selenium和 Scrapy对接
爬取某些需要动态加载的页面,使用selenium模块是诸多方法中的一个,直接使用selenium模块并不复杂,
在Scrapy框架下依然可以使用该模块解决动态加载的问题.
首先再熟悉下流程
Scrapy的基本流程图如下
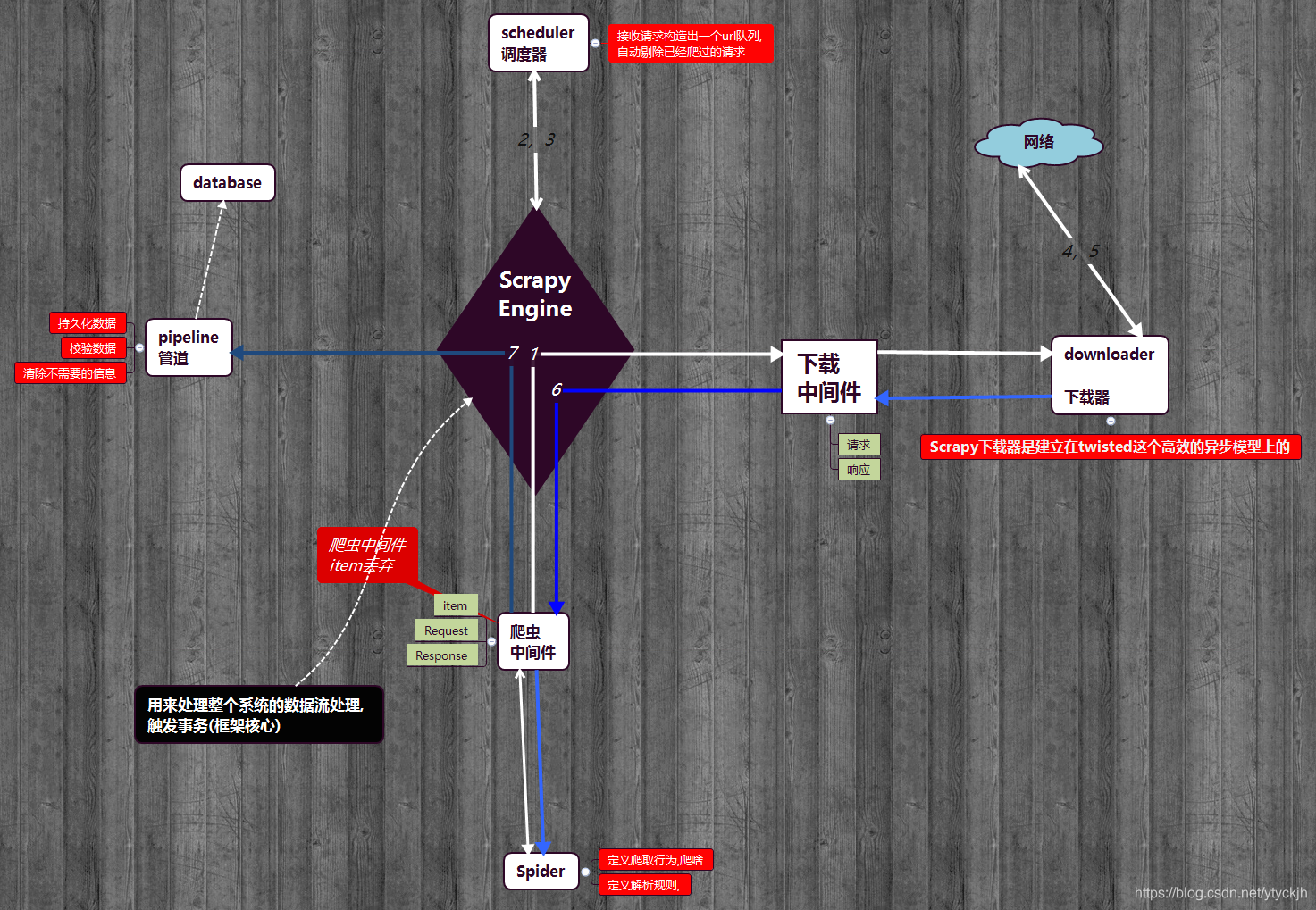
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。
调度器(用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回.
用于下载网页内容, 并将网页内容返回给EGINE
SPIDERS用来解析responses,并且提取items,或者发送新的请求
管道在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
下载器中间件位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response,
爬虫中间件位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
基本思路
直接解析接受动态加载页面的响应,无法获得预期的数据,所以我们可以在下载中间件中拦截该响应,并篡改响应,从而获取我们想要的数据.
1. 准备工作
在 setting.py 下:
DOWNLOADER_MIDDLEWARES = {
'news163.middlewares.News163DownloaderMiddleware': 543,
}
在 name_spider.py 下:
实例化浏览器对象:
以谷歌浏览器为例,
driver = webdriver.Chrome(executable_path='...')
或:
实例化浏览器对象(无头浏览器)
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(options=chrome_options,executable_path='...')
ps:不要在下载中间件中实例化,会浪费资源降低效率.
在爬虫类下,准备一个列表,用来存放需要动态加载的页面的 url:
start_urls = ['url1','url2','url3'......]
2. 拦截响应,并篡改
下载中间件类:
- 判断该响应对应的url是否在,准备好的列表中,若不在则无需篡改,否则进行下一步
- 调用无头浏览器,书写逻辑获取响应内容
- 构造响应返回给引擎,
代码
import time
from scrapy.http import HtmlResponse
......
def process_response(self, request, response, spider):
driver = spider.driver
if request.url in spider.start_urls:
driver.get(request.url)
time.sleep(3)
js = 'window.scrollTo(0, document.body.scrollHeight)'
driver.execute_script(js) # 向下滑
time.sleep(3)
response_selenium = driver.page_source # 响应内容
return HtmlResponse(url=driver.current_url, body=response_selenium, encoding='utf-8', request=request)
# 构造响应,
return response
这样我们就能篡改响应,爬取到需要动态加载页面的数据了
版权声明:本文为ytyckjh原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。