模板引擎是将数据要变为视图最优雅的解决方案,数据和视图的概念如图所示
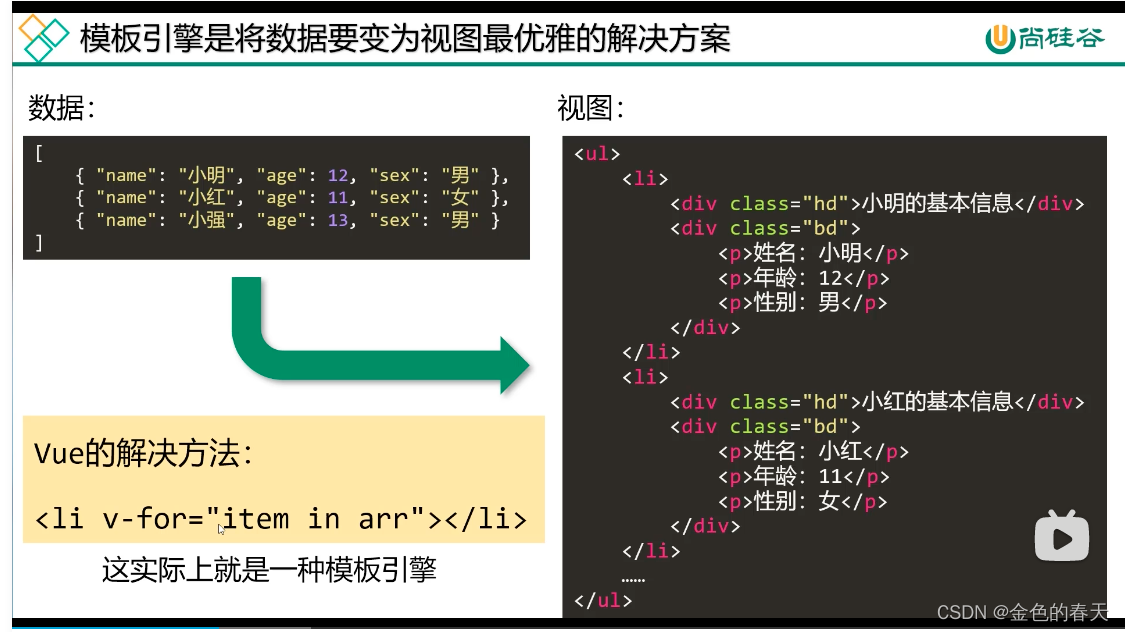
v-for是一种模板引擎,mustache也是一种模板引擎。v-for的底层实现会用到抽象语法树和模板解析的原理。
历史上曾经出现过的数据变为视图的方法,

开篇案例如果用mustache实现的话,大概是这样的:
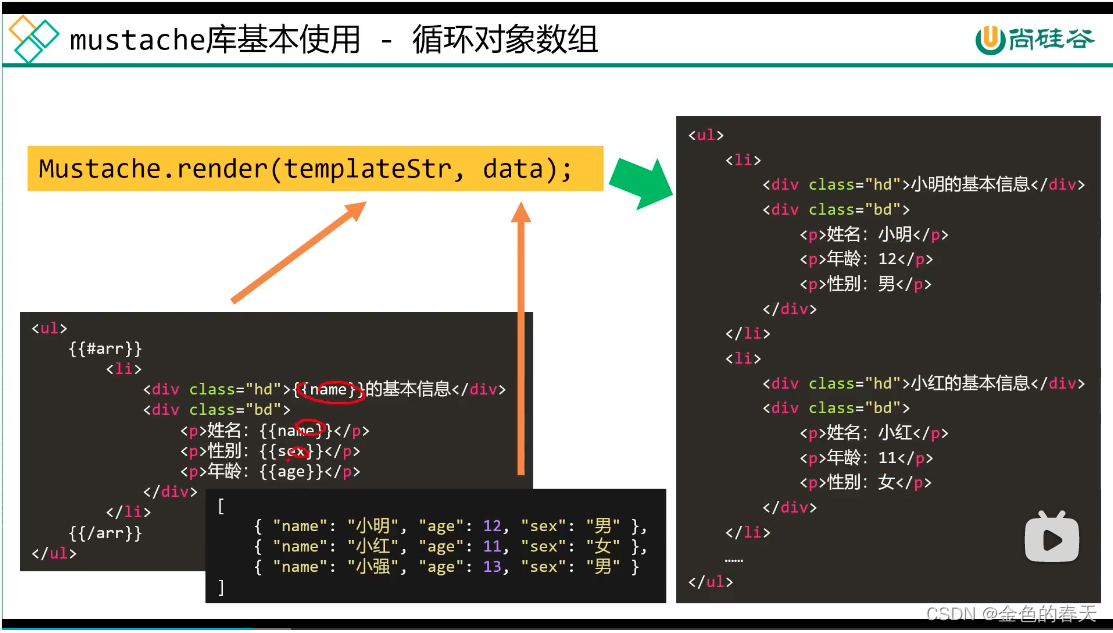
此处插入两段代码,分别是mustache的库,和mustahce的demo,大家可以作为基准模板,用来使用mustache。
mustache.js,一个文件夹下新建一个js文件,cp即可
// This file has been generated from mustache.mjs
(function (global, factory) {
typeof exports === 'object' && typeof module !== 'undefined' ? module.exports = factory() :
typeof define === 'function' && define.amd ? define(factory) :
(global = global || self, global.Mustache = factory());
}(this, (function () { 'use strict';
/*!
* mustache.js - Logic-less {{mustache}} templates with JavaScript
* http://github.com/janl/mustache.js
*/
var objectToString = Object.prototype.toString;
var isArray = Array.isArray || function isArrayPolyfill (object) {
return objectToString.call(object) === '[object Array]';
};
function isFunction (object) {
return typeof object === 'function';
}
/**
* More correct typeof string handling array
* which normally returns typeof 'object'
*/
function typeStr (obj) {
return isArray(obj) ? 'array' : typeof obj;
}
function escapeRegExp (string) {
return string.replace(/[\-\[\]{}()*+?.,\\\^$|#\s]/g, '\\$&');
}
/**
* Null safe way of checking whether or not an object,
* including its prototype, has a given property
*/
function hasProperty (obj, propName) {
return obj != null && typeof obj === 'object' && (propName in obj);
}
/**
* Safe way of detecting whether or not the given thing is a primitive and
* whether it has the given property
*/
function primitiveHasOwnProperty (primitive, propName) {
return (
primitive != null
&& typeof primitive !== 'object'
&& primitive.hasOwnProperty
&& primitive.hasOwnProperty(propName)
);
}
// Workaround for https://issues.apache.org/jira/browse/COUCHDB-577
// See https://github.com/janl/mustache.js/issues/189
var regExpTest = RegExp.prototype.test;
function testRegExp (re, string) {
return regExpTest.call(re, string);
}
var nonSpaceRe = /\S/;
function isWhitespace (string) {
return !testRegExp(nonSpaceRe, string);
}
var entityMap = {
'&': '&',
'<': '<',
'>': '>',
'"': '"',
"'": ''',
'/': '/',
'`': '`',
'=': '='
};
function escapeHtml (string) {
return String(string).replace(/[&<>"'`=\/]/g, function fromEntityMap (s) {
return entityMap[s];
});
}
var whiteRe = /\s*/;
var spaceRe = /\s+/;
var equalsRe = /\s*=/;
var curlyRe = /\s*\}/;
var tagRe = /#|\^|\/|>|\{|&|=|!/;
/**
* Breaks up the given `template` string into a tree of tokens. If the `tags`
* argument is given here it must be an array with two string values: the
* opening and closing tags used in the template (e.g. [ "<%", "%>" ]). Of
* course, the default is to use mustaches (i.e. mustache.tags).
*
* A token is an array with at least 4 elements. The first element is the
* mustache symbol that was used inside the tag, e.g. "#" or "&". If the tag
* did not contain a symbol (i.e. {{myValue}}) this element is "name". For
* all text that appears outside a symbol this element is "text".
*
* The second element of a token is its "value". For mustache tags this is
* whatever else was inside the tag besides the opening symbol. For text tokens
* this is the text itself.
*
* The third and fourth elements of the token are the start and end indices,
* respectively, of the token in the original template.
*
* Tokens that are the root node of a subtree contain two more elements: 1) an
* array of tokens in the subtree and 2) the index in the original template at
* which the closing tag for that section begins.
*
* Tokens for partials also contain two more elements: 1) a string value of
* indendation prior to that tag and 2) the index of that tag on that line -
* eg a value of 2 indicates the partial is the third tag on this line.
*/
function parseTemplate (template, tags) {
if (!template)
return [];
var lineHasNonSpace = false;
var sections = []; // Stack to hold section tokens
var tokens = []; // Buffer to hold the tokens
var spaces = []; // Indices of whitespace tokens on the current line
var hasTag = false; // Is there a {{tag}} on the current line?
var nonSpace = false; // Is there a non-space char on the current line?
var indentation = ''; // Tracks indentation for tags that use it
var tagIndex = 0; // Stores a count of number of tags encountered on a line
// Strips all whitespace tokens array for the current line
// if there was a {{#tag}} on it and otherwise only space.
function stripSpace () {
if (hasTag && !nonSpace) {
while (spaces.length)
delete tokens[spaces.pop()];
} else {
spaces = [];
}
hasTag = false;
nonSpace = false;
}
var openingTagRe, closingTagRe, closingCurlyRe;
function compileTags (tagsToCompile) {
if (typeof tagsToCompile === 'string')
tagsToCompile = tagsToCompile.split(spaceRe, 2);
if (!isArray(tagsToCompile) || tagsToCompile.length !== 2)
throw new Error('Invalid tags: ' + tagsToCompile);
openingTagRe = new RegExp(escapeRegExp(tagsToCompile[0]) + '\\s*');
closingTagRe = new RegExp('\\s*' + escapeRegExp(tagsToCompile[1]));
closingCurlyRe = new RegExp('\\s*' + escapeRegExp('}' + tagsToCompile[1]));
}
compileTags(tags || mustache.tags);
var scanner = new Scanner(template);
var start, type, value, chr, token, openSection;
while (!scanner.eos()) {
start = scanner.pos;
// Match any text between tags.
value = scanner.scanUntil(openingTagRe);
if (value) {
for (var i = 0, valueLength = value.length; i < valueLength; ++i) {
chr = value.charAt(i);
if (isWhitespace(chr)) {
spaces.push(tokens.length);
indentation += chr;
} else {
nonSpace = true;
lineHasNonSpace = true;
indentation += ' ';
}
tokens.push([ 'text', chr, start, start + 1 ]);
start += 1;
// Check for whitespace on the current line.
if (chr === '\n') {
stripSpace();
indentation = '';
tagIndex = 0;
lineHasNonSpace = false;
}
}
}
// Match the opening tag.
if (!scanner.scan(openingTagRe))
break;
hasTag = true;
// Get the tag type.
type = scanner.scan(tagRe) || 'name';
scanner.scan(whiteRe);
// Get the tag value.
if (type === '=') {
value = scanner.scanUntil(equalsRe);
scanner.scan(equalsRe);
scanner.scanUntil(closingTagRe);
} else if (type === '{') {
value = scanner.scanUntil(closingCurlyRe);
scanner.scan(curlyRe);
scanner.scanUntil(closingTagRe);
type = '&';
} else {
value = scanner.scanUntil(closingTagRe);
}
// Match the closing tag.
if (!scanner.scan(closingTagRe))
throw new Error('Unclosed tag at ' + scanner.pos);
if (type == '>') {
token = [ type, value, start, scanner.pos, indentation, tagIndex, lineHasNonSpace ];
} else {
token = [ type, value, start, scanner.pos ];
}
tagIndex++;
tokens.push(token);
if (type === '#' || type === '^') {
sections.push(token);
} else if (type === '/') {
// Check section nesting.
openSection = sections.pop();
if (!openSection)
throw new Error('Unopened section "' + value + '" at ' + start);
if (openSection[1] !== value)
throw new Error('Unclosed section "' + openSection[1] + '" at ' + start);
} else if (type === 'name' || type === '{' || type === '&') {
nonSpace = true;
} else if (type === '=') {
// Set the tags for the next time around.
compileTags(value);
}
}
stripSpace();
// Make sure there are no open sections when we're done.
openSection = sections.pop();
if (openSection)
throw new Error('Unclosed section "' + openSection[1] + '" at ' + scanner.pos);
return nestTokens(squashTokens(tokens));
}
/**
* Combines the values of consecutive text tokens in the given `tokens` array
* to a single token.
*/
function squashTokens (tokens) {
var squashedTokens = [];
var token, lastToken;
for (var i = 0, numTokens = tokens.length; i < numTokens; ++i) {
token = tokens[i];
if (token) {
if (token[0] === 'text' && lastToken && lastToken[0] === 'text') {
lastToken[1] += token[1];
lastToken[3] = token[3];
} else {
squashedTokens.push(token);
lastToken = token;
}
}
}
return squashedTokens;
}
/**
* Forms the given array of `tokens` into a nested tree structure where
* tokens that represent a section have two additional items: 1) an array of
* all tokens that appear in that section and 2) the index in the original
* template that represents the end of that section.
*/
function nestTokens (tokens) {
var nestedTokens = [];
var collector = nestedTokens;
var sections = [];
var token, section;
for (var i = 0, numTokens = tokens.length; i < numTokens; ++i) {
token = tokens[i];
switch (token[0]) {
case '#':
case '^':
collector.push(token);
sections.push(token);
collector = token[4] = [];
break;
case '/':
section = sections.pop();
section[5] = token[2];
collector = sections.length > 0 ? sections[sections.length - 1][4] : nestedTokens;
break;
default:
collector.push(token);
}
}
return nestedTokens;
}
/**
* A simple string scanner that is used by the template parser to find
* tokens in template strings.
*/
function Scanner (string) {
this.string = string;
this.tail = string;
this.pos = 0;
}
/**
* Returns `true` if the tail is empty (end of string).
*/
Scanner.prototype.eos = function eos () {
return this.tail === '';
};
/**
* Tries to match the given regular expression at the current position.
* Returns the matched text if it can match, the empty string otherwise.
*/
Scanner.prototype.scan = function scan (re) {
var match = this.tail.match(re);
if (!match || match.index !== 0)
return '';
var string = match[0];
this.tail = this.tail.substring(string.length);
this.pos += string.length;
return string;
};
/**
* Skips all text until the given regular expression can be matched. Returns
* the skipped string, which is the entire tail if no match can be made.
*/
Scanner.prototype.scanUntil = function scanUntil (re) {
var index = this.tail.search(re), match;
switch (index) {
case -1:
match = this.tail;
this.tail = '';
break;
case 0:
match = '';
break;
default:
match = this.tail.substring(0, index);
this.tail = this.tail.substring(index);
}
this.pos += match.length;
return match;
};
/**
* Represents a rendering context by wrapping a view object and
* maintaining a reference to the parent context.
*/
function Context (view, parentContext) {
this.view = view;
this.cache = { '.': this.view };
this.parent = parentContext;
}
/**
* Creates a new context using the given view with this context
* as the parent.
*/
Context.prototype.push = function push (view) {
return new Context(view, this);
};
/**
* Returns the value of the given name in this context, traversing
* up the context hierarchy if the value is absent in this context's view.
*/
Context.prototype.lookup = function lookup (name) {
var cache = this.cache;
var value;
if (cache.hasOwnProperty(name)) {
value = cache[name];
} else {
var context = this, intermediateValue, names, index, lookupHit = false;
while (context) {
if (name.indexOf('.') > 0) {
intermediateValue = context.view;
names = name.split('.');
index = 0;
/**
* Using the dot notion path in `name`, we descend through the
* nested objects.
*
* To be certain that the lookup has been successful, we have to
* check if the last object in the path actually has the property
* we are looking for. We store the result in `lookupHit`.
*
* This is specially necessary for when the value has been set to
* `undefined` and we want to avoid looking up parent contexts.
*
* In the case where dot notation is used, we consider the lookup
* to be successful even if the last "object" in the path is
* not actually an object but a primitive (e.g., a string, or an
* integer), because it is sometimes useful to access a property
* of an autoboxed primitive, such as the length of a string.
**/
while (intermediateValue != null && index < names.length) {
if (index === names.length - 1)
lookupHit = (
hasProperty(intermediateValue, names[index])
|| primitiveHasOwnProperty(intermediateValue, names[index])
);
intermediateValue = intermediateValue[names[index++]];
}
} else {
intermediateValue = context.view[name];
/**
* Only checking against `hasProperty`, which always returns `false` if
* `context.view` is not an object. Deliberately omitting the check
* against `primitiveHasOwnProperty` if dot notation is not used.
*
* Consider this example:
* ```
* Mustache.render("The length of a football field is {{#length}}{{length}}{{/length}}.", {length: "100 yards"})
* ```
*
* If we were to check also against `primitiveHasOwnProperty`, as we do
* in the dot notation case, then render call would return:
*
* "The length of a football field is 9."
*
* rather than the expected:
*
* "The length of a football field is 100 yards."
**/
lookupHit = hasProperty(context.view, name);
}
if (lookupHit) {
value = intermediateValue;
break;
}
context = context.parent;
}
cache[name] = value;
}
if (isFunction(value))
value = value.call(this.view);
return value;
};
/**
* A Writer knows how to take a stream of tokens and render them to a
* string, given a context. It also maintains a cache of templates to
* avoid the need to parse the same template twice.
*/
function Writer () {
this.templateCache = {
_cache: {},
set: function set (key, value) {
this._cache[key] = value;
},
get: function get (key) {
return this._cache[key];
},
clear: function clear () {
this._cache = {};
}
};
}
/**
* Clears all cached templates in this writer.
*/
Writer.prototype.clearCache = function clearCache () {
if (typeof this.templateCache !== 'undefined') {
this.templateCache.clear();
}
};
/**
* Parses and caches the given `template` according to the given `tags` or
* `mustache.tags` if `tags` is omitted, and returns the array of tokens
* that is generated from the parse.
*/
Writer.prototype.parse = function parse (template, tags) {
var cache = this.templateCache;
var cacheKey = template + ':' + (tags || mustache.tags).join(':');
var isCacheEnabled = typeof cache !== 'undefined';
var tokens = isCacheEnabled ? cache.get(cacheKey) : undefined;
if (tokens == undefined) {
tokens = parseTemplate(template, tags);
isCacheEnabled && cache.set(cacheKey, tokens);
}
return tokens;
};
/**
* High-level method that is used to render the given `template` with
* the given `view`.
*
* The optional `partials` argument may be an object that contains the
* names and templates of partials that are used in the template. It may
* also be a function that is used to load partial templates on the fly
* that takes a single argument: the name of the partial.
*
* If the optional `tags` argument is given here it must be an array with two
* string values: the opening and closing tags used in the template (e.g.
* [ "<%", "%>" ]). The default is to mustache.tags.
*/
Writer.prototype.render = function render (template, view, partials, tags) {
var tokens = this.parse(template, tags);
var context = (view instanceof Context) ? view : new Context(view, undefined);
return this.renderTokens(tokens, context, partials, template, tags);
};
/**
* Low-level method that renders the given array of `tokens` using
* the given `context` and `partials`.
*
* Note: The `originalTemplate` is only ever used to extract the portion
* of the original template that was contained in a higher-order section.
* If the template doesn't use higher-order sections, this argument may
* be omitted.
*/
Writer.prototype.renderTokens = function renderTokens (tokens, context, partials, originalTemplate, tags) {
var buffer = '';
var token, symbol, value;
for (var i = 0, numTokens = tokens.length; i < numTokens; ++i) {
value = undefined;
token = tokens[i];
symbol = token[0];
if (symbol === '#') value = this.renderSection(token, context, partials, originalTemplate);
else if (symbol === '^') value = this.renderInverted(token, context, partials, originalTemplate);
else if (symbol === '>') value = this.renderPartial(token, context, partials, tags);
else if (symbol === '&') value = this.unescapedValue(token, context);
else if (symbol === 'name') value = this.escapedValue(token, context);
else if (symbol === 'text') value = this.rawValue(token);
if (value !== undefined)
buffer += value;
}
return buffer;
};
Writer.prototype.renderSection = function renderSection (token, context, partials, originalTemplate) {
var self = this;
var buffer = '';
var value = context.lookup(token[1]);
// This function is used to render an arbitrary template
// in the current context by higher-order sections.
function subRender (template) {
return self.render(template, context, partials);
}
if (!value) return;
if (isArray(value)) {
for (var j = 0, valueLength = value.length; j < valueLength; ++j) {
buffer += this.renderTokens(token[4], context.push(value[j]), partials, originalTemplate);
}
} else if (typeof value === 'object' || typeof value === 'string' || typeof value === 'number') {
buffer += this.renderTokens(token[4], context.push(value), partials, originalTemplate);
} else if (isFunction(value)) {
if (typeof originalTemplate !== 'string')
throw new Error('Cannot use higher-order sections without the original template');
// Extract the portion of the original template that the section contains.
value = value.call(context.view, originalTemplate.slice(token[3], token[5]), subRender);
if (value != null)
buffer += value;
} else {
buffer += this.renderTokens(token[4], context, partials, originalTemplate);
}
return buffer;
};
Writer.prototype.renderInverted = function renderInverted (token, context, partials, originalTemplate) {
var value = context.lookup(token[1]);
// Use JavaScript's definition of falsy. Include empty arrays.
// See https://github.com/janl/mustache.js/issues/186
if (!value || (isArray(value) && value.length === 0))
return this.renderTokens(token[4], context, partials, originalTemplate);
};
Writer.prototype.indentPartial = function indentPartial (partial, indentation, lineHasNonSpace) {
var filteredIndentation = indentation.replace(/[^ \t]/g, '');
var partialByNl = partial.split('\n');
for (var i = 0; i < partialByNl.length; i++) {
if (partialByNl[i].length && (i > 0 || !lineHasNonSpace)) {
partialByNl[i] = filteredIndentation + partialByNl[i];
}
}
return partialByNl.join('\n');
};
Writer.prototype.renderPartial = function renderPartial (token, context, partials, tags) {
if (!partials) return;
var value = isFunction(partials) ? partials(token[1]) : partials[token[1]];
if (value != null) {
var lineHasNonSpace = token[6];
var tagIndex = token[5];
var indentation = token[4];
var indentedValue = value;
if (tagIndex == 0 && indentation) {
indentedValue = this.indentPartial(value, indentation, lineHasNonSpace);
}
return this.renderTokens(this.parse(indentedValue, tags), context, partials, indentedValue, tags);
}
};
Writer.prototype.unescapedValue = function unescapedValue (token, context) {
var value = context.lookup(token[1]);
if (value != null)
return value;
};
Writer.prototype.escapedValue = function escapedValue (token, context) {
var value = context.lookup(token[1]);
if (value != null)
return mustache.escape(value);
};
Writer.prototype.rawValue = function rawValue (token) {
return token[1];
};
var mustache = {
name: 'mustache.js',
version: '4.0.1',
tags: [ '{{', '}}' ],
clearCache: undefined,
escape: undefined,
parse: undefined,
render: undefined,
Scanner: undefined,
Context: undefined,
Writer: undefined,
/**
* Allows a user to override the default caching strategy, by providing an
* object with set, get and clear methods. This can also be used to disable
* the cache by setting it to the literal `undefined`.
*/
set templateCache (cache) {
defaultWriter.templateCache = cache;
},
/**
* Gets the default or overridden caching object from the default writer.
*/
get templateCache () {
return defaultWriter.templateCache;
}
};
// All high-level mustache.* functions use this writer.
var defaultWriter = new Writer();
/**
* Clears all cached templates in the default writer.
*/
mustache.clearCache = function clearCache () {
return defaultWriter.clearCache();
};
/**
* Parses and caches the given template in the default writer and returns the
* array of tokens it contains. Doing this ahead of time avoids the need to
* parse templates on the fly as they are rendered.
*/
mustache.parse = function parse (template, tags) {
return defaultWriter.parse(template, tags);
};
/**
* Renders the `template` with the given `view` and `partials` using the
* default writer. If the optional `tags` argument is given here it must be an
* array with two string values: the opening and closing tags used in the
* template (e.g. [ "<%", "%>" ]). The default is to mustache.tags.
*/
mustache.render = function render (template, view, partials, tags) {
if (typeof template !== 'string') {
throw new TypeError('Invalid template! Template should be a "string" ' +
'but "' + typeStr(template) + '" was given as the first ' +
'argument for mustache#render(template, view, partials)');
}
return defaultWriter.render(template, view, partials, tags);
};
// Export the escaping function so that the user may override it.
// See https://github.com/janl/mustache.js/issues/244
mustache.escape = escapeHtml;
// Export these mainly for testing, but also for advanced usage.
mustache.Scanner = Scanner;
mustache.Context = Context;
mustache.Writer = Writer;
return mustache;
})));mustache_demo.html,和mustache.js同一文件夹下,新建html文件,cp即可
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>mustache_Demo</title>
</head>
<body>
<script src="mustache.js"></script>
<script>
var templateStr = `
<ul>
{{#arr}}
<li>
<div class="hd">{{name}}的基本信息</div>
<div class="bd">
<p>姓名:{{name}}</p>
<p>性别:{{sex}}</p>
<p>年龄:{{age}}</p>
</div>
</li>
{{/arr}}
</ul>
`;
var data = {
arr:[
{"name":"小明","age":12,"sex":"男"},
{"name":"小红","age":11,"sex":"女"},
{"name":"小强","age":13,"sex":"男"}
]
};
var domStr = Mustache.render(templateStr,data);
console.log(domStr);
</script>
</body>
</html>运行结果:

我们可以用docment.inner方法把这个ul给追加到html中,这个不是这次文章的重点,有需要的同学,可以在评论区留言。
我在这里一开始有误解,我以为它只能生成html中的内容,但是实际不然,我们删掉模板中的所有标签,保留循环,我们依然可以按照自己想要的排版进行实现代码。比如像下图一样,把div标签、li标签全部删掉,效果就是下下图:
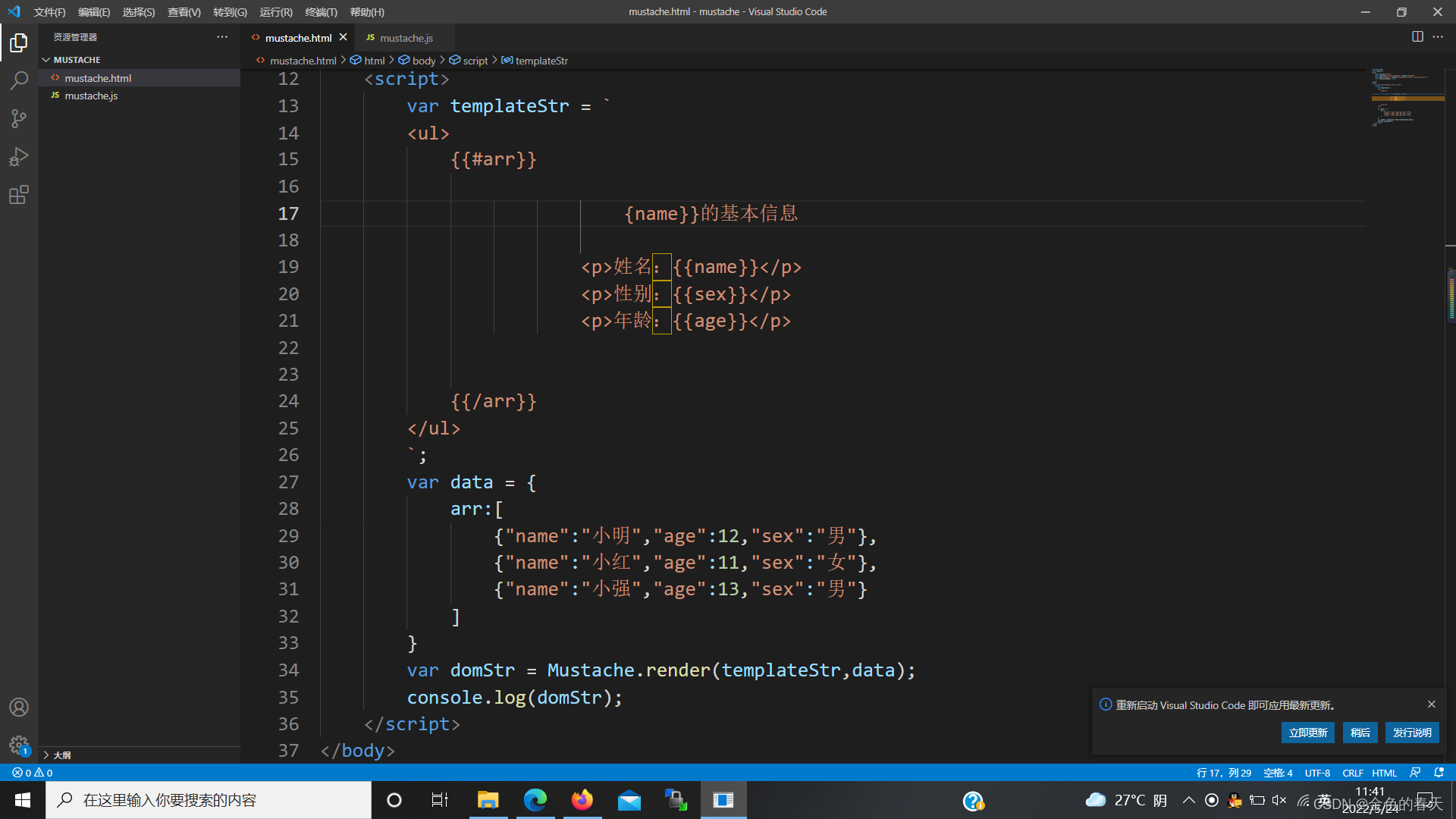

因此,我们可以用mustache把数据填充到任意样式的模板中
到此为止,我们就可以用mustache来完成需要模板化完成的事情了。
版权声明:本文为weixin_58633569原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。