一、大数据生态
1.大数据的概念
大数据不仅仅是数据的“大量化”,而是包含“快速化”、“多样化”和“价值化”等多重属性
2.大数据的特点
(1)数据量大
根据IDC做出估测,数据一直都以每年50%的速度增长,也就是说每两年就增长一倍(大数据摩尔定律)
(2)数据类型繁多
大数据是由结构化和非结构化数据组成的
10%的结构化数据,存储在数据库中
90%的非结构化数据,他们与人类信息密切相关
(3)处理速度快
从数据的生成到消耗,时间窗口非常小,可用于生成决策的时间非常少
1秒定律:这一点也是和传统的数据挖掘技术有着本质的不同
(4)价值密度低
以视频为例,连续不间断监控过程中,可能有用的数据仅仅有一两秒,但是具有很高的商业价值
3.大数据的影响
图灵奖获得者,著名数据库专家Jim Gray博士观察并总结人类自古以来,在科学研究上,先后经历了实验、理论、计算和数据四种范式
在思维方式方面,大数据完全颠覆了传统的思维方式:全样而非抽象
效率而非精确
相关而非因果
4.大数据技术的不同层面及功能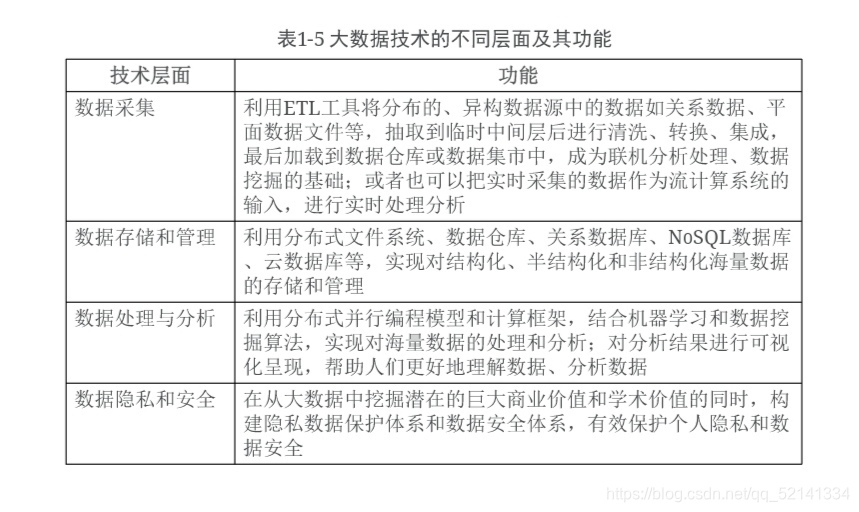
5.大数据关键技术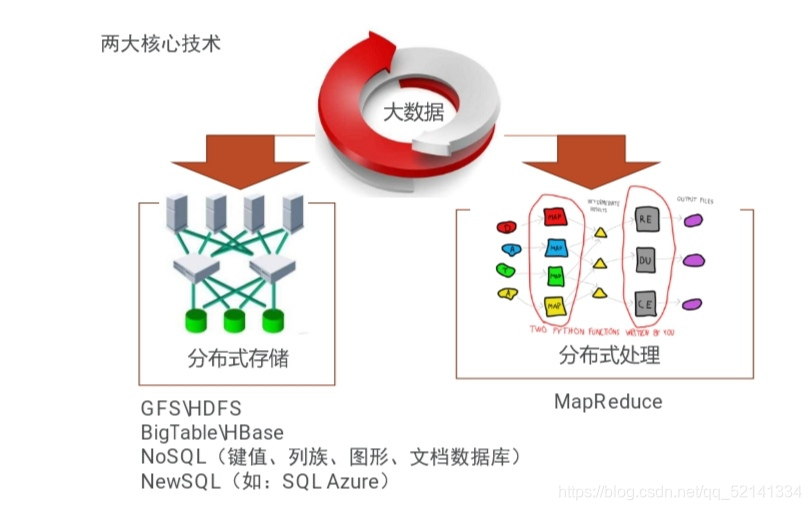
6.大数据计算模式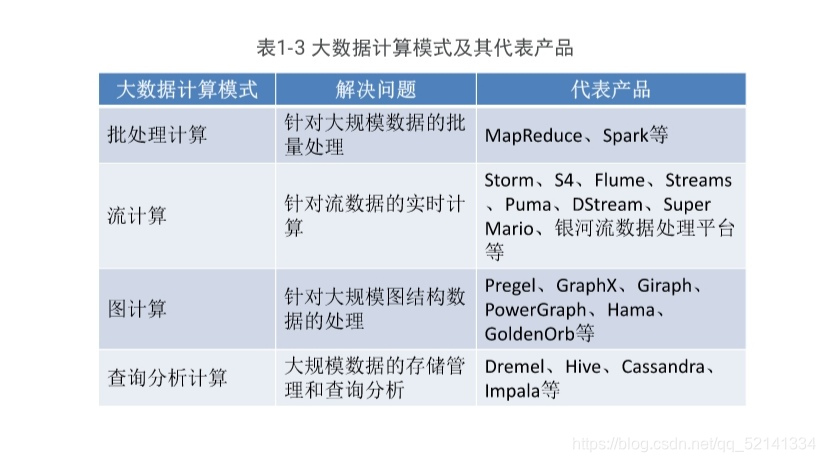
二、Spark简介
1.Spark的特点
(1)运行速度快
使用DAG执行引擎以支持循环数据流与内存计算
(2)容易使用
支持使用Scala、Java、Python和R语言进行编程,可以通过Spark Shell进行交互式编程(3)通用性
Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组
(4)运行模式多样
可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源
2.Spark的前景
Spark如今已吸引了国内外各大公司的注意,如腾讯、淘宝、百度、亚马逊等公司均不同程度的使用了Spark来构建大数据分析应用,并应用到实际的生产环境中Spark与Hadoop对比图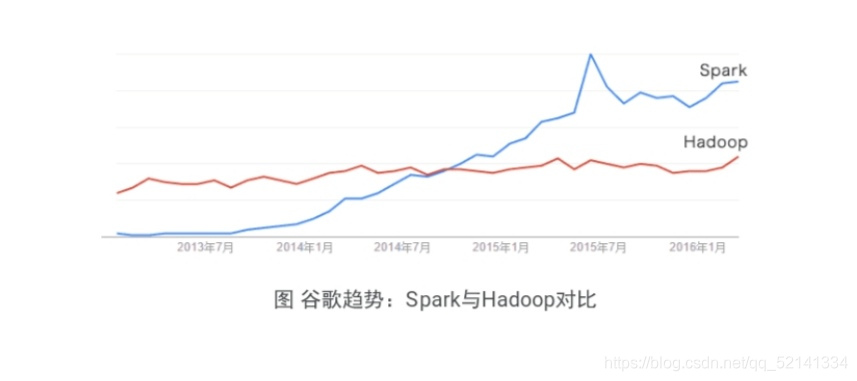
3.Spark的构架图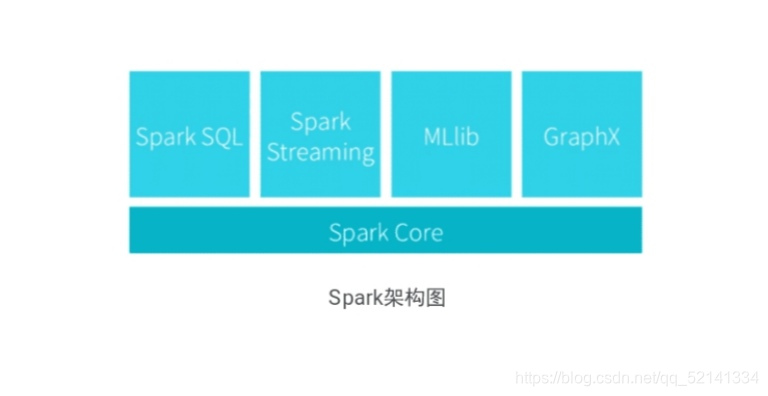
4.Spark的生态系统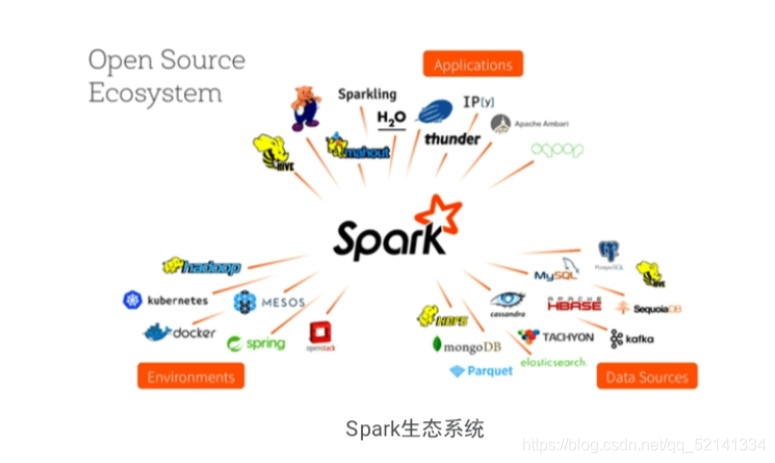
5.Hadoop与Spark的对比
(1)Spark在借鉴Hadoop MapReduce优点的同时,很好的解决了MapReduce所面临的问题
(2)相比于Hadoop MapReduce,Spark主要具有如
A.Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比Hadoop MapReduce更灵活
B.Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高 Spark基于DAG的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制
C.使用Hadoop进行迭代计算非常消耗资源D.Spark将数据载入内存后,之后的迭代计算都可以直接使用内存中的中间结果做运算,避免了从磁盘中频繁读取数据
6.Spark会取代Hadoop吗?
Hadoop包括两大核心:HDFS和MapReduce
Spark作为计算框架,与MapReduce是对等的谈到“取代”,Spark应该是取代MapReduce,而不是整个HadoopSpark和Hadoop生态系统共存共荣,Spark借助于Hadoop的HDFS、HBase等来完成数据的存储,然后由Spark完成数据的计算
以上就是大数据生态和Spark简介的全部内容了!
大数据生态和Spark简介
版权声明:本文为qq_52141334原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。