Apache Impala 介绍以及优劣处
-------------------------------------------------------------------------------------------------------- 东子
1.Impala基本介绍
impala是cloudera提供的一款高效率的sql查询工具,提供实时的查询效果,官方测试性能比hive快10到100倍,其sql查询比sparkSQL还要更加快速,号称是当前大数据领域最快的查询sql工具,
- impala是参照谷歌的新三篇论文(Caffeine–网络搜索引擎、Pregel–分布式图计算、Dremel–交互式分析工具)当中的Dremel实现而来,其中旧三篇论文分别是(BigTable,GFS,MapReduce)分别对应我们即将学的HBase和已经学过的HDFS以及MapReduce。
- impala是基于hive并使用内存进行计算,兼顾数据仓库,具有实时,批处理,多并发等优点。
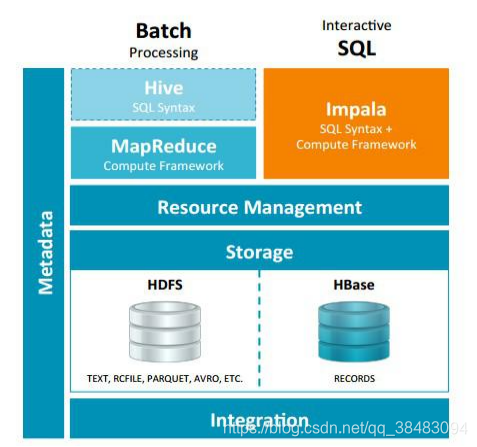
2.Impala与Hive关系 - impala是基于hive的大数据分析查询引擎,直接使用hive的元数据库metadata,意味着impala元数据都存储在hive的metastore当中,并且impala兼容hive的绝大多数sql语法。所以需要安装impala的话,必须先安装hive,保证hive安装成功,并且还需要启动hive的metastore服务。
- Hive元数据包含用Hive创建的database、table等元信息。元数据存储在关系型数据库中,如Derby、MySQL等。
- 客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore
服务即可。
nohup hive --service metastore >> ~/metastore.log 2>&1 &
3.impala和hive的区别
- 执行机制
hive: hive sql–>mr—>yarn—>hdfs
最大的弊端在于mr执行中资源申请消耗数据之间的shuffle。尤其涉及多个mr程序串联 影响会放大
impala:impala sql–>执行计划数–>hdfs
- 语言层面
hive:java 依赖于jvm 涉及启动销毁 属于偏上层语言。
impala: C++ 偏向于底层语言 可以更好的调用系统资源
- 数据流
hive :推的方式 前述节点计算完毕数据退给后续节点计算
impala:拉的方式 不断调用获取前述节点的计算结果 边拉边计算
- 内存
hive优先使用内存 如果不足 使用外存(磁盘)
impala当下只用内存 内存不足报错 通常去配合hive使用。
- 调度
hive 资源调度是用yarn完成
impala 自己调度 策略极其简单
- 容错
hive容错准备来说就是hadoop容错机制 task重试机制 推测执行机制
impala没有容错能力 设计的时候认为 错了再来也会很快 再执行的成本低
- 适用层面
hive适用于复杂的批处理任务分析
impala适用于交互式实时任务处理 通常要hive使用
4.Impala的特点
- 1、基于内存进行计算,能够对PB级数据进行交互式实时查询、分析
- 2、无需转换为MR,直接读取HDFS及Hbase数据 ,从而大大降低了延迟。
Impala没有MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query
Coordinator和Query Exec Engine三部分组成 - 3、C++编写,LLVM统一编译运行 在底层对硬件进行优化, LLVM:编译器,比较稳定,效率高
- 4、兼容HiveSQL 支持hive基本的一些查询等,hive中的一些复杂结构是不支持的
- 5、具有数据仓库的特性,可对hive数据直接做数据分析
- 6、支持Data Local 数据本地化:无需数据移动,减少数据的传输
- 7、支持列式存储 可以和Hbase整合:因为Hive可以和Hbasez整合
- 8、支持JDBC/ODBC远程访问
二、Impala架构
1、Impala的核心组件
- Statestore Daemon
负责收集分布在集群中各个impalad进程的资源信息、各节点健康状况,同步节点信息 负责query的调度 - Catalog Daemon
从Hive元数据库中同步元数据,分发表的元数据信息到各个impalad中 接收来自statestore的所有请求 - impala版本1.2之后开始有的,不是很只能,有些元数据信息并不能同步到各个impalad的,例如hive中创建表,Catalog
Daemon不能同步,需要在imapala手动执行命令同步。 - Impala Daemon(impalad) <具有数据本地化的特性所以放在DataNode上>
接收client、hue、jdbc或者odbc请求、Query执行并返回给中心协调节点 子节点上的守护进程,负责向statestore保持通信,汇报工作 - Impala daemon:执行计算。因内存依赖大,所最好不要和imapla的其他组件放到同意节点
- 考虑集群性能问题,一般将StateStoreDaemon与 Catalog Daemon放在统一节点上,因之间要做通信
版权声明:本文为qq_38483094原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。