sklearn之Knn实战乳腺癌数据案例
(此处博主不细说Knn算法的基础逻辑,有兴趣可自行百度)
(导入的数据是sklearn自有的乳腺癌数据,sklearn有大量内置的数据,详细可点击sklearn数据集链接)
KNN建模的具体流程如下:
1.划分训练集,测试集
2.用训练集的最大值最小值归一化训练集及测试集
3.交叉验证得出最好的k
4.重新建模,训练训练集,测试测试集
from sklearn.datasets import load_breast_cancer
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
#对数据进行处理
data_breast=load_breast_cancer()
#提取数据的特征
X=data_breast['data']
#提取数据的标签
y=data_breast['target']
#划分数据集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
#数据归一化
from sklearn.preprocessing import MinMaxScaler
mms=MinMaxScaler()
mms.fit(X_train)
X_train=mms.transform(X_train)
X_test=mms.transform(X_test)
#数据交叉验证
from sklearn.model_selection import cross_val_score as csv
from sklearn.neighbors import KNeighborsClassifier
L=[]
for i in range (1,21):
k=i
knn=KNeighborsClassifier(n_neighbors=k,weights='distance')
result=csv(knn,X_train,y_train,cv=5)
L.append((k,result.mean(),result.var()))
L
# 画图观察交叉验证得到的k
a=pd.DataFrame(L)
a.columns=['k','平均准确率','方差']
plt.figure(figsize=(8,6),dpi=100)
plt.plot(a.k,a.平均准确率)
plt.plot(a.k,a.平均准确率+2*a.方差,linestyle='--',color='r')
plt.plot(a.k,a.平均准确率-2*a.方差,linestyle='--',color='r')
plt.xticks(a.k)
plt.xlabel('k')
plt.ylabel('平均准确率')
plt.title('带距离惩罚的5折交叉验证学习曲线')
图形显示为: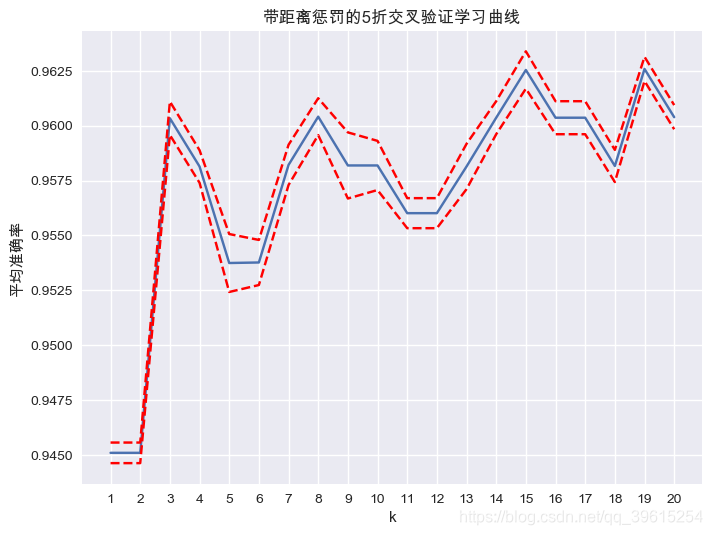
得出结果:k=15时模型效果最为稳定
建立一个k=15的knn模型
knn=KNeighborsClassifier(n_neighbors=15,weights='distance')
knn.fit(X_train,y_train)
#测试k=15时数据的好坏
knn.score(X_test,y_test)
最终显示结果为0.9649122807017544
得出结果:模型在测试集的正确率大约为96.5%。
建模完毕。
版权声明:本文为qq_39615254原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。