In Machine Learning, a hyperparameter is a parameter whose value is used to control the learning process.
在机器学习中, 超参数是一个参数,其值用于控制学习过程。
Hyperparameters can be classified as model hyperparameters, which cannot be inferred while fitting the machine to the training set because they refer to the model selection task, or algorithm hyperparameters, that in principle have no influence on the performance of the model but affect the speed and quality of the learning process. An example of a model hyperparameter is the topology and size of a neural network. Examples of algorithm hyperparameters are learning rate and mini-batch size.
可以将超参数归类为模型超参数,它们无法在将机器安装到训练集上时进行推断,因为它们是指模型选择任务或算法超参数,它们原则上不会影响模型的性能,但会影响速度和学习过程的质量。 模型超参数的一个示例是神经网络的拓扑和大小。 算法超参数的示例是学习率和小批量大小。
Different model training algorithms require different hyperparameters, some simple algorithms (such as ordinary least squares regression) require none. Given these hyperparameters, the training algorithm learns the parameters from the data. For instance, LASSO is an algorithm that adds a regularization hyperparameter to ordinary least squares regression, which has to be set before estimating the parameters through the training algorithm.
不同的模型训练算法需要不同的超参数,一些简单的算法(例如普通最小二乘回归)则不需要。 给定这些超参数,训练算法会从数据中学习参数。 例如,LASSO是一种将常规化超参数添加到普通最小二乘回归的算法,必须在通过训练算法估算参数之前进行设置。
A model hyperparameter is a configuration that is external to the model and whose value cannot be estimated from data.
模型超参数是模型外部的配置,无法从数据中估计其值。
- They are often used in processes to help estimate model parameters.它们通常用于流程中以帮助估计模型参数。
- They are often specified by the practitioner.它们通常由从业者指定。
- They can often be set using heuristics.通常可以使用试探法来设置它们。
- They are often tuned for a given predictive modeling problem.它们通常针对给定的预测建模问题进行调整。
We cannot know the best value for a model hyperparameter on a given problem. We may use rules of thumb, copy values used on other problems, or search for the best value by trial and error.
我们无法确定给定问题上模型超参数的最佳值。 我们可能会使用经验法则,复制在其他问题上使用的值,或者通过反复试验寻找最佳值。
When a machine learning algorithm is tuned for a specific problem, such as when you are using a grid search or a random search, then you are tuning the hyperparameters of the model or order to discover the parameters of the model that result in the most skilful predictions.
当针对特定问题调整了机器学习算法时(例如,当您使用网格搜索或随机搜索时),则您正在调整模型的超参数或为了发现导致最熟练的模型参数而进行调整。预测。
Here we are going to use popular Iris flower dataset. So let’s import our dataset.
在这里,我们将使用流行的鸢尾花数据集。 因此,让我们导入数据集。
Let’s take our first glance on out data.
让我们首先看一下数据。
Before optimizing hyperparameters let’s import and train our model and see how much is the score.
在优化超参数之前,让我们导入和训练我们的模型,看看分数是多少。
The results are really nice but this won’t be the case for every dataset.
结果确实很好,但并非每个数据集都如此。
超参数调整 (Hyperparameter tuning)
In this blog we are going to tune 3 hyperparameters kernel, C and gamma.
在此博客中,我们将调整3个超参数内核C和gamma 。
核心 (Kernel)
kernel: {‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’}, default=’rbf’
内核: {'linear','poly','rbf','sigmoid','precomputed'},默认='rbf'
Linear Kernel:
线性内核:
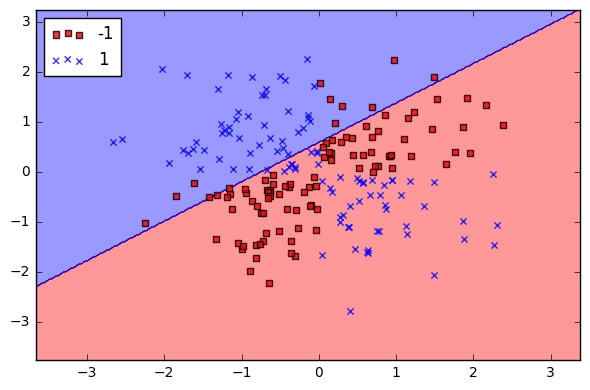
The most basic way to use a SVC is with a linear kernel, which means the decision boundary is a straight line (or hyperplane in higher dimensions). Linear kernels are rarely used in practice, however I wanted to show it here since it is the most basic version of SVC. As can been seen below, it is not very good at classifying because the data is not linear.
使用SVC的最基本方法是使用线性核,这意味着决策边界是一条直线(或更高维的超平面)。 线性内核实际上很少使用,但是我想在这里展示它,因为它是SVC的最基本版本。 如下所示,由于数据不是线性的,因此分类不是很好。
RBF Kernel:
RBF内核:
Radial Basis Function is a commonly used kernel in SVC:
径向基函数是SVC中常用的内核:
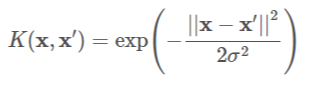
where ||x−x′||2||x−x′||2 is the squared Euclidean distance between two data points xx and x′x′. If this doesn’t make sense, Sebastian’s book has a full description. However, for this tutorial, it is only important to know that an SVC classifier using an RBF kernel has two parameters: gamma and C.
其中|| x-x'|| 2 || x-x'|| 2是两个数据点xx和x'x'之间的平方欧几里德距离。 如果这没有道理,则塞巴斯蒂安的书有完整的描述。 但是,对于本教程而言,重要的是要知道使用RBF内核的SVC分类器具有两个参数: gamma和C
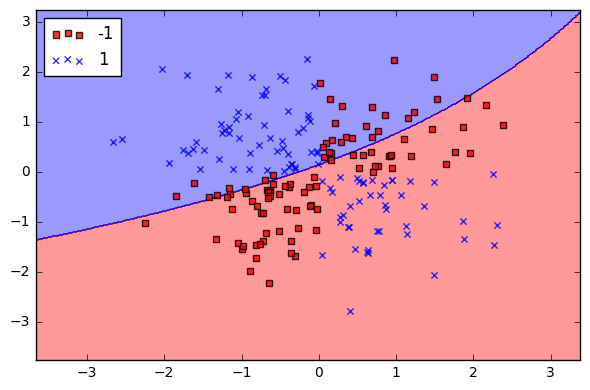
伽玛 (Gamma)
Gamma is a parameter of the RBF kernel and can be thought of as the ‘spread’ of the kernel and therefore the decision region. When gamma is low, the ‘curve’ of the decision boundary is very low and thus the decision region is very broad. When gamma is high, the ‘curve’ of the decision boundary is high, which creates islands of decision-boundaries around data points. We will see this very clearly below.
Gamma是RBF内核的参数,可以被认为是内核的“扩展”,因此可以看作决策区域。 当伽玛值较低时,决策边界的“曲线”非常低,因此决策区域非常宽。 当伽玛高时,决策边界的“曲线”就高,这会在数据点周围创建决策边界的孤岛。 我们将在下面非常清楚地看到这一点。
C (C)
C is a parameter of the SVC learner and is the penalty for misclassifying a data point. When C is small, the classifier is okay with misclassified data points (high bias, low variance). When C is large, the classifier is heavily penalized for misclassified data and therefore bends over backwards avoid any misclassified data points (low bias, high variance).
C是SVC学习者的参数,并且是错误分类数据点的代价。 当C小时,分类器可以处理分类错误的数据点(高偏差,低方差)。 当C大时,分类器会因错误分类的数据而受到严重惩罚,因此向后弯曲会避免任何错误分类的数据点(低偏差,高方差)。
Let’s try different parameters and calculate Cross-Validation Score.
让我们尝试不同的参数并计算交叉验证得分。
First: Kernel → Linear ; C → 10 ; Gamma → auto.
首先:内核→线性; C→10; 伽玛→自动。
Second: Kernel → RBF ; C → 10 ; Gamma → auto.
第二个:内核→RBF; C→10; 伽玛→自动。
Third: Kernel → RBF ; C → 20 ; Gamma → auto.
第三位:内核→RBF; C→20; 伽玛→自动。
If you take mean of all the scores, I think the first one did good from all of them. To check the score of each and every hyperparameter like this will take us a long time. Let’s do this same exact thing in a loop.
如果您将所有分数都作为平均值,我认为第一个分数对所有分数都有好处。 要像这样检查每个超参数的分数,将花费我们很长时间。 让我们循环执行相同的操作。
From above results we can say that rbf with C=1 or 10 or linear with C=1 will give best performance.
根据以上结果,我们可以说C = 1或10的rbf或C = 1的线性的rbf将提供最佳性能。
GridSearchCV (GridSearchCV)
GridSearchCV does exactly same thing as for loop above but in a single line of code.
GridSearchCV与上面的for循环完全相同,但仅用一行代码即可。
This output is so much to take in. But we can convert this data into Pandas DataFrame. Let’s see how
该输出非常多。但是我们可以将这些数据转换为Pandas DataFrame。 让我们看看如何
We don’t want each and every information, we just want ‘param_C’, ’param_kernel’, ’mean_test_score’
我们不需要每一个信息,我们只需要'param_C','param_kernel','mean_test_score'
We can see out first 3 rows are performing best.
我们可以看到前三行的效果最佳。
GridSearchCV also gives many handy attributes to analyse our scores.
GridSearchCV还提供了许多方便的属性来分析我们的分数。
best_params_ gives the best parameter for our model.
best_params_为模型提供最佳参数。
best_score_ gives highest score.
best_score_给出最高分。
There are many attributes u can get it from this command.
您可以通过此命令获得许多属性。
随机搜索 (RandomizedSearchCV)
Use RandomizedSearchCV to reduce number of iterations and with random combination of parameters. This is useful when you have too many parameters to try and your training time is longer. It helps reduce the cost of computation.
使用RandomizedSearchCV减少迭代次数并使用参数的随机组合。 当您要尝试的参数太多并且训练时间较长时,这很有用。 它有助于降低计算成本。
You can access the full source code here or click this link.
您可以在此处访问完整的源代码,或单击此链接 。