177.第N高薪水查询方法(普通)-3
- 排名是数据库问题经典题目,可划分为三种场景
- 连续排名 1-2-3-4 不同薪水不同名
- 同薪,同名,排名不连续,1-2-2-4
- 同薪,同名,排名连续 ,1-2-2-3
- 本题实现第三种排名第N个结果,全局排名,不存在分组
思路1:单表排序 group order limit
想法是用group by 按薪水进行分组,在order by排序,加limit限制得到
需要注意
同薪,同名,不跳级的问题,解决方法是用group by 按薪水分组后再order by
取排名第N高意味着跳过N-1个薪水,无法直接使用limit N-1,所以需要在函数开头将N为N-1
不能直接使用limit N-1因为offset字段只能接受正整数,或单一变量,不能是表达式
CREATE DEFINER=`root`@`localhost` FUNCTION `testget1`(N int ) RETURNS int -- 作者可以不用写的这么详细 BEGIN set N = N-1; RETURN ( select salary from employees group by salary order by salary desc limit N,1 ); END
可以靠点击也可以靠 select getNthHigestSalary(10); 写出来引用
使用distinct 可以代替group by
思路2:子查询 where count
排名第N的薪水,说明前面有N-1个比其更高的薪水
N-1是指去重复的N-1,实际个数可能不止N-1
最后返回的薪水也应该去重复
由于每个薪水的where田间都要执行一遍子查询,导致效率低下
CREATE DEFINER=`root`@`localhost` FUNCTION `getNthHigestSalary2`( N int ) RETURNS int begin return ( select distinct salary from employees e where ( select count(distinct salary) from employees where salary >e.salary )=N-1 ); end -- 这样是能去重复,找到去除重复后排名,但是最坏情况是要对外循环的每个salary 进行遍历的其中的distinct 和where 可以用group having 代替
group by e1.salary having n-1 = (select count(distinct e2.salary) from employee e2 where e2.salary > e1.salary )
思路3:自连接 join on group having count
实现三个操作,去重,找到N排名,考虑N=1
两个表自连接,连接条件为,table1 salary 小于 table2 salary
以table1 salary 分组,统计表1中salary 分组后对应表2中salary 唯一个数,即去重
限定步骤2中having 计数个数为N-1,即实现表1中salary 排名为第N个
考虑N=1点特殊情况,因为N-1 =0 ,计数要求为0,此时不存在满足条件的纪录数,但仍然需要返回结果,所以连接用left join
如果仅查询薪水这一项值,那么不用left join 当然也是可以的,只需要把连接条件放宽至小于等于,同时查询个数设置为N即可,因为连接条件包含等号,所以一定不能为空,用join即可
无需考虑N<=0的情况,无实际意义
CREATE DEFINER=`root`@`localhost` FUNCTION `getNthHigestSalary3`(N int) RETURNS int BEGIN return ( select e1.salary from employees e1 join employees e2 on e1.salary <= e2.salary group by e1.salary having count(distinct e2.salary) = N ); END查询效率也是比较低下的
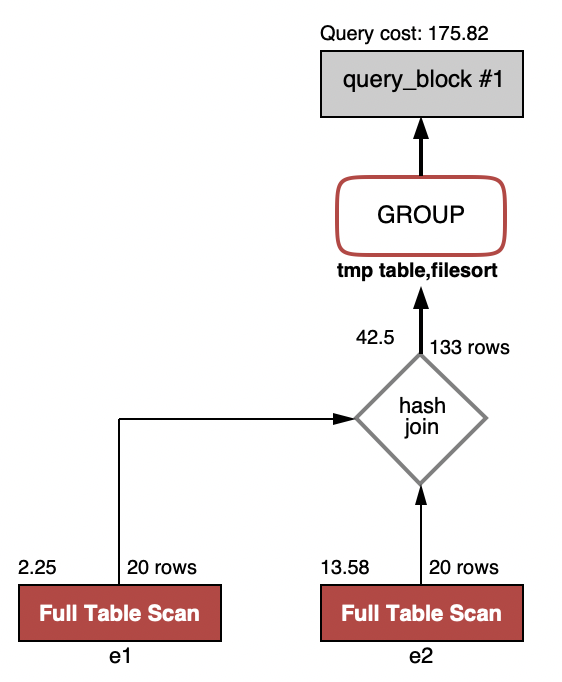
执行顺序是这样的,e1表和e2表各20行先进行join连接
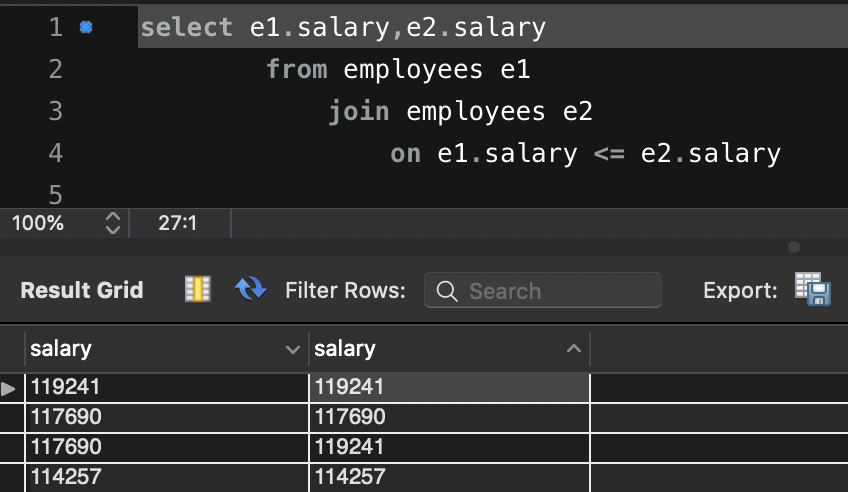
代码的思路显示进行join连接,表1的salary小于等于表2的salary,拿N=1作为例子举例,表2中没有salary会小于第一高的salary,有一个对应的表2元素只能是等于最高值,所以表2中只有一个,group by e1.salary having count(distinct e2.salary) = 1 ,count得出1的就是表1的最高salary
思路4:笛卡尔积 where group having
就是思路3的用where代替了join进行表连接
效率比使用思路3降低了
CREATE DEFINER=`root`@`localhost` FUNCTION `getNthHigestSalary4`(N int ) RETURNS int BEGIN return( select e1.salary from employees e1,employees e2 where e1.salary <= e2.salary group by e1.salary having count(distinct e2.salary) = N ); END
思路5:自定义变量 subQuery select @ order if
思路2到思路4都是两表关联的问题,当数据量比较大的时,速度就会变慢,表连接的时间复杂度大概是O(n2)量级,但是也要考虑到是否使用索引,下面算法也是O(N2)量级,但是会快很多,也与索引无关
自定义变量实现的按薪水降序后数据排名,同薪同名,不跳级,如2000排名第二,其他的2000也排名第二
对带有排名的临时表进行二次筛选,得到排名为N的薪水
因为薪水排名为N的纪录可能不止1个,用distinct去重
CREATE FUNCTION `getNthHigestSalary5` (N int) RETURNS INTEGER BEGIN return ( select distinct salary from ( select salary, @r:=if(@p = salary, @r,@r+1) as rnk, @p:= salary from employees, ( select @r:=0, @p:=NULL )init order by salary desc ) tmp where rnk = N ); END CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT BEGIN RETURN ( # Write your MySQL query statement below. -- 直接对salary 进行排序了,从前向后用变量计算,几乎每个salary都要计算一个排名 -- 主要特点是解决同分不同名问题,现在是同分同名 select distinct rank_tbl.salary from ( select salary, @r := if(salary = @compare ,@r,@r+1) as salary_rank, @compare := salary from (select @r := 0,@compare := null) as argument, employee order by salary desc )as rank_tbl where rank_tbl.salary_rank = N ); END -- 理清一次思路 -- 主要思想就是解决同分不同名的问题,通过 计数来确定排名,同分数 排名计数不增加 -- 对分数进行排序,设立两个变量,compare 用于比较下一个分数是否与上一个分数一样 -- 变量 r 用来统计 这个分数的排名,如果compare比较的分数相同,排名数量不增加,否则变量 r增加 -- 这样产生的salary 可能不会是唯一的,产生的salary 数值会相同排名也相同,确定是否是第N个时候要加上distinctIF(expr1,expr2,expr3) 如果 expr1 是TRUE (expr1 <> 0 and expr1 <> NULL),则 IF()的返回值为expr2; 否则返回值则为 expr3。IF() 的返回值为数字值或字符串值,具体情况视其所在语境而定。这个思路的关键点就在中间这一段
select salary, -- 这一列已经是被order by 排序好的 @r:=if(@p = salary, @r,@r+1) as rnk,-- 全查询只进行了一次初始化,之后的操作都是在进行叠加 @p:= salary -- 判断一次更新一次 from employees, (select @r:=0,@p:=NULL) as init -- 1,初始化 order by salary desc -- 2,直接进行了降序排序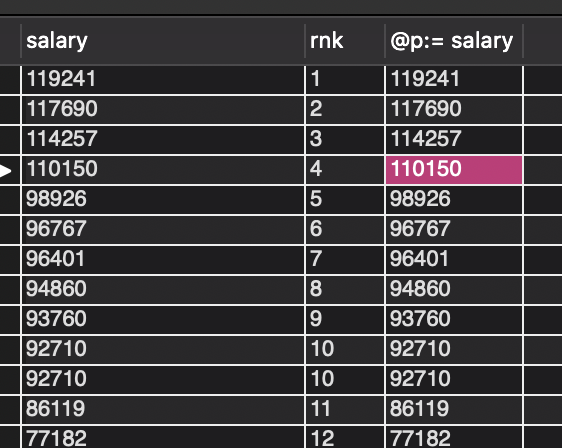
@r 初始化为0 ,if 进行判断@p 是否等于 salary,salary 此时已经被order by 排序好, 是降序的,第一个是119241,if 结果为false @r+1,@p = salary ,第一轮循环判断结束,第一列数据得出,salary :119241、@ r :1 、@p:119241,之后r会被不断叠加,当遇到相同的值时不会被叠加,像是第10名的情况,这样实现同薪,同排名
换了一种方法实现了去重的方法,效率就比第一种方法满2毫秒
思路6:窗口函数 dese_rank order

在mysql8.0中有几个相关的内置函数用来考虑各种排名问题
row_number() rank() desc_rank() 几个函数的官网描述
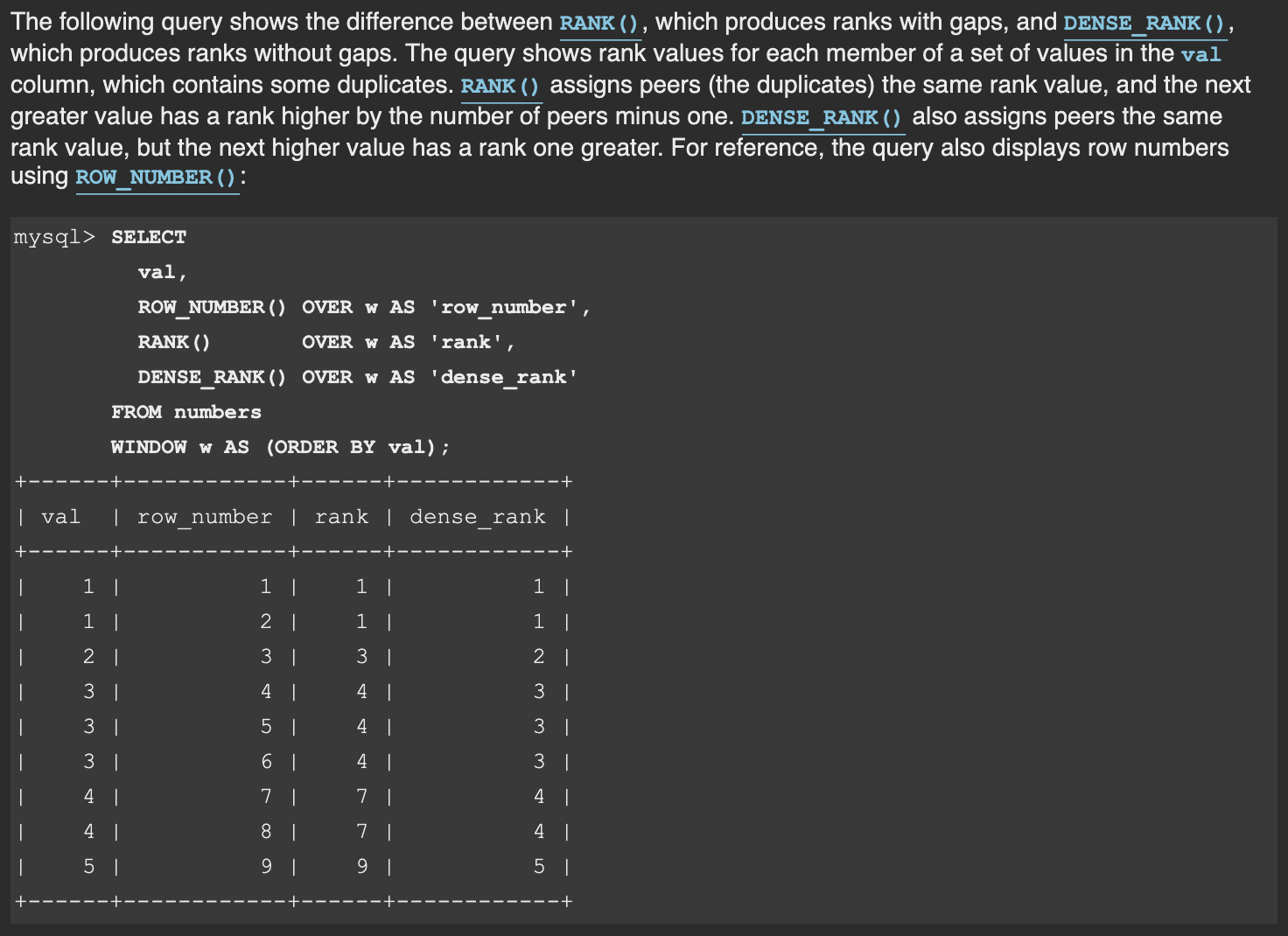
row_number():同值不同排名
rank():同值,有跳级
dense_rank() : 同值,不跳级
按照题意,使用第三个函数,这三个函数必须要搭档over(),配套使用,两个常见参数
- partition by ,按某字段切分
- order by 与常规order by 一样,asc 升序默认 和desc降序
CREATE FUNCTION `getNthHigestSalary6` (N int) RETURNS INTEGER BEGIN return ( select distinct salary from( select salary, dense_rank() over(order by salary desc) as rnk from employees )tmp where rnk = N ); END CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT BEGIN RETURN ( # Write your MySQL query statement below. select distinct tmp_tbl.salary from (select salary, dense_rank() over w as "salary_dense_rank" from employee window w as (order by salary desc) ) as tmp_tbl where tmp_tbl.salary_dense_rank = N ); END
总结
能用单表先用单表,即便使用order by 或 group by ,limit 都比多表效率高
不能用单表先用join 连接,小表驱动大表+建立合适索引+合理运用连接条件,基本上连接解决大部分问题,单join不宜多用,是接近指数级增涨的关联效果
能不用子查询,笛卡尔积尽量不要用,mysql优化器会将其优化成连接方式执行过程,单效率仍然难以保证
自定义变量在复杂sql实现中会很有用,
如果mysql版本允许,某些带有聚合功能的查询需求应用窗口函数是一个最优选择,经典的三种排序形式,还有聚合函数,向前向后取值,百分位等
将语句封装成自定义函数,能节省时间
优化自定义函数
- 定义变量接收返回值
- 执行查询条件,并赋值给相应变量
- 返回结果