\begin{figure}[htbp]
\begin{minipage}[b]{\linewidth} % 如果一行放2个图,用0.5,如果3个图,用0.33
\centering
\includegraphics[width = .7\textwidth]{1.png}
\caption{The C programing Language}
\label{fig:side:a}
\end{minipage}%
\end{figure}
\begin{figure}[htbp]
\begin{minipage}[b]{\linewidth} % 如果一行放2个图,用0.5,如果3个图,用0.33
\centering
\includegraphics[width=1in]{fig1.png}
\caption{The C programing Language}
\label{fig:side:a}
\end{minipage}%
\end{figure}
效果的图片是这样的
\begin{figure}[bhtp]
\begin{minipage}[b]{0.5\linewidth} % 如果一行放2个图,用0.5,如果3个图,用0.33
\centering
\includegraphics[width=2in]{fig1.png}
\caption{The C programing Language}
\label{fig:side:a}
\end{minipage}%
\hfill %水平填充
\begin{minipage}[b]{0.5\linewidth}
\centering
\includegraphics[width=2in]{fig1.png}
\caption{ C Primer Plus}
\label{fig:side:b}
\end{minipage}
\end{figure}

参考链接:https://www.cnblogs.com/yongjiuzhizhen/p/5772962.html?utm_source=itdadao&utm_medium=referral
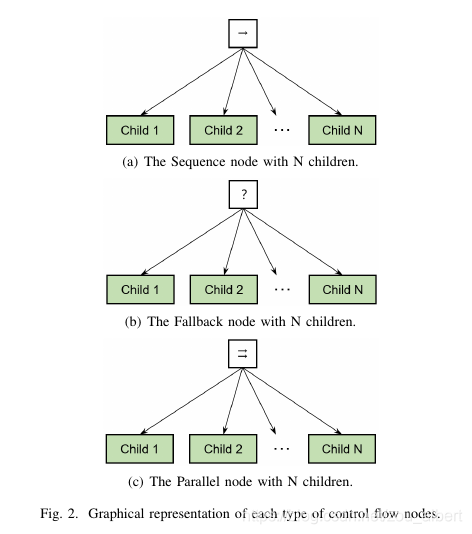
\begin{figure}[t]
\centering
\subfigure[The Sequence node with N children.]{\includegraphics[width=0.3\textwidth]{fig2_a}\label{fig2:a}}
\subfigure[The Fallback node with N children.]{\includegraphics[width=0.3\textwidth]{fig2_b}\label{fig2:b}}
\subfigure[The Parallel node with N children.]{\includegraphics[width=0.3\textwidth]{fig2_c}\label{fig2:c}}
\caption{Graphical representation of each type of control flow nodes.}
\label{fig2}
\end{figure}
\begin{figure}[t]
\centering
\subfigure[Condition node.]{
\begin{minipage}[t]{0.40\linewidth}
\centering
\includegraphics[width=1in]{fig3_a}
\label{fig3:a}
%\caption{fig1}
\end{minipage}%
}%
\subfigure[Action node.]{
\begin{minipage}[t]{0.40\linewidth}
\centering
\includegraphics[width=1in]{fig3_b}
%\caption{fig2}
\label{fig3:b}
\end{minipage}%
}%
\centering
\caption{Graphical representation of condition and action nodes.}
\label{fig:3}
\end{figure}

\begin{algorithm}[tb]
\caption{The algorithm of the announcement stage}
\label{alg:announcement}
\textbf{Input}: $T_i$, the tasks set of $r_i$
\begin{algorithmic}[1] %[1] enables line numbers
\STATE Initialize a tasks list $L_1$
\FOR{each $t_j$ in $T_i$}
\IF{$t_j$ is unassigned}
\STATE $L_1 \leftarrow L_1 \cup\left\{t_{j}\right\}$
\ENDIF
\ENDFOR
\STATE Broadcast $L_1$ to all robots
\end{algorithmic}
\end{algorithm}

\begin{figure*}[htbp]
\centering
\subfigure[]
{
\begin{minipage}[b]{0.4\linewidth}
\centering
\includegraphics[scale=0.3]{figure/1times.png}
\end{minipage}
}
\subfigure[]
{
\begin{minipage}[b]{0.4\linewidth}
\centering
\includegraphics[scale=0.3]{figure/2times.png}
\end{minipage}
}
\caption{(a) shows that when the basic reward value is used, our method can complete the task very well, and the effect is better, while DDPG and DQN fluctuate greatly and are difficult to converge. In (b), the reward and penalty values are adjusted to twice the original value. It can be found that it takes a longer time step to obtain better results. Our method is still better than only using DDPG and DQN.}
\label{rew}
\end{figure*}
两个图片 统一使用一个注释的形式的
版权声明:本文为zou_albert原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。