深入分析Linux内核源码-第五章进程调度
【摘要】本章介绍了Linux系统的时间机制,包括系统时钟和硬件时钟之间的关系、各种时间标准的转换、时钟中断tick的维护;接着介绍了进程调度的几种常见算法、何时进行内核调度及选择相应该调度的进程,并分析了调度程序的实现;最后介绍了进程切换的硬件支持和软件实现。
【关键字】Tick,系统时间,硬件CMOS时钟,Jiffies,调度算法,RR,Goodness,Schedule,进程切换,Switch_mm
第五章进程调度... 1
5.1 Linux时间系统... 1
5.1.1 时钟硬件... 1
5.1.2 时钟运作机制... 2
5.1.3 Linux时间基准... 2
5.1.4 Linux的时间系统... 3
5.2 时钟中断... 3
5.2.1 时钟中断的产生... 3
5.2.2.Linux实现时钟中断的全过程... 4
5.3 Linux的调度程序-Schedule( ) 7
5.3.1基本原理... 7
5.3.2 Linux进程调度时机... 8
5.3.3 进程调度的依据... 10
5.3.4 进程可运行程度的衡量... 10
5.3.5进程调度的实现... 11
5.4 进程切换... 14
5.4.1 硬件支持... 14
5.4.2进程切换... 16
第五章进程调度
5.1 Linux时间系统
计算机最基本的时间单元是时钟周期,例如取指令、执行指令、存取内存等。时间系统是计算机系统非常重要的组成部分,特别是对于Unix类分时系统尤为重要。时间系统主要任务是维持系统时间并且防止某个进程独占CPU及其他资源,也就是驱动进程的调度。
5.1.1 时钟硬件
大部分PC机中有两个时钟源,他们分别叫做RTC和OS(操作系统)时钟。RTC(Real Time Clock,实时时钟)也叫做CMOS时钟,它是PC主机板上的一块芯片,它靠电池供电,即使系统断电,也可以维持日期和时间。由于它独立于操作系统,所以也被称为硬件时钟,它为整个计算机提供一个计时标准,是最原始最底层的时钟数据。
Linux只用RTC来获得时间和日期;然而,通过作用于/dev/rtc设备文件,也允许进程对RTC编程。通过执行/sbin/clock系统程序,系统管理员可以配置时钟。
OS时钟产生于PC主板上的定时/计数芯片,由操作系统控制这个芯片的工作,OS时钟的基本单位就是该芯片的计数周期。在开机时操作系统取得RTC中的时间数据来初始化OS时钟,然后通过计数芯片的向下计数形成了OS时钟,它更应该被称为一个计数器。OS时钟只在开机时才有效,而且完全由操作系统控制,所以也被称为软时钟或系统时钟。下面我们重点描述OS时钟的产生。
OS时钟输出脉冲信号,接到中断控制器上,产生中断信号,触发后面要讲的时钟中断,由时钟中断服务程序维持OS时钟的正常工作。
5.1.2 时钟运作机制
RTC和OS时钟之间的关系通常也被称作操作系统的时钟运作机制。一般来说,RTC是OS时钟的时间基准,操作系统通过读取RTC来初始化OS时钟,此后二者保持同步运行,共同维持着系统时间。保持同步运行是什么意思呢?就是指操作系统运行过程中,每隔一个固定时间会刷新或校正RTC中的信息。
图5.2 时钟运作机制
我们可以看到,RTC处于最底层,提供最原始的时钟数据。OS时钟建立在RTC之上,初始化完成后将完全由操作系统控制,和RTC脱离关系。操作系统通过OS时钟提供给应用程序所有和时间有关的服务。
5.1.3 Linux时间基准
以上我们了解了RTC(实时时钟、硬件时钟)和OS时钟(系统时钟、软时钟)。下面我们具体描述OS时钟。OS时钟是由可编程定时/计数器产生的输出脉冲触发中断而产生的。输出脉冲的周期叫做一个“时钟滴答”。计算机中的时间是以时钟滴答为单位的,每一次时钟滴答,系统时间就会加1。操作系统根据当前时钟滴答的数目就可以得到以秒或毫秒等为单位的其他时间格式。
定义“时间基准”的目的是为了简化计算,这样计算机中的时间只要表示为从这个时间基准开始的时钟滴答数就可以了。“时间基准是由操作系统的设计者规定的。例如DOS的时间基准是1980年1月1日,Unix的时间基准是1970年1月1日上午12点,Linux的时间基准是1970年1月1日凌晨0点。
5.1.4 Linux的时间系统
OS时钟记录的时间也就是通常所说的系统时间。系统时间是以“时钟滴答”为单位的,而时钟中断的频率决定了一个时钟滴答的长短,例如每秒有100次时钟中断,那么一个时钟滴答的就是10毫秒(记为10ms),相应地,系统时间就会每10ms增1。
Linux中用全局变量jiffies表示系统自启动以来的时钟滴答数目。在/kernel/time.c中定义如下:
unsigned long volatile jiffies
在jiffies基础上,Linux提供了如下适合人们习惯的时间格式,在/include/linux/time.h中定义如下:
struct timespec { /* 这是精度很高的表示*/
long tv_sec; /* 秒 (second) */
long tv_nsec; /* 纳秒:十亿分之一秒( nanosecond)*/
};
struct timeval { /* 普通精度 */
int tv_sec; /* 秒 */
int tv_usec; /* 微秒:百万分之一秒(microsecond)*/
};
struct timezone { /* 时区 */
int tz_minuteswest; /* 格林尼治时间往西方的时差 */
int tz_dsttime; /* 时间修正方式 */
};
tv_sec表示秒(second),tv_usec表示微秒(microsecond),tv_nsec表示纳秒(nanosecond)。定义tb_usec和tv_nsec的目的是为了适用不同的使用要求,不同的场合根据对时间精度的要求选用这两种表示。另外,Linux还定义了用于表示更加符合大众习惯的时间表示:年、月、日。但是万变不离其宗,所有的时间应用都是建立在jiffies基础之上的。简而言之,jiffies产生于时钟中断!
5.2 时钟中断
5.2.1 时钟中断的产生
“时钟中断”是特别重要的一个中断,因为整个操作系统的活动都受到它的激励。系统利用时钟中断维持系统时间、促使环境的切换,以保证所有进程共享CPU;利用时钟中断进行记帐、监督系统工作以及确定未来的调度优先级等工作。可以说,“时钟中断”是整个操作系统的脉搏。
时钟中断的物理产生如图5.3所示:
图5.3 8253和8259A的物理连接方式
脉冲信号接到中断控制器8259A_1的0号管脚,触发一个周期性的中断,我们就把这个中断叫做时钟中断,时钟中断的周期,也就是脉冲信号的周期,我们叫做“滴答”或“时标”(tick)。从本质上说,时钟中断只是一个周期性的信号,完全是硬件行为,该信号触发CPU去执行一个中断服务程序,我们就把这个服务程序叫做时钟中断。
5.2.2.Linux实现时钟中断的全过程
1. 和时钟中断相关的函数
下面我们看时钟中断触发的服务程序,该程序代码比较复杂,分布在不同的源文件中,主要包括如下函数:
时钟中断程序:timer_interrupt( );
中断服务通用例程do_timer_interrupt();
时钟函数:do_timer( );
中断安装程序:setup_irq( );
中断返回函数:ret_from_intr( );
前三个函数的调用关系如下:
timer_interrupt( )
do_timer_interrupt()
do_timer( )
(1) timer_interrupt( )
这个函数大约每10ms被调用一次,实际上, timer_interrupt( )函数是一个封装例程,它真正做的事情并不多,该函数主要语句就是调用do_timer_interrupt()函数。
(2) do_timer_interrupt()
do_timer_interrupt()函数有两个主要任务,一个是调用do_timer( ),另一个是维持实时时钟(RTC,每隔一定时间段要回写),其实现代码在/arch/i386/kernel/time.c中, 为了突出主题,笔者对以下函数作了改写,以便于读者理解:
static inline void do_timer_interrupt(int irq, void *dev_id, struct pt_regs *regs)
{
do_timer(regs); /* 调用时钟函数,将时钟函数等同于时钟中断未尝不可*/
if(xtime.tv_sec > last_rtc_update + 660)
update_RTC();
/*每隔11分钟就更新RTC中的时间信息,以使OS时钟和RTC时钟保持同步,11分钟即660秒,xtime.tv_sec的单位是秒,last_rtc_update记录的是上次RTC更新时的值 */
}
其中,xtime是前面所提到的timeval类型,这是一个全局变量。
(3) 时钟函数do_timer() (在/kernel/sched.c中)
void do_timer(struct pt_regs * regs)
{
(*(unsigned long *)&jiffies)++; /*更新系统时间,这种写法保证对jiffies操作的原子性*/
update_process_times();
++lost_ticks;
if( ! user_mode ( regs ) )
++lost_ticks_system;
mark_bh(TIMER_BH);
if (tq_timer)
mark_bh(TQUEUE_BH);
}
其中,update_process_times()函数与进程调度有关,从函数的名子可以看出,它处理的是与当前进程与时间有关的变量,例如,要更新当前进程的时间片计数器counter,如果counter<=0,则要调用调度程序。
与时间有关的事情很多,不能全都让这个函数去完成,这是因为这个函数是在关中断的情况下执行,必须处理完最重要的时间信息后退出,以处理其他事情。那么,与时间相关的其他信息谁去处理,何时处理?这就是由第三章讨论的后半部分去去处理。上面timer_interrupt()所做的事情就是上半部分。
(4)中断安装程序
从上面的介绍可以看出,时钟中断与进程调度密不可分,因此,一旦开始有时钟中断就可能要进行调度,在系统进行初始化时,所做的大量工作之一就是对时钟进行初始化,其函数time_init ()的代码在/arch/i386/kernel/time.c中,对其简写如下:
void __init time_init(void)
{
xtime.tv_sec=get_cmos_time();
xtime.tv_usec=0;
setup_irq(0,&irq0);
}
其中的get_cmos_time()函数就是把当时的实际时间从CMOS时钟芯片读入变量xtime中,时间精度为秒。而setup_irq(0,&irq0)就是时钟中断安装函数,那么irq0指的是什么呢,它是一个结构类型irqaction,其定义及初值如下:
static struct irqaction irq0 = { timer_interrupt, SA_INTERRUPT, 0, "timer", NULL, NULL};
setup_irq(0, &irq0)的代码在/arch/i386/kernel/irq.c中,其主要功能就是将中断程序连入相应的中断请求队列,以等待中断到来时相应的中断程序被执行。
我们将有关函数改写如下,体现时钟中断的大意:
do_timer_interrupt( ) /*这是一个伪函数 */
{
SAVE_ALL /*保存处理机现场 */
intr_count += 1; /* 这段操作不允许被中断 */
timer_interrupt() /* 调用时钟中断程序 */
intr_count -= 1;
jmp ret_from_intr /* 中断返回函数 */
}
其中,jmp ret_from_intr 是一段汇编代码,也是一个较为复杂的过程,它最终要调用jmp ret_from_sys_call,即系统调用返回函数,而这个函数与进程的调度又密切相关,,因此,我们重点分析jmp ret_from_sys_call。
2.系统调用返回函数:
系统调用返回函数的源代码在/arch/i386/kernel/entry.S中
ENTRY(ret_from_sys_call)
cli # need_resched and signals atomic test
cmpl $0,need_resched(%ebx)
jne reschedule
cmpl $0,sigpending(%ebx)
jne signal_return
restore_all:
RESTORE_ALL
ALIGN
signal_return:
sti # we can get here from an interrupt handler
testl $(VM_MASK),EFLAGS(%esp)
movl %esp,%eax
jne v86_signal_return
xorl %edx,%edx
call SYMBOL_NAME(do_signal)
jmp restore_all
ALIGN
v86_signal_return:
call SYMBOL_NAME(save_v86_state)
movl %eax,%esp
xorl %edx,%edx
call SYMBOL_NAME(do_signal)
jmp restore_all
….
reschedule:
call SYMBOL_NAME(schedule) # test
jmp ret_from_sys_call
这一段汇编代码就是前面我们所说的“从系统调用返回函数”ret_from_sys_call,它是从中断、异常及系统调用返回时的通用接口。这段代码主体就是ret_from_sys_call函数,在此我们列出相关的几个函数:
(1)ret_from_sys_call:主体
(2)reschedule:检测是否需要重新调度
(3)signal_return:处理当前进程接收到的信号
(4)v86_signal_return:处理虚拟86模式下当前进程接收到的信号
(5)RESTORE_ALL:我们把这个函数叫做彻底返回函数,因为执行该函数之后,就返回到当前进程的地址空间中去了。
可以看到ret_from_sys_call的主要作用有:
检测调度标志need_resched,决定是否要执行调度程序;处理当前进程的信号;恢复当前进程的环境使之继续执行。
最后我们再次从总体上浏览一下时钟中断:
每个时钟滴答,时钟中断得到执行。时钟中断执行的频率很高:100次/秒,时钟中断的主要工作是处理和时间有关的所有信息、决定是否执行调度程序以及处理下半部分。和时间有关的所有信息包括系统时间、进程的时间片、延时、使用CPU的时间、各种定时器,进程更新后的时间片为进程调度提供依据,然后在时钟中断返回时决定是否要执行调度程序。下半部分处理程序是Linux提供的一种机制,它使一部分工作推迟执行。
5.3 Linux的调度程序-Schedule( )
5.3.1基本原理
调度的实质就是资源的分配。系统通过不同的调度算法(Scheduling Algorithm)来实现这种资源的分配。通常来说,选择什么样的调度算法取决于的资源分配的策略(Scheduling Policy),在这里只说明与Linux调度相关的几种算法及这些算法的原理。
一个好的调度算法应当考虑以下几个方面:
(1)公平:保证每个进程得到合理的CPU时间。
(2)高效:使CPU保持忙碌状态,即总是有进程在CPU上运行。
(3)响应时间:使交互用户的响应时间尽可能短。
(4)周转时间:使批处理用户等待输出的时间尽可能短。
(5)吞吐量:使单位时间内处理的进程数量尽可能多。
很显然,这5个目标不可能同时达到,所以,不同的操作系统会在这几个方面中作出相应的取舍,从而确定自己的调度算法,例如UNIX采用动态优先数调度、BSD采用多级反馈队列调度、Windows采用抢先多任务调度等等。
下面来了解一下主要的调度算法及其基本原理:
1.时间片轮转调度算法
时间片(Time Slice)就是分配给进程运行的一段时间。在通常的轮转法中,系统将所有的可运行(即就绪)进程按先来先服务的原则,排成一个队列,每次调度时把CPU分配给队首进程,并令其执行一个时间片。当执行的时间片用完时,系统发出信号,通知调度程序,调度程序便据此信号来停止该进程的执行,并将它送到运行队列的末尾,等待下一次执行;然后,把处理机分配给就绪队列中新的队首进程,同时也让它执行一个时间片。这样就可以保证运行队列中的所有进程,在一个给定的时间内,均能获得一时间片的处理机执行时间。
2.优先权调度算法
为了照顾到紧迫型进程在进入系统后便能获得优先处理,引入了最高优先权调度算法。当将该算法用于进程调度时,系统将把处理机分配给运行队列中优先权最高的进程,这时,又可进一步把该算法分成两种方式:
(1) 非抢占式优先权算法(又称不可剥夺调度:Nonpreemptive Scheduling)
在这种方式下,系统一旦将处理机(CPU)分配给运行队列中优先权最高的进程后,该进程便一直执行下去,直至完成;或因发生某事件使该进程放弃处理机时,系统方可将处理机分配给另一个优先权高的进程。这种调度算法主要用于批处理系统中,也可用于某些对实时性要求不严的实时系统中。
(2) 抢占式优先权调度算法(又称可剥夺调度:Preemptive Scheduling)
该算法的本质就是系统中当前运行的进程永远是可运行进程中优先权最高的那个。在采用这种调度算法时,每当出现一新的可运行进程,就将它和当前运行进程进行优先权比较,如果高于当前进程,将触发进程调度。这种方式的优先权调度算法,能更好的满足紧迫进程的要求,故而常用于要求比较严格的实时系统中,以及对性能要求较高的批处理和分时系统中。Linux也采用这种调度算法。
3.多级反馈队列调度
这是时下最时髦的一种调度算法。其本质是:综合了时间片轮转调度和抢占式优先权调度的优点,即:优先权高的进程先运行给定的时间片,相同优先权的进程轮流运行给定的时间片。
4.实时调度
最后我们来看一下实时系统中的调度。什么叫实时系统,就是系统对外部事件有求必应、尽快响应。在实时系统中,广泛采用抢占调度方式,特别是对于那些要求严格的实时系统。因为这种调度方式既具有较大的灵活性,又能获得很小的调度延迟;但是这种调度方式也比较复杂。
5.3.2 Linux进程调度时机
Linux的调度程序是一个叫Schedule()的函数,这个函数被调用的频率很高,由它来决定是否要进行进程的切换,如果要切换的话,切换到哪个进程等等。我们先来看在什么情况下要执行调度程序,我们把这种情况叫做调度时机。
Linux调度时机主要有:
1、进程状态转换的时刻:进程终止、进程睡眠;
2、当前进程的时间片用完时(current->counter=0);
3、设备驱动程序主动调用schedule;
4、进程从中断、异常及系统调用返回到用户态时;
时机1,进程要调用sleep()或exit()等函数进行状态转换,这些函数会主动调用调度程序进行进程调度;
时机2,由于进程的时间片是由时钟中断来更新的,因此,这种情况和时机4是一样的。
时机3,当设备驱动程序执行长而重复的任务时,直接调用调度程序。在每次反复循环中,驱动程序都检查need_resched的值,如果必要,则调用调度程序schedule()主动放弃CPU。
时机4,如前所述,不管是从中断、异常还是系统调用返回,最终都调用ret_from_sys_call(),由这个函数进行调度标志的检测,如果必要,则调用调度程序。那么,为什么从系统调用返回时要调用调度程序呢?这当然是从效率考虑。从系统调用返回意味着要离开内核态而返回到用户态,而状态的转换要花费一定的时间,因此,在返回到用户态前,系统把在内核态该处理的事全部做完。
每个时钟中断(timer interrupt)发生时,由三个函数协同工作,共同完成进程的选择和切换,它们是:schedule()、do_timer()及ret_form_sys_call()。我们先来解释一下这三个函数:
schedule():进程调度函数,由它来完成进程的选择(调度);
do_timer():暂且称之为时钟函数,该函数在时钟中断服务程序中被调用,被调用的频率就是时钟中断的频率即每秒钟100次(简称100赫兹或100Hz);
ret_from_sys_call():系统调用返回函数。当一个系统调用或中断完成时,该函数被调用,用于处理一些收尾工作,例如信号处理、核心任务等等。
这三个函数是如何协调工作的呢?
前面我们看到,时钟中断是一个中断服务程序,它的主要组成部分就是时钟函数do_timer(),由这个函数完成系统时间的更新、进程时间片的更新等工作,更新后的进程时间片counter作为调度的主要依据。在时钟中断返回时,要调用函数ret_from_sys_call(),前面我们已经讨论过这个函数,在这个函数中有如下几行:
cmpl $0, _need_resched
jne reschedule
……
restore_all:
RESTORE_ALL
reschedule:
call SYMBOL_NAME(schedule)
jmp ret_from_sys_call
这几行的意思很明显:检测 need_resched 标志,如果此标志为非0,那么就转到reschedule处调用调度程序schedule()进行进程的选择。调度程序schedule()会根据具体的标准在运行队列中选择下一个应该运行的进程。当从调度程序返回时,如果发现又有调度标志被设置,则又调用调度程序,直到调度标志为0,这时,从调度程序返回时由RESTORE_ALL恢复被选定进程的环境,返回到被选定进程的用户空间,使之得到运行。
Linux 调度程序和其他的UNIX调度程序不同,尤其是在“nice level”优先级的处理上,与优先权调度(priority高的进程最先运行)不同,Linux用的是时间片轮转调度(Round Robing),但同时又保证了高优先级的进程运行的既快、时间又长(both sooner and longer)。而标准的UNIX调度程序都用到了多级进程队列。大多数的实现都用到了二级优先队列:一个标准队列和一个实时(“real time”)队列。一般情况下,如果实时队列中的进程未被阻塞,它们都要在标准队列中的进程之前被执行,并且,每个队列中,“nice level”高的进程先被执行。
5.3.3 进程调度的依据
调度程序运行时,要在所有处于可运行状态的进程之中选择最值得运行的进程投入运行。选择进程的依据是什么呢?在每个进程的task_struct结构中有这么五项:
need_resched、nice、counter、policy 及rt_priority
need_resched: 在调度时机到来时,检测这个域的值,如果为1,则调用schedule() 。
counter: 进程处于运行状态时所剩余的时钟滴答数,每次时钟中断到来时,这个值就减1。当这个域的值变得越来越小,直至为0时,就把need_resched 域置1,因此,也把这个域叫做进程的“动态优先级”。
nice: 进程的“静态优先级”,这个域决定counter 的初值。只有通过nice(), sched_setparam()系统调用才能改变进程的静态优先级。
rt_priority: 实时进程的优先级
policy: 从整体上区分实时进程和普通进程,因为实时进程和普通进程的调度是不同的,它们两者之间,实时进程应该先于普通进程而运行,可以通过系统调用sched_setscheduler( )来改变调度的策略。对于同一类型的不同进程,采用不同的标准来选择进程。对于普通进程,选择进程的主要依据为counter和nice 。对于实时进程,Linux采用了两种调度策略,即FIFO(先来先服务调度)和RR(时间片轮转调度)。因为实时进程具有一定程度的紧迫性,所以衡量一个实时进程是否应该运行,Linux采用了一个比较固定的标准。实时进程的counter只是用来表示该进程的剩余滴答数,并不作为衡量它是否值得运行的标准,这和普通进程是有区别的。
5.3.4 进程可运行程度的衡量
函数goodness()就是用来衡量一个处于可运行状态的进程值得运行的程度。该函数综合使用了上面我们提到的五项,给每个处于可运行状态的进程赋予一个权值(weight),调度程序以这个权值作为选择进程的唯一依据。函数主体如下:
static inline int goodness(struct task_struct * p, int this_cpu, struct mm_struct *this_mm)
{ int weight; /* 权值,作为衡量进程是否运行的唯一依据 *
weight=-1;
if (p->policy&SCHED_YIELD)
goto out; /*如果该进程愿意“礼让(yield)”,则让其权值为-1 */
switch(p->policy)
{
/* 实时进程*/
case SCHED_FIFO:
case SCHED_RR:
weight = 1000 + p->rt_priority;
/* 普通进程 */
case SCHED_OTHER:
{ weight = p->counter;
if(!weight)
goto out
/* 做细微的调整*/
if (p->mm=this_mm||!p->mm)
weight = weight+1;
weight+=20-p->nice; /*在剩余counter一样的情况下,短进程优先*/
}
}
out:
return weight; /*返回权值*/
}
其中,在sched.h中对调度策略定义如下:
#define SCHED_OTHER 0
#define SCHED_FIFO 1
#define SCHED_RR 2
#define SCHED_YIELD 0x10
这个函数比较很简单。首先,根据policy区分实时进程和普通进程。实时进程的权值取决于其实时优先级,其至少是1000,与conter和nice无关。普通进程的权值需特别说明两点:
为什么进行细微的调整?如果p->mm为空,则意味着该进程无用户空间(例如内核线程),则无需切换到用户空间。如果p->mm=this_mm,则说明该进程的用户空间就是当前进程的用户空间,该进程完全有可能再次得到运行。对于以上两种情况,都给其权值加1,算是对它们小小的奖励。
进程的优先级nice是从早期Unix沿用下来的负向优先级,其数值标志“谦让”的程度,其值越大,就表示其越“谦让”,也就是优先级越低,其取值范围为-20~+19,因此,(20-p->nice)的取值范围就是0~40。可以看出,普通进程的权值不仅考虑了其剩余的时间片,还考虑了其优先级,优先级越高,其权值越大。
根据进程调度的依据,调度程序就可以控制系统中的所有处于可运行状态的进程并在它们之间进行选择
系统时钟与进程调度_dianhuiren的博客-CSDN博客
Linux内核linux0.12与linux2.6对比学习系列(3)——进程调度
前言
linux0.12与linux2.6在进程调度的实现上有很大的不同,在此进行记录
Linux 0.12
该版本对于进程调度算法的实现十分简单,具体实现看schedule()即可,该函数为调度入口
kernel/sched.c
void schedule(void)
{
int i,next,c;
struct task_struct ** p;
// ----------------省略检查相关代码------------------
/* this is the scheduler proper: */
while (1) {
c = -1;
next = 0;
i = NR_TASKS;
p = &task[NR_TASKS];
while (--i) {
if (!*--p)
continue;
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
}
if (c) break;
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p)
(*p)->counter = ((*p)->counter >> 1) +
(*p)->priority;
}
switch_to(next);
}
由上可知晓该版本调度全过程,无非遍历 task_struct 指针数组(task),判断是否有进程的 counter(允许运行时间)大于0,若有则找出 counter 最大的,否则对所有进程根据优先级(priority)重新分配 counter ,再遍历找出 counter 最大的进行切换(switch_to)
说到调度,除了如何执行调度还需要了解何时调度。根据之前文章,我们知道时钟中断对应的中断执行程序为timer_interrupt,其触发do_timer 进行当前时间片的检查,对于该版本而言,do_timer()先判断当前进程counter是否耗尽,才会执行schedule()。这意味着,该版本的进程是不可抢占的。(倘若分配的时间片很多,则其他进程将久久得不到相应)
void do_timer(long cpl)
{
//-----省略无关代码---------
if (next_timer) {
next_timer->jiffies--;
while (next_timer && next_timer->jiffies <= 0) {
void (*fn)(void);
fn = next_timer->fn;
next_timer->fn = NULL;
next_timer = next_timer->next;
(fn)();
}
}
if (current_DOR & 0xf0)
do_floppy_timer();
if ((--current->counter)>0) return;
current->counter=0;
if (!cpl) return;
schedule();
}
关于0.12版本的进程调度核心内容只有这么多,对于何种调度算法最优在此不进行讨论,只是比较两个版本的实现有何区别
Linux 2.6
在该版本中,为了实现进程调度,相较于0.12版本设计了很多新的概念。笔者进行学习的过程中,参考了 https://www.cnblogs.com/ck1020/p/6089970.html。而《Linux内核设计与实现》中对于该知识点的梳理十分跳跃,对于初学者难以把握精髓。为此,先从原理进行梳理,在进入代码与0.12版本进行对比。
如何调度
相关概念
关于进程调度的一些结构体:
就绪队列 rq
调度器 sched_class
调度实体 sched_entity
调度器结构
与0.12不同,该版本内核并不是直接操作进程的task_struct,在获取到最终需要执行的task_struct之前,还涉及就绪队列,调度器等相关逻辑。首先,如下图所示,主调度器(可以理解为schedule())会先选择调度器类,再由调度器类选择下一个要执行的进程。每个进程只会属于一个调度器类,而调度器类之间会有优先级,主调度器调用时会参考优先级从高到底选择调度器。由于每个cpu上执行的进程不同,为了在多个cpu环境下执行任务,设计就绪队列rq,每个CPU关联一个rq,该rq上记录可以被当前cpu执行的调度器类及其进程。
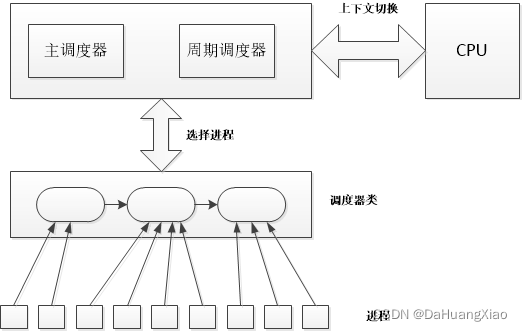
因此,schedule()主调度器要做的事情是:
获取当前就绪队列rq
找到rq上关联的调度器类
根据调度器类优先级,按顺序从调度器类中选择进程
至于每个调度器类会执行怎样的进程选择策略交由调度器类自己定义
切换任务
如此一来,内核开发人员可以自定义调度器类,使得内核的调度算法变得可扩展。这与dubbo设计loadbanlance接口是类似的。代码如下(省略了非重点代码)
kernel/sched.c
asmlinkage void __sched schedule(void)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq *rq;
int cpu;
// ---------省略无关代码--------
rq = cpu_rq(cpu); // 1. 获取当前就绪队列rq
pre_schedule(rq, prev);
if (unlikely(!rq->nr_running))
idle_balance(cpu, rq);
put_prev_task(rq, prev);
next = pick_next_task(rq); // 2. 找到rq上关联的调度器类。3. 根据调度器类优先级,按顺序从调度器类中选择进程
if (likely(prev != next)) {
sched_info_switch(prev, next);
perf_event_task_sched_out(prev, next);
rq->nr_switches++;
rq->curr = next;
++*switch_count;
context_switch(rq, prev, next); // 4. 切换任务
/*
* the context switch might have flipped the stack from under
* us, hence refresh the local variables.
*/
cpu = smp_processor_id();
rq = cpu_rq(cpu);
} else
raw_spin_unlock_irq(&rq->lock);
// ---------省略无关代码--------
}
进一步地跟踪pick_next_task()。根据变量及函数名我们大致能够猜测该函数完成了几件事
判断就绪队列rq上就绪态的进程数nr_running是否等于调度器cfs的就绪态进程数,如果相等,说明进程都在调度器cfs中,直接执行调度器cfs的pick方法选择进程
否则,从优先级最高的调度器类sched_class_highest开始遍历,调用其pick方法,如果当前调度器找不到进程,则去后一个调度器里找
kernel/sched.c
static inline struct task_struct *
pick_next_task(struct rq *rq)
{
const struct sched_class *class;
struct task_struct *p;
/*
* Optimization: we know that if all tasks are in
* the fair class we can call that function directly:
*/
if (likely(rq->nr_running == rq->cfs.nr_running)) {
p = fair_sched_class.pick_next_task(rq);
if (likely(p))
return p;
}
class = sched_class_highest;
for ( ; ; ) {
p = class->pick_next_task(rq);
if (p)
return p;
/*
* Will never be NULL as the idle class always
* returns a non-NULL p:
*/
class = class->next;
}
}
具体地,以cfs调度器类为例,看看其pick方法如何找到一个待执行的进程。根据该调度器类的定义,我们知道知道其pick_next_task方法对应的是pick_next_task_fair
kernel\sched_fair.c
static const struct sched_class fair_sched_class = {
.next = &idle_sched_class,
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.yield_task = yield_task_fair,
.check_preempt_curr = check_preempt_wakeup,
.pick_next_task = pick_next_task_fair,
.put_prev_task = put_prev_task_fair,
.task_tick = task_tick_fair,
.task_fork = task_fork_fair,
};
可以看到,该方法先是通过rq获取cfs_rq,再调用该类的pick_next_entity方法从cfs_rq上获得一个sched_entity,其中sched_entity对应一个进程或者一个进程组,是一个调度单位。由此我们也知道了,实际上,所有的进程或者进程组都被封装为一个调度实体sched_entity并关联着rq。而每个调度器类只是提供了在rq上找出目标调度实体的方法而已,它并不关联和存储任何调度实体内容
kernel\sched_fair.c
static struct task_struct *pick_next_task_fair(struct rq *rq)
{
struct task_struct *p;
struct cfs_rq *cfs_rq = &rq->cfs;
struct sched_entity *se;
if (!cfs_rq->nr_running)
return NULL;
do {
se = pick_next_entity(cfs_rq);
set_next_entity(cfs_rq, se);
cfs_rq = group_cfs_rq(se);
} while (cfs_rq);
p = task_of(se);
hrtick_start_fair(rq, p);
return p;
}
在这里,由于sched_entity是task_struct的属性,因此通过task_of(se)调用container_of可以由sched_entity找到task的位置。container_of是内核十分常见的函数了,也是C语言魅力的体现。
更进一步地,pick_next_entity()就是具体地CFS调度算法了,这部分内容可以回到《Linux内核设计与实现》中找到答案。在梳理清楚调度的整个流程后,我们进一步地去学习每个CFS调度算法才能更得心应手。这也是本篇文章的目的
何时调度
前半部分我们了解了schedule()执行一次进程调度的大致流程。那么该版本何时会触发schedule()进行调度呢?即类似0.12版本的时钟中断,timer_interrupt和do_timer的功能由哪些函数来实现?
本节内容参考了几个博文
Linux周期调度器
Linux调度系统分析
详解Linux内核进程调度函数schedule()的触发和执行时机
直接说结论:
主动调度:直接显式调用schedule()进行调度
被动调度(延时调度):系统调用返回或中断返回时,会检查进程的thread_info中的flag是否标记为TIF_NEED_RESCHED,若被设置,则意味着需要被调度,执行schedule()主调度器。而TIF_NEED_RESCHED可以由用户定义程序进行设置。
该版本的调度时机判断相较于0.12版本复杂了不少,需要通过标志位flag进行判断。在0.12版本中,进程被动调度一定要在当前进程时间片耗尽才能触发,这样导致其他进程无法抢占,实时交互需求无法满足。在2.6版本中,是否需要调度,只与当前进程标志位flag有关,因此可以自定义flag的设置算法,满足具体需求,来实现合理的调度策略。
设置重调度标志
最简单地,我们希望每次时钟中断都判断一下当前进程是否满足被调度条件,若满足,则把flag设置为TIF_NEED_RESCHED。下面,我们跟踪一下具体流程,可以看到update_process_times的注释提到其与timer interrupt关联,具体地再往前跟踪就涉及时钟管理内容,因此本文打算直接从该函数开始往后跟踪
kernel\timer.c
/*
* Called from the timer interrupt handler to charge one tick to the current
* process. user_tick is 1 if the tick is user time, 0 for system.
*/
void update_process_times(int user_tick)
{
struct task_struct *p = current;
int cpu = smp_processor_id();
/* Note: this timer irq context must be accounted for as well. */
account_process_tick(p, user_tick);
run_local_timers();
rcu_check_callbacks(cpu, user_tick);
printk_tick();
perf_event_do_pending();
scheduler_tick();
run_posix_cpu_timers(p);
}
进一步地,该函数调用了scheduler_tick()。该函数调用当前进程所在调度器的task_tick方法
kernel\sched.c
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
sched_clock_tick();
raw_spin_lock(&rq->lock);
update_rq_clock(rq);
update_cpu_load(rq);
curr->sched_class->task_tick(rq, curr, 0);
raw_spin_unlock(&rq->lock);
perf_event_task_tick(curr);
#ifdef CONFIG_SMP
rq->idle_at_tick = idle_cpu(cpu);
trigger_load_balance(rq, cpu);
#endif
}
我们以CFS公平调度器类为例,其task_tick为task_tick_fair(由上述fair_sched_class定义可知)
kernel\sched_fair.c
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &curr->se;
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
entity_tick(cfs_rq, se, queued);
}
}
该函数会进一步执行 entity_tick-->check_preempt_tick。在该函数中,设置了一些与CFS有关的条件,若满足则通过resched_task设置重调度标志位
kernel\sched_fair.c
//kernel\sched.c
static void resched_task(struct task_struct *p)
{
assert_raw_spin_locked(&task_rq(p)->lock);
set_tsk_need_resched(p);
}
static void
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
ideal_runtime = sched_slice(cfs_rq, curr);
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;
if (delta_exec > ideal_runtime) {
resched_task(rq_of(cfs_rq)->curr);
/*
* The current task ran long enough, ensure it doesn't get
* re-elected due to buddy favours.
*/
clear_buddies(cfs_rq, curr);
return;
}
/*
* Ensure that a task that missed wakeup preemption by a
* narrow margin doesn't have to wait for a full slice.
* This also mitigates buddy induced latencies under load.
*/
if (!sched_feat(WAKEUP_PREEMPT))
return;
if (delta_exec < sysctl_sched_min_granularity)
return;
if (cfs_rq->nr_running > 1) {
struct sched_entity *se = __pick_next_entity(cfs_rq);
s64 delta = curr->vruntime - se->vruntime;
if (delta > ideal_runtime)
resched_task(rq_of(cfs_rq)->curr);
}
}
至此,我们大概清楚了通过时钟中断设置进程重调度标志的流程
时钟中断执行程序调用update_process_times
update_process_times通过scheduler_tick调用当前进程所在调度器类的task_tick方法
在task_tick方法中,定义与调度有关的条件,判断是否满足条件来进行flag的设置
中断返回执行调度
另一方面,我们还要验证一下如中断返回时是否会根据flag标志执行schedule()
我们知道中断返回会调用ret_from_intr,其进一步调用resume_kernel
arch\x86\kernel\entry_32.S
ret_from_intr:
GET_THREAD_INFO(%ebp)
check_userspace:
movl PT_EFLAGS(%esp), %eax # mix EFLAGS and CS
movb PT_CS(%esp), %al
andl $(X86_EFLAGS_VM | SEGMENT_RPL_MASK), %eax
cmpl $USER_RPL, %eax
jb resume_kernel # not returning to v8086 or userspace
ENTRY(resume_kernel)
DISABLE_INTERRUPTS(CLBR_ANY)
cmpl $0,TI_preempt_count(%ebp) # non-zero preempt_count ?
jnz restore_all
need_resched:
movl TI_flags(%ebp), %ecx # need_resched set ?
testb $_TIF_NEED_RESCHED, %cl
jz restore_all
testl $X86_EFLAGS_IF,PT_EFLAGS(%esp) # interrupts off (exception path) ?
jz restore_all
call preempt_schedule_irq
jmp need_resched
END(resume_kernel)
resume_kernel则调用preempt_schedule_irq,可以看到,该函数会根据need_resched()执行schedule()。至此,验证完毕
kernel\sched.c
asmlinkage void __sched preempt_schedule_irq(void)
{
struct thread_info *ti = current_thread_info();
/* Catch callers which need to be fixed */
BUG_ON(ti->preempt_count || !irqs_disabled());
do {
add_preempt_count(PREEMPT_ACTIVE);
local_irq_enable();
schedule();
local_irq_disable();
sub_preempt_count(PREEMPT_ACTIVE);
/*
* Check again in case we missed a preemption opportunity
* between schedule and now.
*/
barrier();
} while (need_resched());
}
————————————————
版权声明:本文为CSDN博主「DaHuangXiao」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/m0_37637511/article/details/123971262