本论文是 extractive summarization
- 摘要提取通常被定义为一个二分类问题,二分类问题表明这个句子是否在这个摘要中。
- 我们的提取模型是建立在这个编码器之上,通过堆叠几个句子间Transformer来捕获用于提取句子的文档级特征。
- 抽取结构使用encoder-decoder结构,将同一个经过预先训练的BERT编码器与随机初始化的Transformer结合起来。
- 我们设计了一个新的训练计划,将编码器和解码器的优化器分开,以适应前者是预先训练的事实。而后者必须从零开始接受培训
- 将extractive summarization 和 abstractive summarization结合起来能生成更好的摘要,我们提出了一个two-stage方法。encoder被微调两次,第一个次是匹配一个extractive objective 第二次是一个abstractive summarization。
贡献:
- 我们强调了文档编码对摘要任务的重要性,最近提出的各种技术旨在通过复制机制提高总结性能,增强学习,多通道编码器,我们没有用这些机制就达到了很好的效果。
- 我们展示了如何有效地使用预先训练的语言模型,在extractive和abstractive的环境下进行总结;
模型:Fine-tuning Bert for summarization
Summarization Encoder
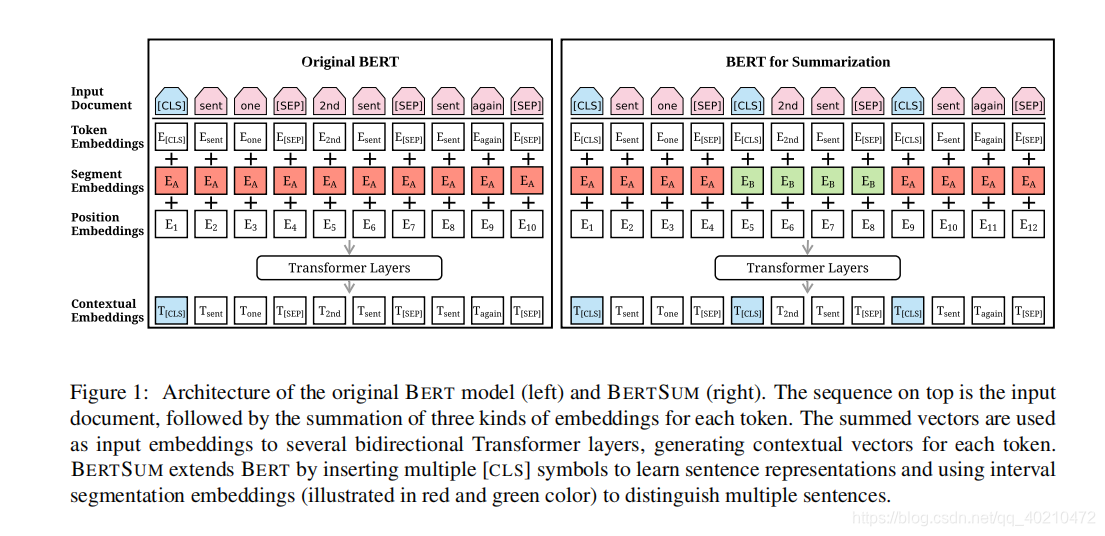
BERT SUM通过插入多个[CLS]符号来学习句子表示,并使用间隔分割嵌入(红色和绿色的插图)来区分多个句子。
在每个句子的开头插入一个额外的【cls】(原始的bert是在每一个input example的开头插入的)。我们还使用区间段嵌入来区分文档中的多个句子。对于Senti,我们分配段嵌入EA或EB取决于i是奇数还是偶数。(红色和绿色)
这样的的方法文档表示可以hierachically学习。低层的Transformer 层表示相邻的句子,而更高的层次,结合自我关注,代表了多句话语
原始BERT模型中的位置嵌入最大长度为512;我们克服了这一限制,增加了更多随机初始化的位置嵌入,并与其他编码器参数进行了微调。
3.2 extractive summarization
让d表示整个文档,则提取摘要可以定义为为每个senti分配一个标签yi偶{0,1}的任务,指示是否应该将句子包含在摘要中。
- 第i个[cls] (top layer )的向量ti是第i个句子的表示。然后,在BERT输出的顶部叠加几个句子间的Transformer层,以捕获用于提取摘要的文档级特征:
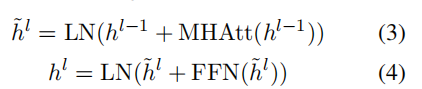
- 输出层是个二分类
- L=2时有最好的新能
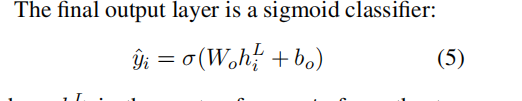
- 损失函数是二分类交叉熵损失函数
- 句子间Transformer层与BERTSUM联合微调
- 使用adam优化器
- 学习率使用了warmming-up的schedule
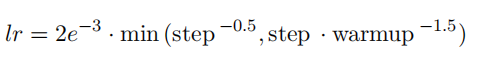
3.3 abstractive summarization
我们使用一个标准的encoder-decoder框架进行abstractive summarization。
- encoder : pretrained Bertsum
- decoder: 随机初始化的6layer transformer
可以想象,编码器和解码器之间存在不匹配,因为前者是预先训练的,而后者必须从零开始训练。这样会使得fine-tuning 不稳定。例如,当解码器不合适时,编码器可能会过度拟合数据,反之亦然
为了避免这种情况,我们设计了一种新的fine-tune计划,将编码器和解码器的优化器分开
- encoder: adam optimizer β1 = 0.9,lrE = 2e-3, and warmupE = 20, 000
- decoder: adam optimizer β2 = 0.999,lrD = 0.1, and warmupD =
10, 000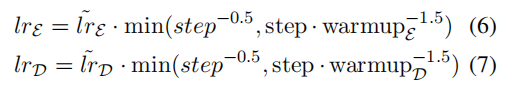
即预先训练的编码器应该以较小的学习速率和更平滑的衰减进行微调
当解码器变得稳定时,(这样编码器就可以用更精确的梯度进行训练)。
除此之外,引入了two-stage fine-tuning方法,我们首先在extractive summarizaiton任务上对encoder进行微调。使用extractive objective 可以促进abstracive summarization的性能。
这two-stage 在概念上是相似的,模型可以利用两个task之间的信息。
实验部分
extractive summarization
当预测一个新文档的摘要时,我们首先使用该模型来获得每个句子的分数。然后,我们根据这些句子的得分从最高到最低排列,然后选择前三名 作为总结。
- 在句子选择上使用了 trigram blocking 减少冗余
- 给定摘要S和候选句子c,如果c和S之间存在Trigram重叠,则跳过c。
- 意图与 maximal marginal relevance相似
- 我们希望尽量减少所考虑的句子和作为摘要一部分已经选定的句子之间的相似性。
abstractive summarization
- 在所有的abstractive summarization中,我们在所有线性层之前应用了dropout(概率0.1);还使用了平滑因子0.1的标签平滑(Szegedy等人,2016年)。
- 我们的Transformer decoder 有768个隐藏单元,所有前馈层的隐藏尺寸为2048。
- 在解码时我们使用beam search(size 5 )并调整α在0.6到1之间作为长度惩罚。我们解码,直到发出一个序列结束的标记,并且重复的语法被阻塞
版权声明:本文为qq_40210472原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。