散列技术的基本思想
把记录(元素)的存储位置和该记录的关键字的值之间建立一种映射关系。关键字的值在这种映射关系下的像,就是相应记录在表中的存储位置。散列技术在理想情况下,无需任何比较就可以找到待查的关键字,其查找的期望时间为O(1)。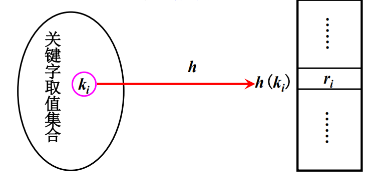
散列技术的相关概念
散列函数:
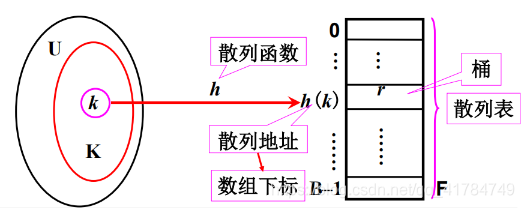
设 U 表示所有可能出现的关键字集合,K表示实际出现(实际存储)的关键字集合,即K 属于U,F[B – 1]是一个数组,其中B =O( | K| )。则,从 U 到表F[ B – 1]下标集合上的一个映射 h:U->{ 0, 1, 2, …,B –1}称为散列函数(哈希函数,杂凑函数)
散列表
数组 F 称为散列表(Hash表,杂凑表)。数组 F 中的每个单元称为桶(bucket)。
散列地址
对于任意关键字k∈U,函数值h ( k )称为 k 的散列地址(Hash地址,散列值,存储地址,桶号)
散列冲突(碰 撞)
将结点(记录)按其关键字的散列地址存储到散列表中的过程称为散列。 (collision)不同的关键字具有相同散列地址的现象称为散列冲突(碰 撞)。而发生冲突的两个关键字称为同义词(synonym)。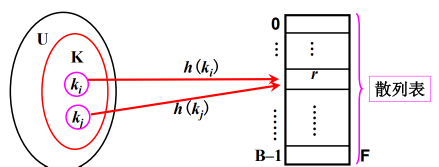
散列函数的构造
散列函数的构造的原则:
- 计算简单:散列函数不应该有很大的计算量,否则会降低查找效率。
- 分布均匀:散列函数值即散列地址,要尽量均匀分布在地址空间,这样才能保证存储空间的有效利用并减少冲突。
散列函数的构造方法
直接定址法
散列函数是关键字值的线性函数,即:h(key) = a * key + b (a,b为常数)
示例:关键字的取值集合为{10, 30, 50, 70, 80, 90},选取的散列函数为h(key)=key/10,则散列表为:
适用情况:事先知道关键字的值,关键字取值集合不是很、大且连续性较好。质数除余法
散列函数为:h(key)=key % m
一般情况下,选m为小于或等于表长B的最大质数。示例:关键字的取值集合为{14, 21, 28, 35, 42, 49, 56, 63},表长B=12。则选取m=11,散列函数为h(key)=key % 11,则散列表为:
适用情况:质数除余法是一种最简单、也是最常用的构造散列函数的方法,并且不要求事先知道关键码的分布。平方取中法
取 key^2 的中间的几位数作为散列地址
扩大相近数的差别,然后根据表长取中间几位作为散列值,使地址值与关键字的每一位都相关。
散列地址的位数要根据B来确定,有时要设一个比例因子,限制地址越界。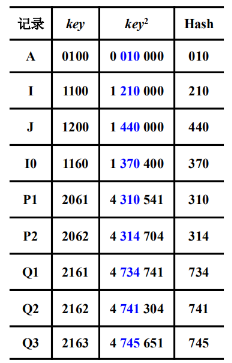
适用情况:事先不知道关键码的分布且关键码的位数不是很大折叠法
若关键字位数较多,可根据B的位数将关键字分割成位数相同的若干段(最后一段位数可以不同),然后将各段叠加和(舍去进位)作为散列地址。
示例:图书编号: 0-442-20586-4
适用情况:关键码位数很多,事先不知道关键码的分
布。数字分析法
根据关键字值在各个位上的分布情况,选取分布比较均匀的若干位组成散列地址。
示例:假设散列表长为100,可取中间四 位中的两位为散列地址。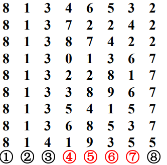
适用情况:若事先知道关键字集合,且关键字的位数比散列表的地址位数多
小结:构造Hash函数应注意以下几个问题:
计算简单
- 计算Hash函数所需时间
分布均匀:
- 关键字的长度
- 散列表的大小
- 关键字的分布情况
- 记录的查找频率
冲突处理的方法
开放定址法
基本思想:
当冲突发生时,使用某些探测技术在散列表中形成一个探测序列,沿此序列逐个单元查找,直到找到给定的关键字或者碰到一个开放地址(即该空的地址单元、空桶)或者既未找到给定的关键字也没碰到一个开放地址为止。
常用的探测技术----如何寻找下一个空的散列地址?
- 线性探测法
- 线性补偿探测法
- 二次探测法
- 随机探测法
线性探测法(c=1)
基本思想:当发生冲突时,从冲突位置的下一个位置起,依次寻找空的散列地址。
探测序列:设关键字值key的散列地址为h(key),闭散列表的长度为B,则发生冲突时,寻找下一个散列地址的公式为:hi=(h(key)+di) % B (di=1,2,…,m-1)
示例:关键字取值集合为 {47, 7, 29, 11, 16, 92, 22, 8, 3},散列函数为h(key)=key %11,用线性探测法处理冲突,则散列表为:
线性补偿探测法:
当发生冲突时,寻找下一个散列地址的公式为:hi=(h(key)+di) % B (di =1c,2c,…)
二次探测法:
当发生冲突时,寻找下一个散列地址的公式为:
hi=(h(key)+di) % B (di=12,-12,22,-22,…,q2,-q2且q≤B/2)
随机探测法
当发生冲突时,下一个散列地址的位移量是一个随机数列,即寻找下一个散列地址的公式为:hi=(h(key)+di) % B (其中,d1, d2, …,dB-1是1, 2, …, B-1的随机序列。)
注意:插入、删除和查找时,要使用同一个随机序列。
闭散列表:用开放定址法处理冲突得到的散列表叫闭散列表.
堆积现象:在处理冲突的过程中出现的非同义词之间对同一个散列地址争夺的现象。
带溢出表的内散列法
基本思想:扩充散列表中的每个桶,形成带溢出表的散列表。每个桶包括两部分:一部分是主表元素;另一部分或者为空或者由一个链表组成溢出表,其首结点的指针存入主表的链域。主表元素的类型与溢出表的类型相同。
示例:关键字取值集合为 {47, 7, 29, 11, 16, 92, 22, 8, 3},散列函数为h(key)=key %11,用带溢出表的内散列法处理冲突,则散列表为: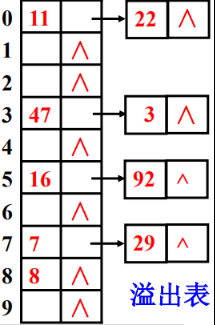
特点:
- 主表及其溢出表元素的散列地址相同。
- 空间利用率不高;
拉链法(链地址法)
基本思想:将所有散列地址相同的记录,即所有同义词的记录存储在一个单链表中(称为同义词子表),在散列表中存储的是所有同义词子表的头指针(桶)。
示例:关键字取值集合为 {47, 7, 29, 11, 16, 92, 22, 8, 3},散列函数为h(key)=key%11,用链地址法处理冲突,则散列表为: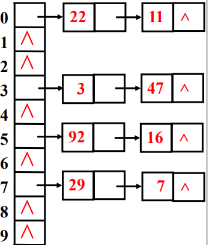
开散列表: 用拉链法处理冲突构造的散列表叫做开散列表。
散列查找的性能分析
由于冲突的存在,产生冲突后的查找仍然是给定值与关键码进行比较的过程。
在查找过程中,关键码的比较次数取决于产生冲突的概率。
而影响冲突产生的因素有:
- 散列函数是否均匀
- 处理冲突的方法
- 散列表的装载因子 α=表中填入的记录数/表的长度
几种不同处理冲突方法的平均查找长度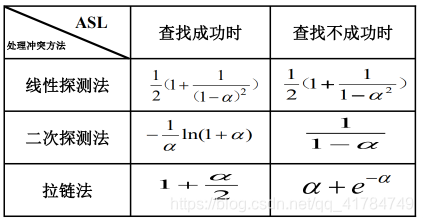
开散列表与闭散列表的比较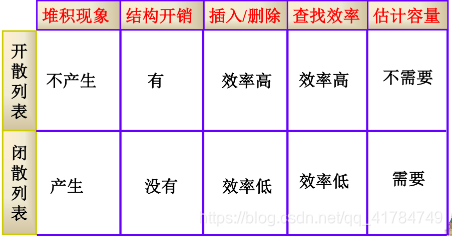
代码实现带溢出表的内散列法
import java.util.Scanner;
/**
* @anthor longzx
* @create 2021 01 30 16:19
* @Description
**/
public class HashTabDemo {
public static void main(String[] args) {
//创建哈希表
HashTab hashTab = new HashTab(7);
//写一个简单的菜单
String key = "";
Scanner scanner = new Scanner(System.in);
while(true) {
System.out.println("add: 添加雇员");
System.out.println("del: 删除雇员");
System.out.println("list: 显示雇员");
System.out.println("find: 查找雇员");
System.out.println("exit: 退出系统");
key = scanner.next();
switch (key) {
case "add":
System.out.println("输入id");
int id = scanner.nextInt();
System.out.println("输入名字");
String name = scanner.next();
//创建 雇员
Emp emp = new Emp(id, name);
hashTab.add(emp);
break;
case "del":
System.out.println("输入id");
int id2 = scanner.nextInt();
hashTab.del(id2);
break;
case "list":
hashTab.list();
break;
case "find":
System.out.println("请输入要查找的id");
id = scanner.nextInt();
hashTab.findEmpById(id);
break;
case "exit":
scanner.close();
System.exit(0);
default:
break;
}
}
}
}
//创建HashTab 管理多条链表
class HashTab {
private EmpLinkedList[] empLinkedListArray;
private int size; //表示有多少条链表
//构造器
public HashTab(int size) {
this.size = size;
//初始化empLinkedListArray
empLinkedListArray = new EmpLinkedList[size];
//?留一个坑, 这时不要分别初始化每个链表
for(int i = 0; i < size; i++) {
empLinkedListArray[i] = new EmpLinkedList();
}
}
//添加雇员
public void add(Emp emp) {
//根据员工的id ,得到该员工应当添加到哪条链表
int empLinkedListNO = hashFun(emp.id);
//将emp 添加到对应的链表中
empLinkedListArray[empLinkedListNO].add(emp);
}
//删除雇员
public void del(int id) {
//根据员工的id ,得到该员工应当添加到哪条链表
int empLinkedListNO = hashFun(id);
//将emp 添加到对应的链表中
empLinkedListArray[empLinkedListNO].delete(id);
}
//遍历所有的链表,遍历hashtab
public void list() {
for(int i = 0; i < size; i++) {
empLinkedListArray[i].list(i);
}
}
//根据输入的id,查找雇员
public void findEmpById(int id) {
//使用散列函数确定到哪条链表查找
int empLinkedListNO = hashFun(id);
Emp emp = empLinkedListArray[empLinkedListNO].findEmpById(id);
if(emp != null) {//找到
System.out.printf("在第%d条链表中找到 雇员 id = %d\n", (empLinkedListNO + 1), id);
}else{
System.out.println("在哈希表中,没有找到该雇员~");
}
}
//编写散列函数, 使用一个简单取模法
public int hashFun(int id) {
return id % size;
}
}
//创建EmpLinkedList ,表示链表
class EmpLinkedList {
//头指针,执行第一个Emp,因此我们这个链表的head 是直接指向第一个Emp
private Emp head; //默认null
//添加雇员到链表
//说明
//1. 假定,当添加雇员时,id 是自增长,即id的分配总是从小到大
// 因此我们将该雇员直接加入到本链表的最后即可
public void add(Emp emp) {
//如果是添加第一个雇员
if(head == null) {
head = emp;
return;
}
//如果不是第一个雇员,则使用一个辅助的指针,帮助定位到最后
Emp curEmp = head;
while(true) {
if(curEmp.next == null) {//说明到链表最后
break;
}
curEmp = curEmp.next; //后移
}
//退出时直接将emp 加入链表
curEmp.next = emp;
}
//删除
//根据雇员ID删除雇员信息
public void delete(int id){
if(head == null) { //说明链表为空
System.out.println("链表为空");
return;
}
if(head.id == id){
head =head.next;
System.out.println("删除雇员成功");
return;
}
//辅助指针
Emp curEmp = head;
while(true) {
if(curEmp.next.id == id) {//找到
curEmp.next = curEmp.next.next;
System.out.println("删除雇员成功");
break;//这时curEmp就指向要查找的雇员
}
//退出
if(curEmp.next == null) {//说明遍历当前链表没有找到该雇员
System.out.println("未找到待删除的信息");
break;
}
curEmp = curEmp.next;//以后
}
}
//遍历链表的雇员信息
public void list(int no) {
if(head == null) { //说明链表为空
System.out.println("第 "+(no+1)+" 链表为空");
return;
}
System.out.print("第 "+(no+1)+" 链表的信息为");
Emp curEmp = head; //辅助指针
while(true) {
System.out.printf(" => id=%d name=%s\t", curEmp.id, curEmp.name);
if(curEmp.next == null) {//说明curEmp已经是最后结点
break;
}
curEmp = curEmp.next; //后移,遍历
}
System.out.println();
}
//根据id查找雇员
//如果查找到,就返回Emp, 如果没有找到,就返回null
public Emp findEmpById(int id) {
//判断链表是否为空
if(head == null) {
System.out.println("链表为空");
return null;
}
//辅助指针
Emp curEmp = head;
while(true) {
if(curEmp.id == id) {//找到
break;//这时curEmp就指向要查找的雇员
}
//退出
if(curEmp.next == null) {//说明遍历当前链表没有找到该雇员
curEmp = null;
break;
}
curEmp = curEmp.next;//以后
}
return curEmp;
}
}
//表示一个雇员
class Emp {
public int id;
public String name;
public Emp next; //next 默认为 null
public Emp(int id, String name) {
super();
this.id = id;
this.name = name;
}
}