
通过对Titanic船上人员的信息来判断是否生还,已经明确过这是一个二元分类器。训练样本数据已经全部处理完,并保存在df变量中,接下来就可以训练模型进行数据训练。
接着就需要开始选择一个分类器进行训练了,目前先选择随机梯度下降(SGD)分类器。
训练模型
使用sklearn的SGDClassifier进行非常的方便,大致流程如下:
- 将Pandas转为Numpy
- 将输入和输出分别赋值给X,y
- 使用SGD分类器进行数据训练
- 获取训练结果的准确率和召回率
这段代码很短,具体如下所示:
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import precision_score, recall_score
train_df = df.filter(regex='Survived|Age|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
train_np = train_df.values
X, y = train_np[:, 1:], train_np[:, 0]
sgd_clf = SGDClassifier(random_state=67)
sgd_clf.fit(X, y)
y_pred = cross_val_predict(sgd_clf, X, y)
precision = precision_score(y, y_pred)
record = recall_score(y, y_pred)
print('Precision={} nRecord={} '.format(precision, record))运行后的结果为:
- Precision = 0.6036269430051814
- Record = 0.6812865497076024
从准确率和召回率上来看,这真的不是一个好结果,不过比起随机猜的0.5来说,已经能看到起了一定的作用。
预测结果
通过刚训练好的数据,对测试集预测Survived值。
不过考虑到在数据特征处理的过程中,已经对训练数据做了很多操作,那么对于测试数据,需要做的操作也是一样的,不过为了保险起见,先看一下测试数据样本。
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 418 non-null int64
1 Pclass 418 non-null int64
2 Name 418 non-null object
3 Sex 418 non-null object
4 Age 332 non-null float64
5 SibSp 418 non-null int64
6 Parch 418 non-null int64
7 Ticket 418 non-null object
8 Fare 417 non-null float64
9 Cabin 91 non-null object
10 Embarked 418 non-null object这时可以看到除了Age、Cabin有缺失值外,Embarked没有缺失,但是Fare有缺失。对于测试样本可不敢直接把缺失的扔掉,那么比起训练样本,我们对Fare也做一下填充操作吧。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelBinarizer
import sklearn.preprocessing as preproc
df_test = pd.read_csv('./data/test.csv')
def set_cabin_exist(cabin):
if cabin == cabin:
return 'Y'
else:
return 'N'
# OneHotEncoder
encoder = LabelBinarizer()
df_test['Cabin_Exist'] = df_test['Cabin'].apply(lambda cabin: set_cabin_exist(cabin))
cabin_1hot_enc = pd.get_dummies(df_test['Cabin_Exist'], prefix= 'Cabin')
embarked_1hot_enc = pd.get_dummies(df_test['Embarked'], prefix='Embarked')
sex_1hot_enc = pd.get_dummies(df_test['Sex'], prefix='Sex')
pclass_1hot_enc = pd.get_dummies(df_test['Pclass'], prefix='Pclass')
df_test.drop(['Name','Ticket','Cabin','Cabin_Exist','Embarked','Sex','PassengerId','Pclass'], axis=1, inplace=True)
df_test = pd.concat([df_test, cabin_1hot_enc, embarked_1hot_enc, sex_1hot_enc, pclass_1hot_enc], axis=1)
# MissValue
age_median = df_test['Age'].median()
df_test['Age'] = df_test['Age'].fillna(age_median)
fare_median = df_test['Fare'].median()
df_test['Fare'] = df_test['Fare'].fillna(fare_median)
# Standardization
df_test['Age'] = preproc.StandardScaler().fit_transform(df_test[['Age']])
df_test['Fare'] = preproc.StandardScaler().fit_transform(df_test[['Fare']])
df_test.head()当测试集已经处理完毕,那么就可以使用模型进行结果的预测了。
test = df_test.filter(regex='Age|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*').values
predictions = sgd_clf.predict(test)
result = pd.DataFrame({'PassengerId':df_test['PassengerId'].values, 'Survived':predictions.astype(np.int32)})
result.to_csv('./data/predictions.csv', index=False)最终的结果保存在predictions.csv文件中。
PassengerId,Survived
892,0
893,1
894,0
895,0
896,1
897,0
……提交结果
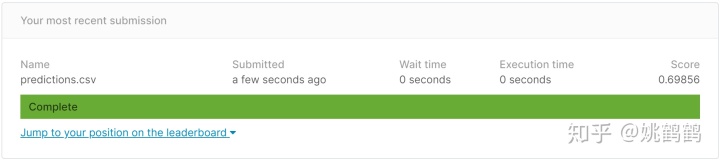
将结果的csv文件,通过Kaggle上传,可以看到最终预测Score为0.69856。
这样我们基本上走完了一个“Hello World”的流程,可是,这样的结果是否还有优化空间?如何选择训练模型?
这才刚刚开始!
版权声明:本文为weixin_39946534原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。