摘要:
本文提出设计一个更复杂但实用的退化模型,包括随机打乱模糊、下采样和噪声退化。
- 具体来说,模糊用两个各向同性和各向异性高斯核卷积逼近;
- 下采样是从最近插值、双线性插值和双三次插值中随机选取;
- 通过添加不同噪声水平的高斯噪声,采用不同质量因子的JPEG压缩,通过反向正向的摄像机图像信号处理(ISP)管道模型和RAW图像噪声模型生成处理后的摄像机传感器噪声。
为了验证新的退化模型的有效性,训练了一个深盲ESRGAN超级解析器,然后将其应用于具有不同退化的合成图像和真实图像的超分辨。结果表明,该退化模型可显著提高深度超解析器的实用性,为实际应用提供了一种强有力的替代方案。
1、introduction
基于dnns的SISR方法可以大致分为非盲方法和盲方法,这取决于这些因素是否事先已知。
挑战:
(1)为真实图像设计一个更实用的SISR退化模型;
(2)学习一个有效的深度盲模型,它可以很好地适用于大多数真实图像。
解决办法:
(1)对于第一个挑战,我们认为模糊、降采样和噪声是导致真实图像退化的三个关键因素。具体来说,模糊是通过各向同性高斯核和各向异性高斯核的两次卷积实现的;下采样更一般,但包括常用的降尺度算子,如双线性和双三次插值;噪声采用不同噪声水平的AWGN模型,JPEG压缩噪声采用不同质量因子的压缩噪声,并应用反向摄像机图像信号处理(ISP)管道模型和RAW图像噪声模型对摄像机传感器噪声进行处理。此外,执行随机打乱的退化来合成LR图像。因此,我们的新退化模型包含了多个可调参数,旨在覆盖真实图像的退化空间。
(2)对于第二个挑战,我们以端到端监督的方式训练基于新降级模型的深度模型。对于一幅图像,我们可以通过设置不同的退化模型参数来合成不同的逼真的LR图像。因此,可以为训练生成无限数量的配对LR/HR训练数据。
2、Related Work
本文的重点是设计一个实用的退化模型来训练一个深度盲DNN模型。
(1)退化模型
- 现有的复杂SISR退化模型通常由模糊、下采样和噪声添加三个部分组成;
当涉及到真实图像退化的复杂性时,现有的退化模型是不足的;
使用训练数据来学习lr - hr映射,这只适用于由训练图像定义的退化。
(2)深盲SISR方法
盲SISR方法主要用于实际的SISR应用程序;
第一个方向是对给定的LR图像初始估计退化参数,然后应用非盲方法获得HR结果。例如先通过一种内部algan方法估计模糊核。然而,非盲SISR方法通常对模糊核中的错误很敏感,会产生过于尖锐或过于平滑的结果;
第二个方向是联合估计模糊核和HR图像。但由于没有充分考虑到噪声的影响,导致对有噪声的真实图像的核估计不准确。
第三个方向是学习具有捕获的真实LR/HR对的监督模型。然而,收集大量的对齐良好的训练数据是一件很麻烦的事情,并且学习的模型被限制在由捕获的LR图像定义的LR域。
第四个方向是使用未配对的训练数据进行学习。虽然将该方法应用于被更复杂退化破坏的数据的训练看似简单,但它也会降低模糊核和噪声估计的准确性,从而导致合成的LR图像不可靠。
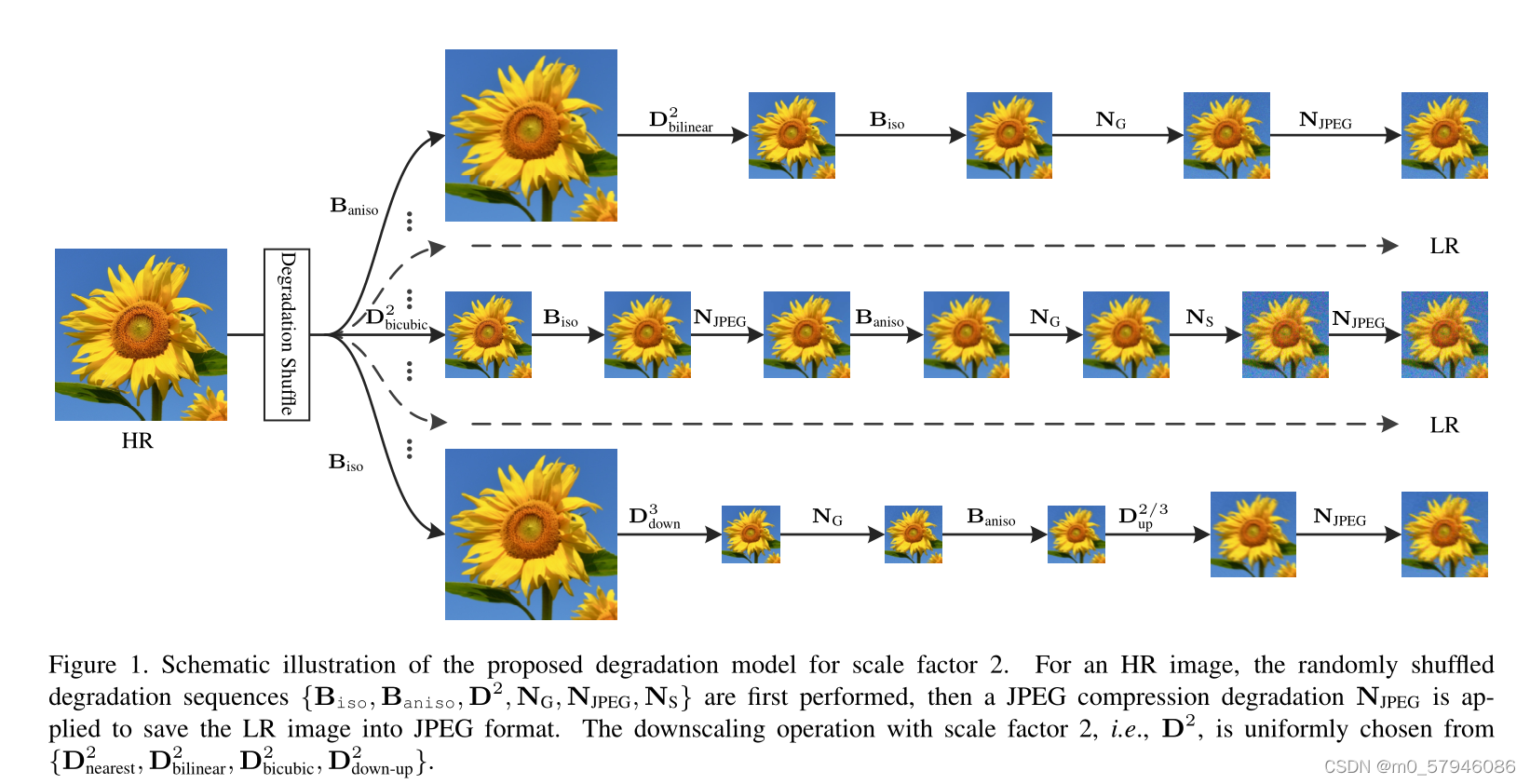
3、A Practical Degradation Model
以下几个方面的退化模型:blur, downsampling, noise, and random shuffle strategy.
(1)模糊
进行了两种高斯模糊操作,即各向同性高斯核的
和各向异性高斯核的
。
(2)下采样
最近邻插值。得到的LR图像将对左上角有0.5×(s−1)像素的不对齐。
二维线性网格插值方法。将中心21 × 21个各向同性高斯核平移0.5×(s−1)像素,并在最近邻下采样前进行卷积。高斯核宽度随机选取[0.1,0.6 × s]。我们把这样的下采样表示为
。
还采用了双三次和双线性下采样方法,分别用
和
表示;
一种向下采样方法向下采样
,该方法先用比例因子s/a向下采样,然后用比例因子a向上采样。这里的插值方法从双线性插值和双三次插值中随机选择,a从[1/2,s]中采样。
总结:上述四种下采样方法在HR空间中都有一个模糊步长,而当a小于1时,
会在LR空间中引入缩放诱导的模糊。这种模糊在下采样过程中是耦合的。我们对这四个下采样进行均匀抽样以缩小HR图像。
(3)噪声
高斯噪声
JPEG压缩噪声
- 经过处理的相机传感器噪声
(4)随机排列
- 对退化序列
进行随机洗牌,这里的
表示从
中随机选取尺度因子s的下采样操作。特别是,
的序列可以插入其他退化。
采用随机洗牌策略,可以大大扩展退化空间。
图1展示了所提出的退化模型。对于一个HR图像,我们可以通过变换退化操作和设置不同的退化参数来生成具有广泛退化范围的不同LR图像。
4、Discussion
- 首先,设计退化模型主要用于合成退化的LR图像。它最直接的应用是用配对的LR/HR图像训练深度盲超级解析器。特别是,退化模型可以在大量的HR图像数据集上执行,生成无限的完美对齐的训练图像,通常不会出现费力收集成对数据的有限数据问题和未成对训练数据的不对齐问题。
- 其次,退化模型由于涉及的退化参数过多,且采用了随机随机的洗牌策略,往往不适合建模退化的LR图像。
- 第三,退化模型可以产生一些在现实场景中很少发生的退化情况,但仍有望提高训练后的深度盲超级解析器的泛化能力。
- 第四,大容量的DNN能够通过单个模型处理不同的退化。值得注意的是,即使超级解析器降低了不现实的双三次下采样的性能,它仍然是真实SISR的首选。
- 第五,通过改变退化参数设置和添加更合理的退化类型(如散斑噪声和非对齐双JPEG压缩),可以方便地修改退化模型,提高对某些应用的实用性。
5. Deep Blind SISR Model Training
采用了广泛使用的ESRGAN网络,并利用新退化模型生成的合成LR/HR对图像对其进行训练。在ESRGAN基础上,首先训练一个面向psnr的BSRNet模型(由于像素平均问题而容易产生过平滑结果),然后训练面向感知质量的BSRGAN模型(更适合于实际应用)。
与ESRGAN相比,BSRGAN在几个方面进行了改进。
- 首先,使用一个稍微不同的HR图像数据集,其中包括DIV2K、Flick2K、WED和来自FFHQ的2000张人脸图像来捕获之前的图像。这是因为BSRGAN的目标是解决通用盲图像超分辨率问题,除退化先验外,图像先验也有助于超级解析器的成功。我们还根据图像拉普拉斯算子的方差来去除模糊图像。
- 其次,BSRGAN使用更大的LR-patch,大小为72 × 72。因为我们的退化模型可以产生严重退化的LR图像,更大的patch可以让深层模型捕获更多的信息以便更好的恢复。
- 第三,我们通过最小化L1损失、VGG感知损失和基于光谱范数的最小二乘PatchGAN损失的加权组合来训练BSRGAN,其权重分别为1、1和0.1。特别是,在经过训练的19层VGG模型中,VGG感知丧失是在第4层卷积之前进行的,而不是在第5层maxpooling层进行的,因为这样更稳定,可以防止颜色偏移问题。我们使用Adam训练BSRGAN,使用1 × 10−5的固定学习率和48个批量。
6. Experimental Results
实验结果
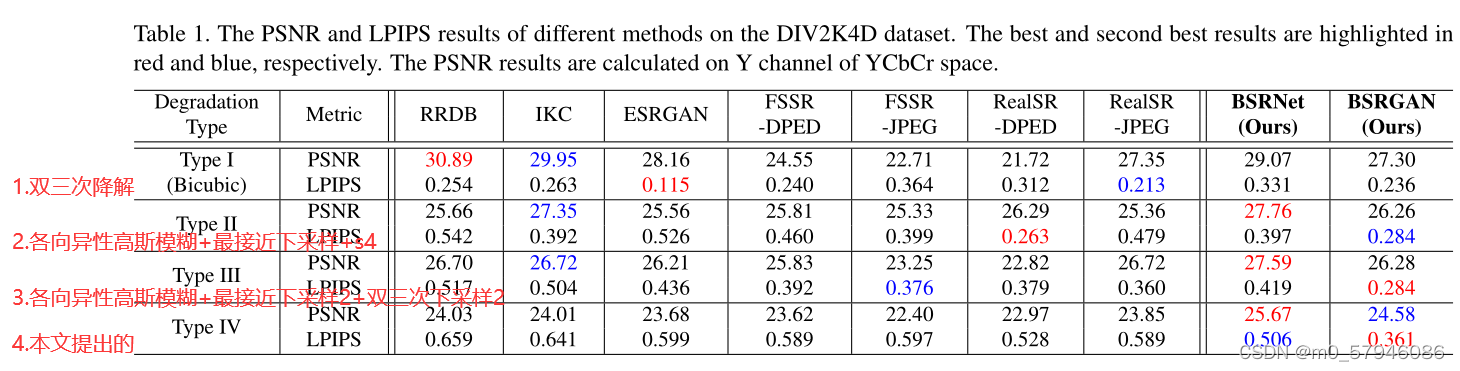
(1)不同方法在DIV2K4D数据集上的PSNR和LPIPS结果。最佳和次最佳结果。在YCbCr空间Y通道上计算PSNR结果
注:LPIPS(学习感知图像patch相似性),LPIPS用于测量感知质量,LPIPS值越低,表示超分辨图像在感知上更接近真相。)
首先,RRDB和ESRGAN在双三次降解方面表现良好,但在非双三次降解方面表现不佳,值得注意的是,即使使用GAN训练,ESRGAN在降解类型II-IV上也能比RRDB略微提高LPIPS值。
其次,FSSR-DPED、FSSR-JPEG、RealSR-DPED和RealSR-JPEG在LPIPS方面优于RRDB和ESRGAN,因为它们考虑了更实际的降级。
第三,对于降解类型II, IKC获得了很好的PSNR结果,而RealSR-DPED由于在相似的降解条件下进行训练,获得了最好的LPIPS结果。对于III和IV型降级,它们的性能会严重下降。
第四,我们提出的BSRNet获得了最佳的总体PSNR结果,而BSRGAN获得了最佳的总体LPIPS结果。
(2)基于比例因子4的DIV2K4D数据集超分辨LR图像的不同方法的结果。测试图像由我们提出的退化合成。
- 可以看出IKC和RealSR-JPEG无法去除噪声,无法恢复锐边。
- FSSR-JPEG可以生成清晰的图像,但也会引入一些工件。
- 与其他方法相比,我们的BSRNet和BSRGAN具有更好的视觉效果。
(3)不同方法在比例因子为4的RealSRSet超分辨真实图像上的结果。每一行从上到下的LR图像分别为“Building”、“Chip”和“Oldphoto2”。请放大以便看得清楚些。
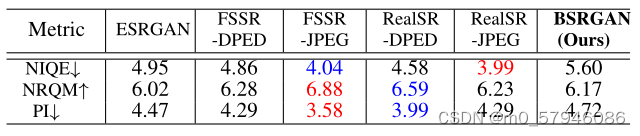
RealSRSet数据集上不同方法的NIQE(自然图像质量)、NRQM和PI结果。最佳和次最佳结果分别用红色和蓝色表示。请注意,所有方法都使用相同的网络体系结构。
- 从表可以看出,BSRGAN的结果并不理想。
- 图所示,BSRNet的视觉效果比其他方法要好得多。例如,BSRGAN可以去除“Building”的未知处理过的相机传感器噪声和“Oldphoto2”的未知复杂噪声,同时还可以产生尖锐的边缘和精细的细节。
- 相比之下,FSSR-JPEG、RealSR-DPED和RealSR-JPEG产生了一些高频的工件,但比BSRNet有更好的定量结果。这种不一致性表明,这些无参考的IQA度量并不总是与感知视觉质量[30]匹配,IQA度量可以用新的SISR方法[15]进行更新。
- 我们进一步认为,对于SISR的IQA度量也应该使用新的图像退化类型进行更新,这将留到未来的工作中。我们注意到,我们的BSRGAN倾向于在纹理区域产生“气泡”伪像,这可以通过新的丢失函数或更多不同纹理的训练数据来解决。


7. Conclusions
本文设计了一种新的退化模型来训练深度盲超分辨率模型。
具体来说,通过使每一个退化因素,如模糊、降采样和噪声,更复杂和实用,也通过引入随机洗牌策略,新的退化模型可以覆盖在现实场景中发现的广泛退化。基于新的退化模型生成的合成数据,我们训练了一个用于一般图像超分辨率的深度盲模型。在合成图像和真实图像数据集上的实验表明,深度盲模型对不同退化的图像具有良好的性能。