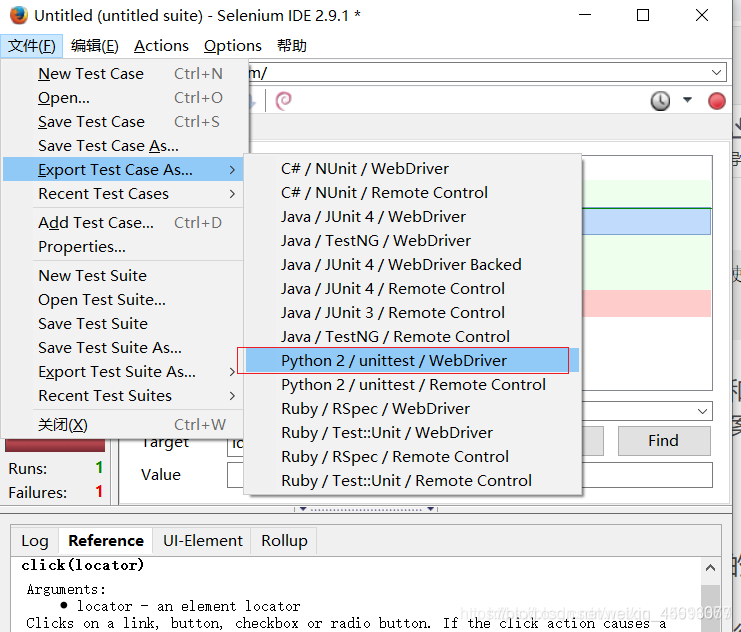
导出python webdriver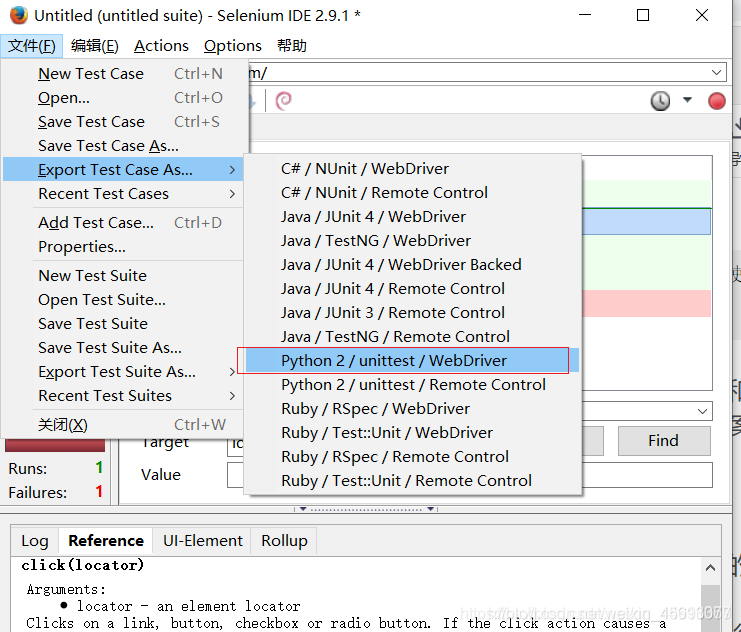
脚本文件生成出来的代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import Select
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import NoAlertPresentException
import unittest, time, re
class Sele(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.implicitly_wait(30)
self.base_url = “https://www.baidu.com/”
self.verificationErrors = []
self.accept_next_alert = True
def test_sele(self):
driver = self.driver
driver.get(self.base_url + "/")
driver.find_element_by_id("kw").click()
driver.find_element_by_id("kw").clear()
driver.find_element_by_id("kw").send_keys(u"图片")
driver.find_element_by_id("su").click()
driver.find_element_by_xpath("//div[@id='1']/h3/a/em[2]").click()
def is_element_present(self, how, what):
try: self.driver.find_element(by=how, value=what)
except NoSuchElementException as e: return False
return True
def is_alert_present(self):
try: self.driver.switch_to_alert()
except NoAlertPresentException as e: return False
return True
def close_alert_and_get_its_text(self):
try:
alert = self.driver.switch_to_alert()
alert_text = alert.text
if self.accept_next_alert:
alert.accept()
else:
alert.dismiss()
return alert_text
finally: self.accept_next_alert = True
def tearDown(self):
self.driver.quit()
self.assertEqual([], self.verificationErrors)
if name == “main”:
unittest.main()
- 简单的通过get请求打开百度的页面
from selenium import webdriver
sd = webdriver.Firefox()
url =“http://www.baidu.com”
sd.get(url)
sd.maximize_window()
- 最大化
sd.get_window_size()
获取浏览器尺寸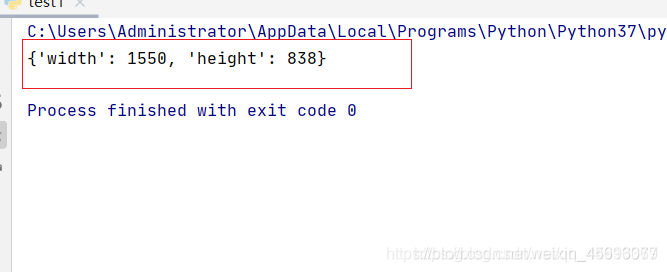
sd.set_window_size(555,666)
- 设置浏览器尺寸
print(sd.get_window_position())
- 获取浏览器位置
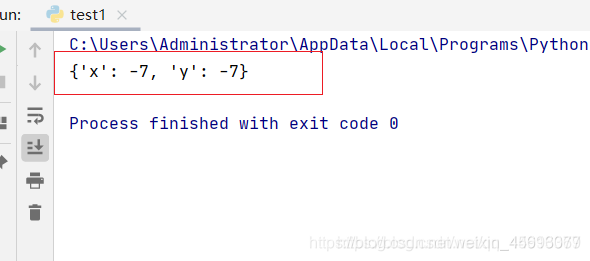
sd.set_window_position(111,222)
设置浏览器位置 浏览器会移动
sd.close()
关闭当前标签/窗口
sd.quit()
关闭所有标签/窗口
sd.refresh()
刷新页面操作
sd.back()
回退到之前的页面
sd.forward()
前进到之后的页面
sd.get_screenshot_as_file(‘gpj.jpg’)
把结果截图保存下来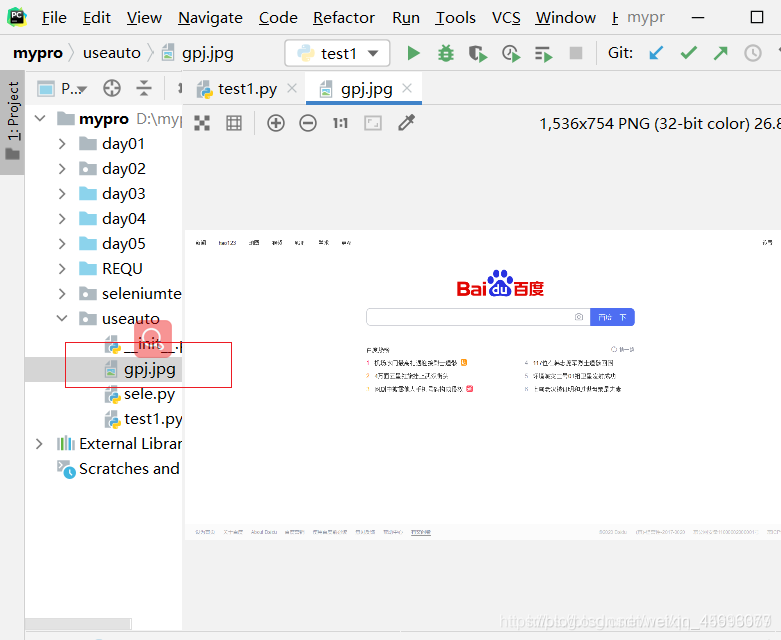
print(sd.current_url)
获取当前访问页面url
print(sd.title)
获取当前浏览器标题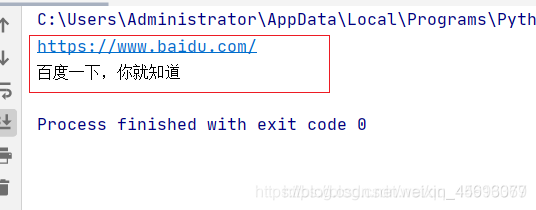
print(sd.page_source)
查看网页源码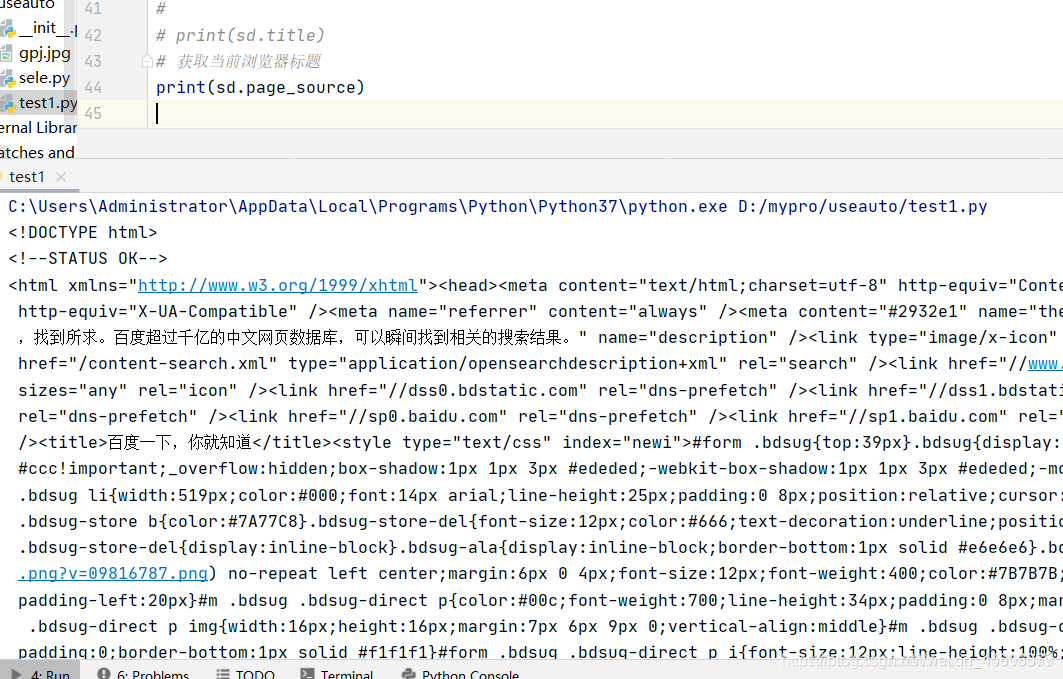
selenium 页面定位元素的八大方法
八种定位方式的示例:
1. driver.find_element_by_xpath(value)
2. driver.find_element_by_css_selector(value)
3. driver.find_element_by_id(value)
4. driver.find_element_by_name(value)
5. driver.find_element_by_class_name(value)
6. driver.find_element_by_tag_name(value)
7. driver.find_element_by_link_text(value)
8. driver.find_element_by_partial_link_text(value)`