1. GROUP BY语句
Group by从字面意义上理解就是根据”BY”指定的规则对数据进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。
聚合函数对组执行计算并返回每个组的唯一值。 例如, COUNT() 函数返回每个组中的行数。 其他常用的聚合函数是: SUM() , AVG() , MIN() , MAX() 。
GROUP BY子句的语法:
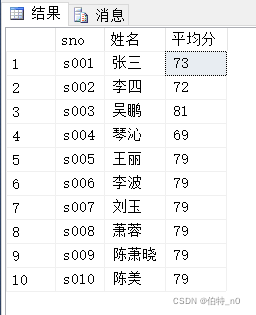
(1)avg()计算平均成绩
Select a.sno,a.sname姓名,avg(b.score) 平均成绩
From student as a
Left join
sc as b on a.sno=b.sno
Group by sname,a.sno;
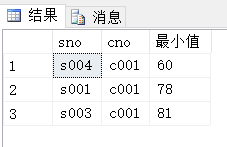
(2)min()查询”c001”最小值
Select sno,cno,min(score)最小值
From sc s
Where s.cno=’c001’
Group by sno,cno,score
Order by min(score) asc;
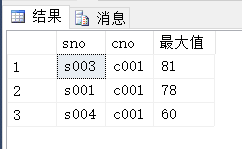
(3)max()查询”c001”最大值
Select sno,cno,max(score)最大值
From sc s
Where s.cno=’c001’
Group by sno,cno,score
Order by max(score) desc;
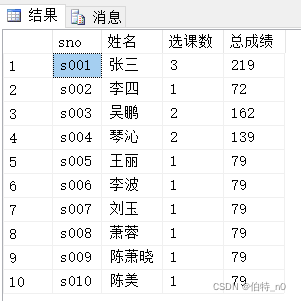
(4)sum()查询数据的总数
select a.sno,a.sname姓名,count(b.cno) 选课数,sum(b.score) 总成绩
from student as a
left join
sc as b on a.sno=b.sno
group by sname,a.sno;
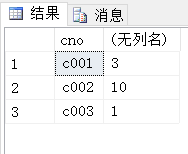
(5)count()查询每门课程被选修的学生数
select cno ,count(sno)
from sc
group by cno;
2.having 子句
Having子句通常与’group by’子句一起使用,一般having子句都是接’group by’子句后面;因为SQL Server在 GROUP BY 子句之后处理 HAVING 子句,所以不能通过使用列别名来引用选择列表中指定的聚合函数。所有必须明确使用 HAVING 子句中的聚合函数表达式。
“Having”是一个过滤声明,是在查询返回结果集以后对查询结果进行的过滤操作,在Having中可以使用聚合函数。