步骤
1.导入依赖
2.编写配置文件
3.数据准备
4.代码实现,结果观察
1.导入依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
2.编写配置文件
server:
port: 8888
spring:
shardingsphere:
#配置分库的数据源
datasource:
#配置分库的名称
names: ds0,ds1
ds0:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://xx.xx.222:3306/hospital?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone = GMT
password: KkZMWFy3DBJjkCH7
type: com.zaxxer.hikari.HikariDataSource
username: hospital
ds1:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://xxx.xxx.xx:3306/hospital2?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone = GMT
password: Kke4cbRfz6Ta2EHn
type: com.zaxxer.hikari.HikariDataSource
username: hospital2
props:
sql:
show: true #控制台打印sql 方便观察
sharding:
tables:
#要进行分片的表名称
cz_order:
database-strategy:
# 配置cz_order表分片规则以及分片键
inline:
sharding-column: sharding_id
#将cz_order表中的sharding_id字段作为分片键 将值取模
#计算出来余数是1或者0,然后进行字符串拼接 ds0 ds1
#对应上面的数据库源配置
algorithm-expression: ds$->{sharding_id%2}
3.数据准备工作
需要建立俩个数据库,同上在俩个库上建立同样的表
PS:分库 是指MYSQL服务器部署在不同的机器上,这里就是简单的演示,所以是部署在了同台机器上面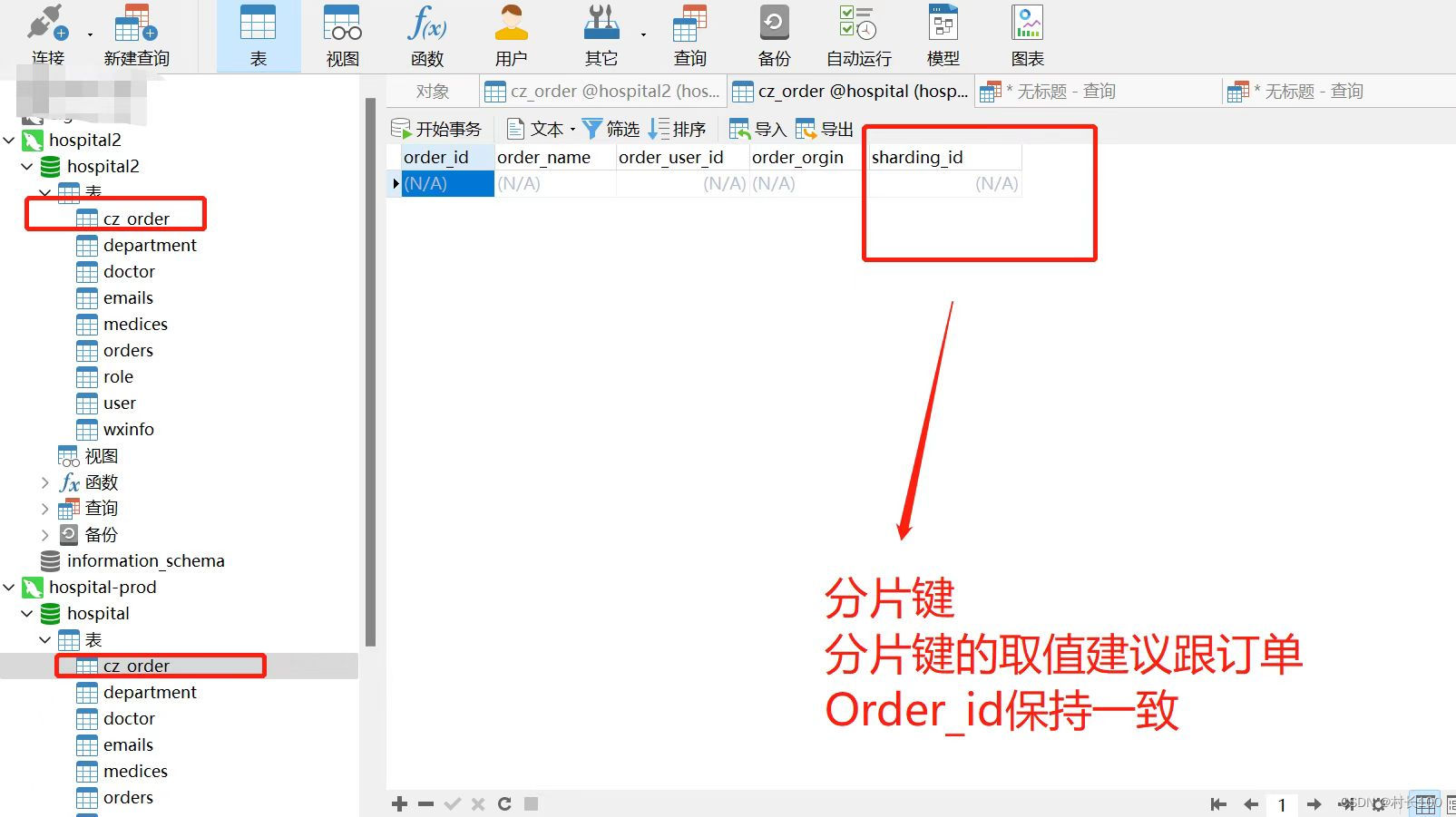
4.代码实现
代码的实现比较简单,跟常规的CRUD是一样的流程,对order表进行了配置,所以在查询的时候,会根据设置的分片规则去进行查询
1.场景1
查询不带任何条件,那么正常应该是去查询2个库,因为没有根据分片键来查,无法判断数据是落在那个库上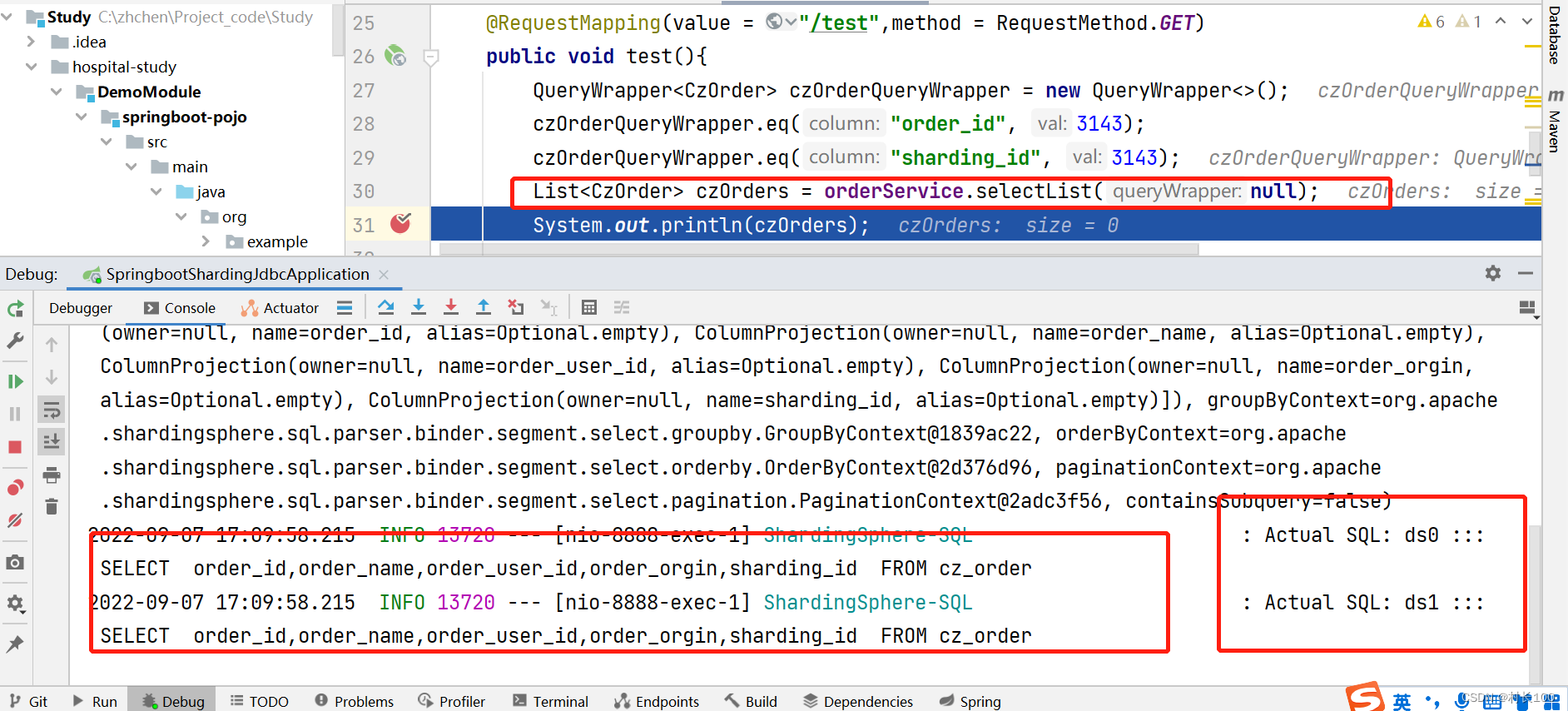
2.场景2
带上分片键查询,准确查询数据是落在那个库上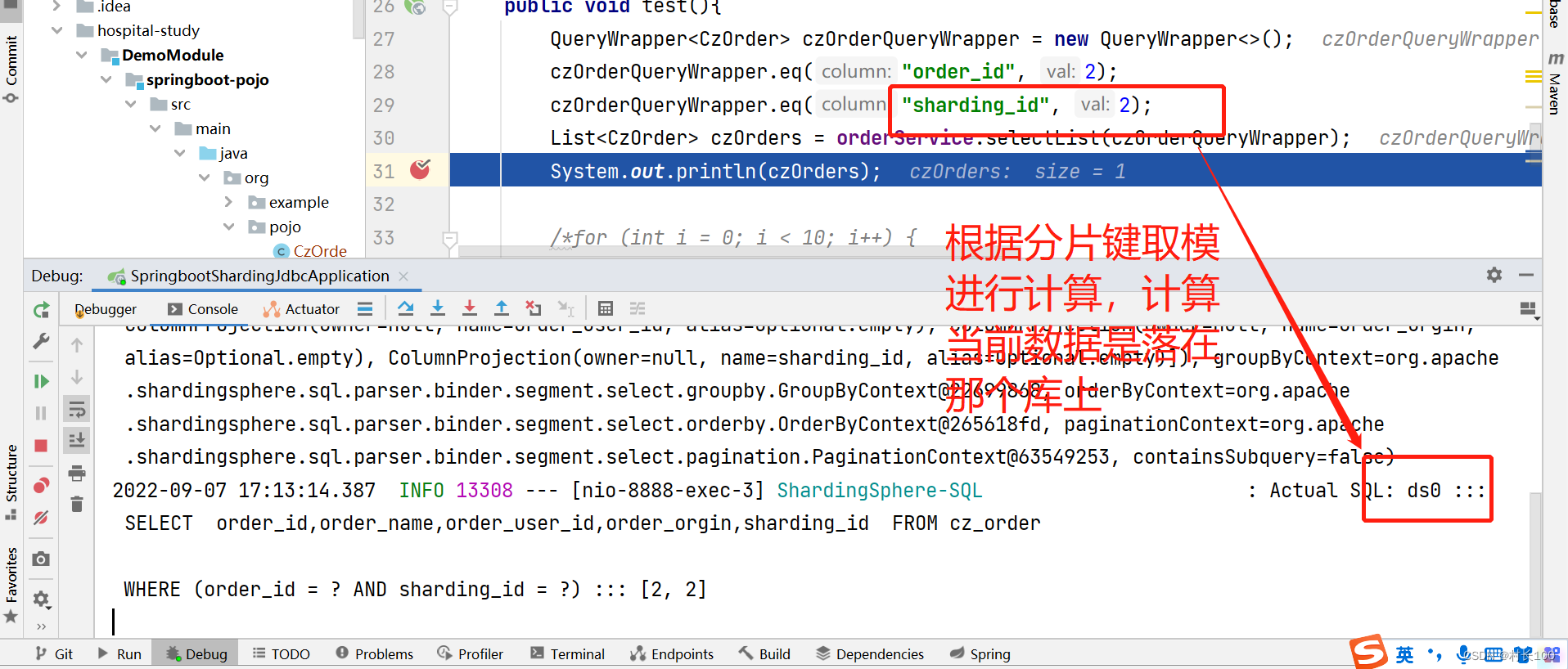
3.场景3
插入数据的时候带上分片键,根据配置的分片规则将数据散落在不同库的表上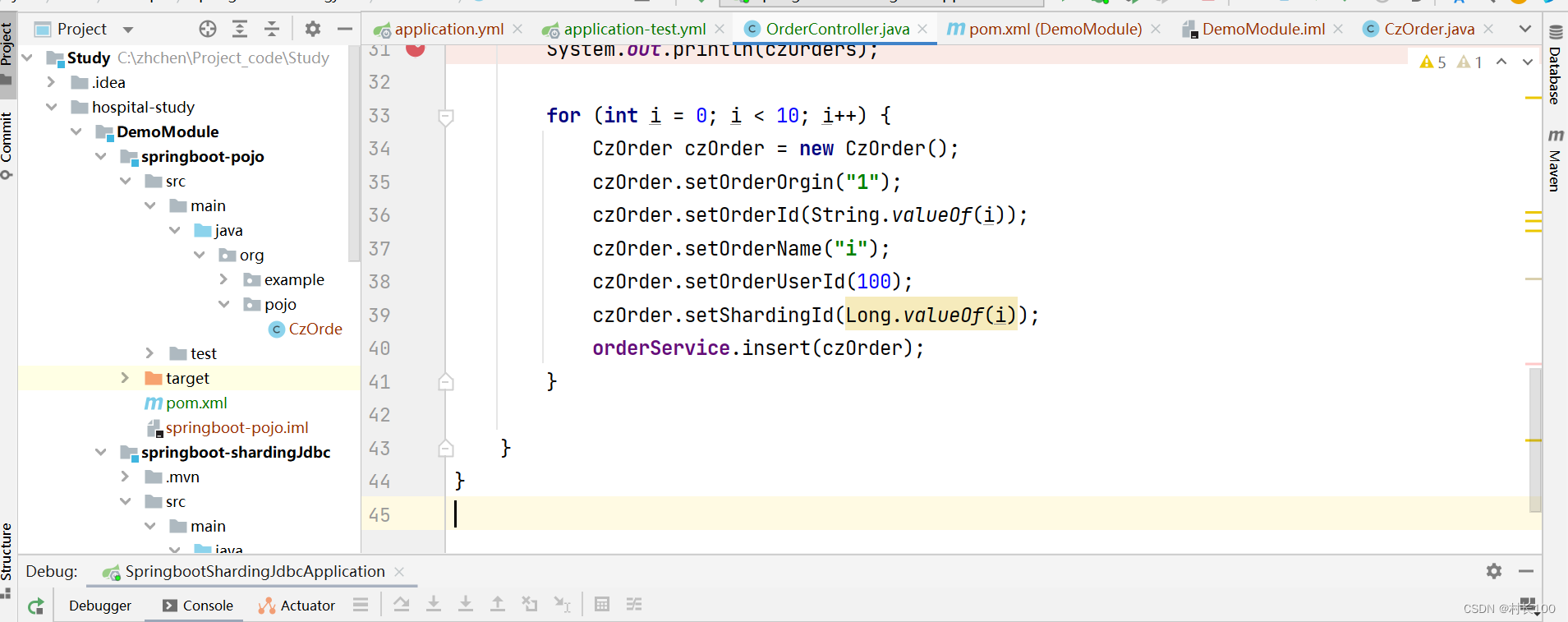
运行 查看结果
单数的落在一个库上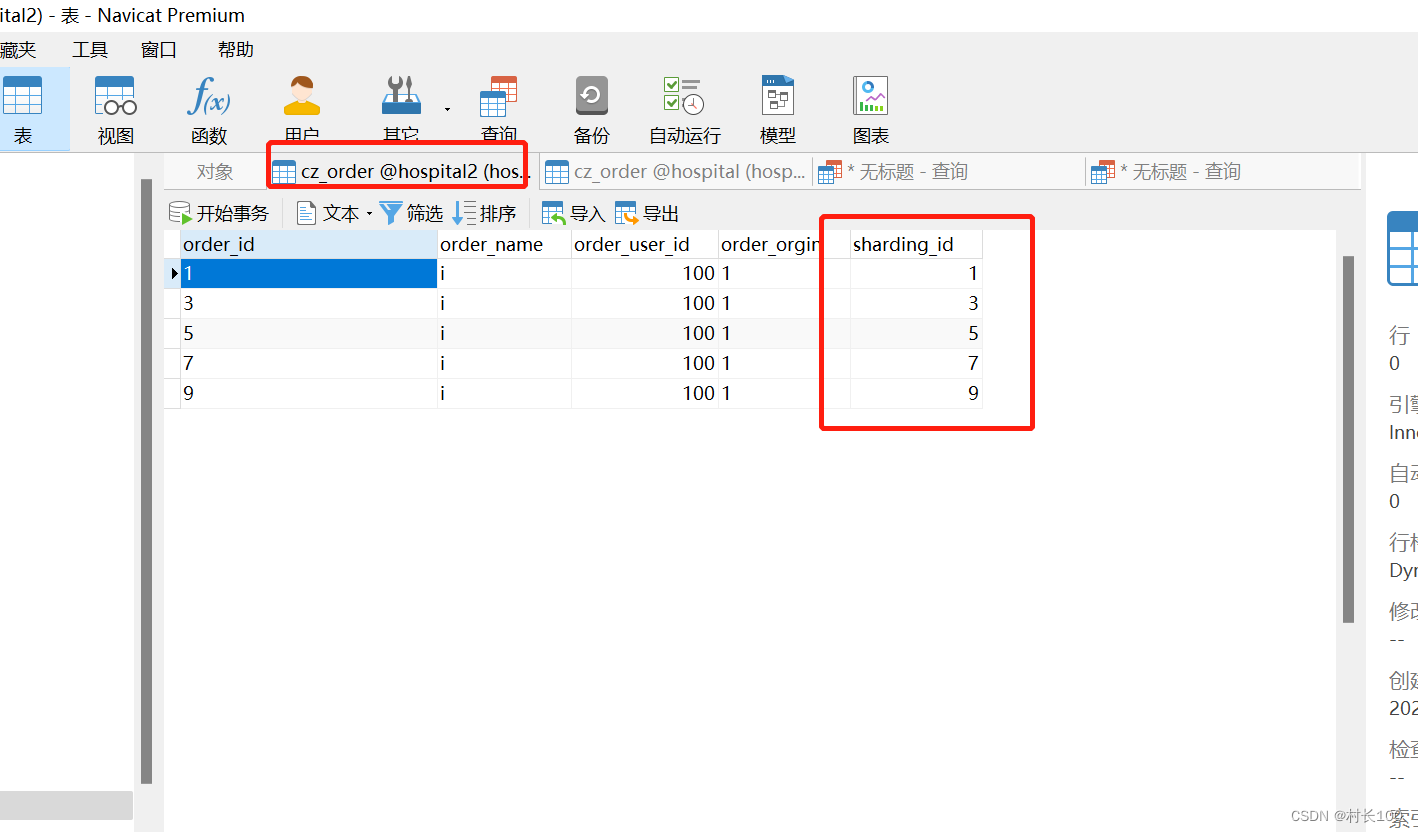
双数的落在一个库上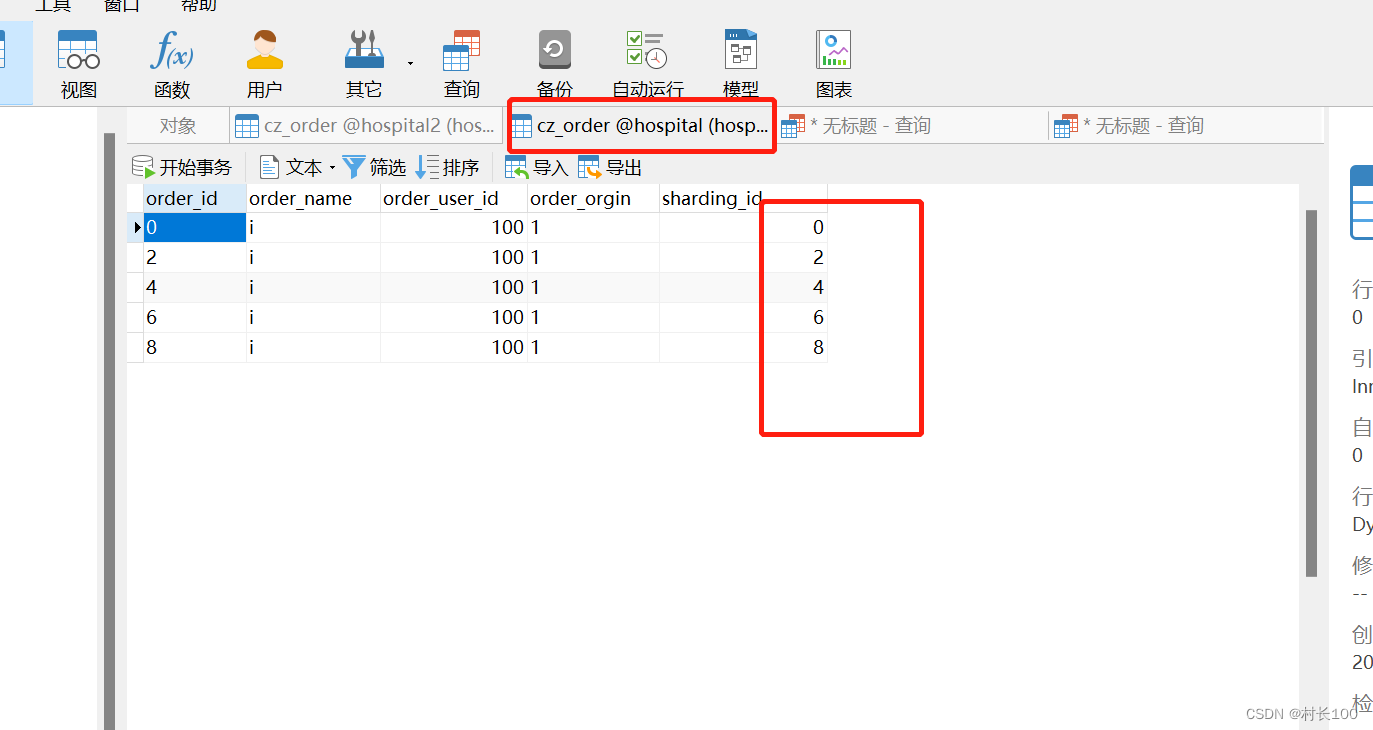
版权声明:本文为weixin_44130574原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。