编写脚本为了方便使用hadoop集群
前提:搭建好一个完整的hadoop集群
- 创建一个存放脚本的目录
这里创建了一个bin目录来存放脚本文件
[hadoop@node01 ~]$ cd
[hadoop@node01 ~]$ mkdir bin
[hadoop@node01 ~]$ pwd
/home/hadoop
[hadoop@node01 ~]$ cd /home/hadoop/bin/
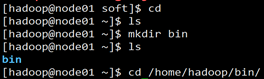
- 在node01下创建脚本

脚本内容入下
#!/bin/bash
case $1 in
"start" ){
source /etc/profile;
/zjy/install/hadoop-3.3.0/sbin/start-dfs.sh
/zjy/install/hadoop-3.3.0/sbin/start-yarn.sh
/zjy/install/hadoop-3.3.0/sbin/mr-jobhistory-daemon.sh start historyserver
};;
"stop"){
/zjy/install/hadoop-3.3.0/sbin/stop-dfs.sh
/zjy/install/hadoop-3.3.0/sbin/stop-yarn.sh
/zjy/install/hadoop-3.3.0/sbin/mr-jobhistory-daemon.sh stop historyserver
};;
esac
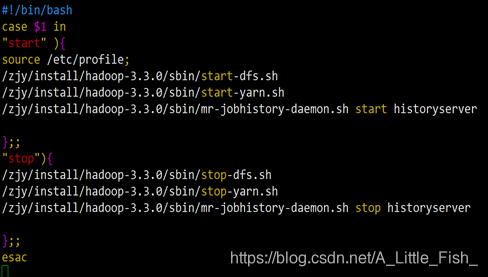
注意hadoop下文件安装路径
- 赋予脚本文件权限
[hadoop@node01 bin]$ chmod 777 hadoop.sh

- 最后输入命令启动hadoop集群验证是否成功
[hadoop@node01 bin]$ hadoop.sh start
[hadoop@node01 bin]$ jps
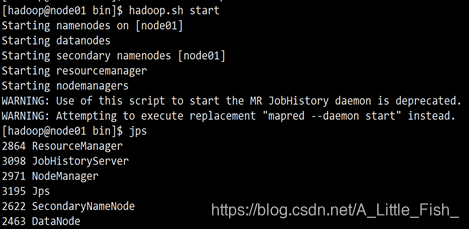
运行成功。
运用脚本文件关闭hadoop集群的命令是
[hadoop@node01 bin]$ hadoop.sh stop
版权声明:本文为A_Little_Fish_原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。