异常检测-task1:异常检测概述与基本实现
1 异常检测定义与应用
1.1 异常检测定义
- 定义:异常检测(英语:anomaly detection)对不符合预期模式或数据集中其他项目的项目、事件或观测值的识别,通常异常项目会转变成银行欺诈、结构缺陷、医疗问题、文本错误等类型的问题。异常也被称为离群值、新奇、噪声、偏差和例外。
- 有三大类异常检测方法。 在假设数据集中大多数实例都是正常的前提下,无监督异常检测方法能通过寻找与其他数据最不匹配的实例来检测出未标记测试数据的异常。监督式异常检测方法需要一个已经被标记“正常”与“异常”的数据集,并涉及到训练分类器(与许多其他的统计分类问题的关键区别是异常检测的内在不均衡性)。半监督式异常检测方法根据一个给定的正常训练数据集创建一个表示正常行为的模型,然后检测由学习模型生成的测试实例的可能性。
- 类别:点异常(少数个体实例异常)、上下文异常(特定情境下个体实例异常,其他情境下正常)、群体异常(群体集合中的个体实例异常,自身可能不异常)
引用来源: 维基百科-异常检测
1.2 异常检测应用
异常检测的应用领域有:故障检测、物联网异常检测、欺诈检测、工业异常检测、时间序列异常检测、视频异常检测、日志异常检测、医疗异常检测、网络入侵检测等。
2 异常检测的实现算法
- 统计与概率模型:先对数据分布进行假设,在假设下定义异常。如:假设数据服从高斯分布,可以设定阈值,将距离均值某一阈值以外的数据当做异常点。还可以通过计算Z分数和四分位距(IQR)
- 线性模型:典型的有PCA,将数据降到m维之后,计算重建误差,利用正常点的重建误差小这一特点找到异常点,也可以计算样本点到新m维超空间的加权欧式距离,由此找到异常点。
- 基于相似度衡量的模型: 异常点因为和正常点的分布不同,因此相似度较低,由此衍生出来的方法有:k近邻(异常点的k近邻距离大)、基于密度的LOF方法(领域密度小的为异常点)、基于簇的DBSCAN算法(异常点不能被归位某一簇)
- 集成方法:最早的框架为feature bagging,也有用boosting的(较少)
3 利用开源库:PyOD简单实现异常检测
3.1 PyOD库的介绍
引用来源: 用PyOD工具库进行「异常检测」
Python Outlier Detection (PyOD) :是时下最流行的异常检测库,它涵盖了近20种异常检测方法(LOF/LOCI/ABOD/GAN);而且简单易用且一致的API,只需要几行代码就可以完成异常检测;
使用JIT和并行化(parallelization)进行优化,加速算法运行及扩展性(scalability),可以处理大量数据;
PyOD论文:https://www.jmlr.org/papers/volume20/19-011/19-011.pdf 发表于:https://www.jmlr.org/
文档与API:https://pyod.readthedocs.io/en/latest/ 完整API:https://pyod.readthedocs.io/en/latest/api_cc.html
PyOD下载:https://pypi.org/project/pyod/
jupyter示例:https://hub-binder.mybinder.ovh/user/yzhao062-pyod-sug237v4/tree
3.2 API介绍
大部分异常检测算法是无监督学习,PyOD的检测器基本上都有统一的API使用,使用方法与sklearn很像,API使用参考:https://pyod.readthedocs.io/en/latest/api_cc.html
- fit(X): 在初始化检测器clf后,用数据X训练/拟合clf,clf被fit后会有两个属性:
- decision_scores: 对数据X 进行异常打分,分越高,X的异常程度越高
- labels_: 数据X的异常标签,返回二分类标签(0为正常点,1为异常点)
- fit_predict_score(X,y): 用X训练检测器clf后,预测X的预测值,在真实标签y上评估(并非训练)
- decision_function(X): 在检测器clf被fit后,可以通过该函数来预测未知数据的异常程度,返回值为原始分数,并非0和1。返回分数越高,则该数据点的异常程度越高
- predict(X): 在检测器被fit之后,可以用该函数来预测未知数据的异常标签,(0为正常点,1为异常点)
- predict_proba(X): 在检测器被fit后,用该函数预测未知标签的异常概率,
3.3 PyOD API demo:
- 安装pyod:
! pip install pyod
- 导入相应的库函数(以KNN为例)
from pyod.models.knn import KNN
from pyod.utils.data import generate_data
from pyod.utils.data import evaluate_print
from pyod.utils.example import visualize
- 生成数据集
contamination = 0.1 #异常值的比例
n_train = 200
n_test = 100
X_train, y_train, X_test, y_test = \
generate_data(n_train=n_train,
n_test=n_test,
n_features=2,
contamination=contamination,
random_state=42) #n_features = 2时,可以可视化,见后文
- 训练clf
clf_name = 'KNN'
clf = KNN(contamination = contamination,k_neighbors = 5)
clf.fit(X_train)
- 打印评估结果
y_train_pred = clf.labels_ # binary labels (0: inliers, 1: outliers)
y_train_scores = clf.decision_scores_ # raw outlier scores
y_test_pred = clf.predict(X_test) # outlier labels (0 or 1)
y_test_scores = clf.decision_function(X_test) # outlier scores
# evaluate and print the results
print("\nOn Training Data:")
evaluate_print(clf_name, y_train, y_train_scores)
print("\nOn Test Data:")
evaluate_print(clf_name, y_test, y_test_scores)

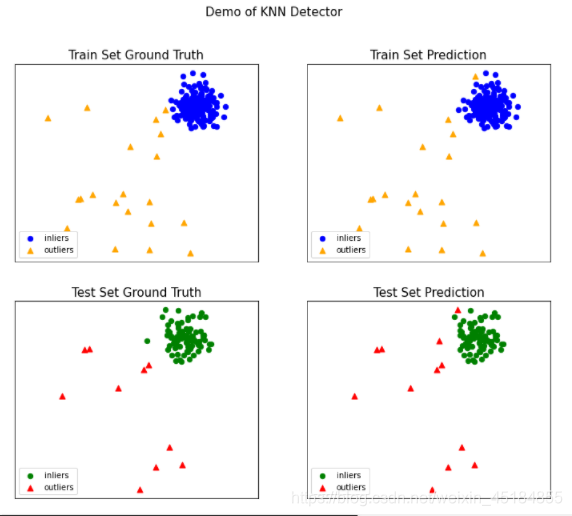
- 可视化
visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred,
y_test_pred, show_figure=True, save_figure=False)
3.4 PyOD学习资源
权威教程:
***引用来源:***用PyOD工具库进行「异常检测」
Analytics Vidhya: An Awesome Tutorial to Learn Outlier Detection in Python using PyOD Library
KDnuggets: Intuitive Visualization of Outlier Detection Methods
awesome-machine-learning: General-Purpose Machine Learning
开发团队所整理的:anomaly-detection-resources