这里写目录标题
一、召回阶段
1.1基于热门的召回
筛选用户播放歌曲的行为数据,
选取播放次数最多的歌曲作为热门歌曲,为每个用户进行推荐
1.2基于用户分群的召回
将用户划分为细粒度群体,为每一个用户群体筛选歌
曲播放行为,选取每个群体中的热门歌曲,为每一个
用户进行推荐
可以使用KMeans等聚类算法
1.3基于协同过滤的召回
二、协同过滤算法(计算相似的一种方式)
2.1基于用户(user-based)的协同过滤算法
首先计算用户与用户之间的相似性,
然后再计算其他与目标相似的用户对物品的评分来为目标用户推荐
2.2基于物品的(item-based)的协同过滤算法
与基于用户的协同过滤算法基本相似
2.3基于模型(model-based)的协同过滤算法
SVD矩阵分解协同过滤算法
LFM隐含语义协同过滤算法
ALS交替最小二乘协同过滤算法
三、协同过滤
依赖用户行为数据
分析用户行为数据,求出
用户与用户之间的相似度,进而通过相似度计算出用户对所有物品的”感兴趣程度”(user-based)
物品与物品之间的相似度,进而通过相似度计算出用户对所有物品的”感兴趣程度”(item-based)
中间矩阵,进而通过中间矩阵计算出用户对所有物品的”感兴趣程度”(model-based)
四、基于用户的协同过滤
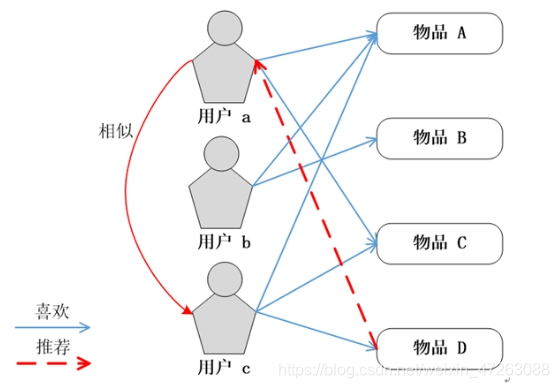
根据用户行为数据,获取用户对物品的喜欢程度评分,同时用户无法对所有物品都进行评分,最终可组织成一个用户-物品稀疏矩阵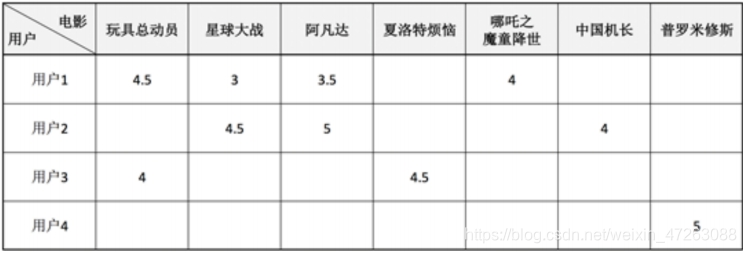
计算用户之间的相似程度,通过用户向量,按照余弦相似度公式进行求解

上面是向量点积
上面是是向量的模积
将用户一看出一个向量u1=[4.5,3,3.5,0,4,0];
将用户二看成一个向量u2=[0,4.5,5,0,0,4,0];
用户没有对物品进行评分回默认为0,但是可以对默认的没有评分的物品用平均数代替
余弦相似度的scala代码实现:
object cosine_similarity {
//向量的模
def module(vec: Vector[Double]) = {
math.sqrt(vec.map(math.pow(_, 2)).sum)
}
//向量的点积
def innerProduct(v1: Vector[Double], v2: Vector[Double]) = {
val listBuffer = ListBuffer[Double]()
for (i <- 0 until v1.length; j <- 0 to v2.length; if i == j) {
if (i == j) listBuffer.append(v1(i) * v2(j))
}
listBuffer.sum
}
def cosvec(v1: Vector[Double], v2: Vector[Double]) = {
val cos = innerProduct(v1, v2) / (module(v1) * module(v2))
if (cos <= 1) cos else 1.0
}
def main(args: Array[String]): Unit = {
var vec1 = Vector(4.5, 3, 3.5, 0, 4, 0, 0)
var vec2 = Vector(0, 4.5, 5, 0, 0, 4, 0)
var similarity = cosvec(vec1,vec2)
println("vec1与vec2的余弦相似度为:")
println(similarity)
}
}
使用余弦相似度构造用户-用户相似度矩阵
求解用户两两之间的相似度,可以得到如下相似度矩阵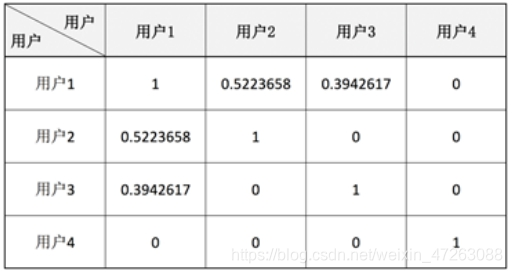
为目标用户推荐物品时,选取与目标用户最相似的前K个用户,选取目标用户没有进行过评分的物品n,将K个相似用户对n个物品的评分进行加权,认为该评分为目标用户对n个物品的预测评分
sim(u,v)表示目标用户与用户的相似性,
R(vi)表示用户对商品的真实评分
用户1对商品预测评分
=(sim(用户1,用户2)*用户2对该商品的真实评分+sim(用户1,用户3)*用户3对该商品的真实评分+sim(用户1,用户4)*用户4对该商品的真实评分)/(sim(用户1,用户2)+sim(用户1,用户3)+sim(用户1,用户4))
最后对n个物品预测评分进行倒排,优先推荐
协同过滤实际是通过分析用户行为数据,对原始user-item稀疏矩阵进行”填充”的过程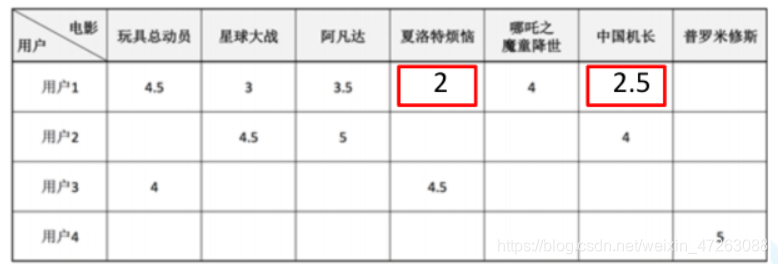
五、ALS(交替最小二乘法)
ALS算法是2008年以来,用的比较多的协同过滤算法,它已经集成到Spark的Mllib库中,从协同过滤的分类来说,它属于基于模型的协同过滤,它的核心思想同样是对User-Item稀疏矩阵进行”填充”,从而获得User对所有Item的感兴趣程度
5.1 ALS原理
假设有一批用户行为数据,其中包含m个User和n个Item,构建User-Item矩阵(稀疏矩阵),其中的元素表示第u个User对第i个Item的评分
蓝色为已经评分
灰色为未评分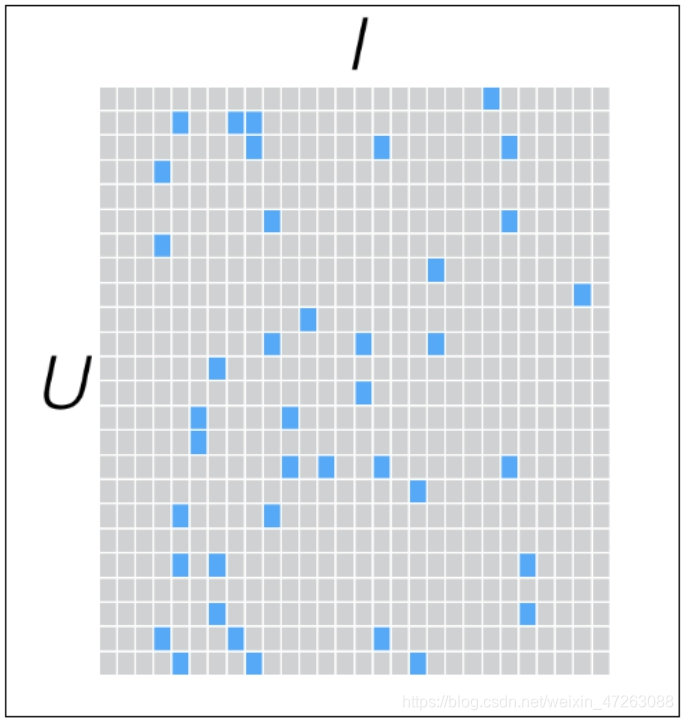
ALS会将User-Item矩阵分解为两个矩阵:User-Embedding_K矩阵和Embedding_K-Item矩阵(Embedding_K是超参数,自己设置),两个矩阵相乘能刚好得到User-Item矩阵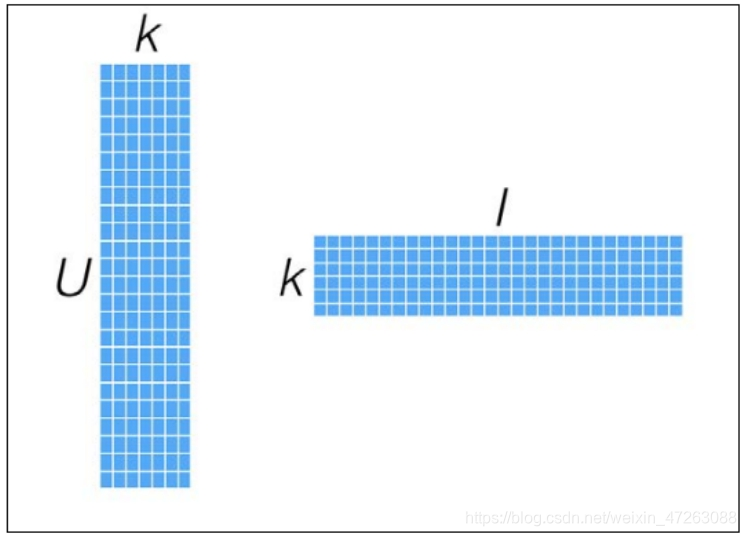
将User-Item稀疏矩阵中蓝色的值作为训练集,User-Embedding,Embedding-Item矩阵为稠密矩阵,并且矩阵中所有的值都在机器学习任务中当作参数,需要通过机器学习训练得出,损失函数由User-Embedding,Embedding-Item矩阵的点积和训练集的值求RMSE得出,优化方法使用ALS交替最小二乘法进行损失函数优化,最终求得User-Embedding,Embedding-Item矩阵,这样就可以得到稠密的User-Item矩阵
六、协同过滤的“评分策略”
User-item矩阵的评分是主观设定
项目中的设定为:
播放=>1分,下载=>2分,分享=>3分,收藏=>4分
最终在全局做一次评分归一化得出最终评分(将总得分处理到0~1之间)
通常评分策略由懂业务、模型开发、项目经理等人参与制定
调整评分策略是优化召回算法的一个非常重要的途径