一,二 待更新...
三. volatile关键字
能够保证线程可见性,当一个线程修改共享变量时,能够保证对另外一个线程可见性, 但是注意他不能够保证共享变量的原子性问题,在学习volatile之前我们先来看一段代码:
public class MyVolatile extends Thread {
private volatile static boolean flag = true;
@Override
public void run() {
while (flag) {
}
}
public static void main(String[] args) throws InterruptedException {
new MyVolatile().start();
Thread.sleep(1000);
flag = false;
}
}运行结果描述:不加volatile关键字则main线程执行完后子线程还会一直运行(IDEA红灯一直亮),而加上了volatile关键字后主线程把flag设置为false后,会把共享变量flag的值刷新到子线程,从而优雅的停止子线程。
没了解过volatile的小伙伴一定觉得很神奇,那么volatile是如何保证内存可见性的呢?那么接下来让我一探究竟~
说到内存可见性就必须要提到Java的内存模型,如下图所示:
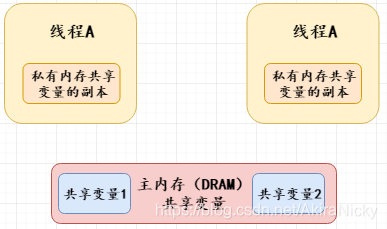
Java内存模型(JMM)规定,将所有的变量都存放在主内存中,当线程使用变量时,会把主内存里面的变量复制到自己的工作内存(即上图私有内存共享变量的副本),线程读写变量时操作的都是自己的工作内存中的变量;当一个线程操作共享变量时,它首先从主内存复制共享变量到自己的工作内存,然后对工作内存里的变量进行处理,处理完成后将变量值更新到主内存。
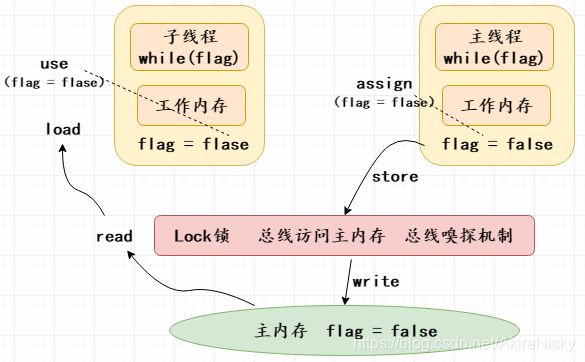
JMM执行流程
read(读取):作用于主内存变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的load动作使用
load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。
use(使用):作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作。
assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋值给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
store(存储):作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的write的操作。
write(写入):作用于主内存的变量,它把store操作从工作内存中一个变量的值传送到主内存的变量中。
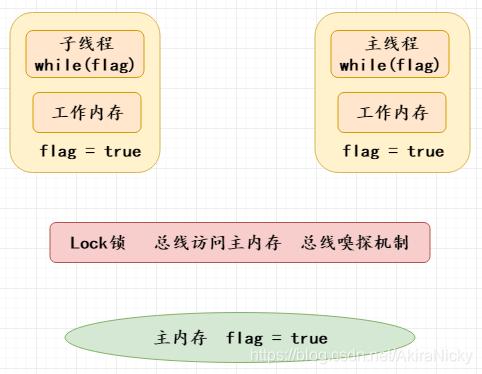
拿上面代码为例,刚开始主线程和子线程的flag都为true如下图所示(纯手画):
程序进行到第13行,主线程把flag改为flase,JMM执行流程如下:
那么问题来了,中间那层总线嗅探机制是干嘛用的? 接下来让我们来分析一下:
总线作用:解决cpu高速缓存副本数据之间一致性问题
volatile底层实现原理:通过汇编指令触发lock锁的机制,锁的机制分为两种:总线锁,MESI协议。
【总线锁】:当一个cpu(线程)访问到我们主内存中的数据时候,往总线总发出一个Lock锁的信号,其他的线程不能够对该主内存做任何操作,变为阻塞状态。该模式,存在非常大的缺陷,就是将并行的程序,变为串行,没有真正发挥出cpu多核的好处(早期的cpu才有)
【MESI协议】:
M 修改 (Modified): 这行数据有效,数据被修改了,和主内存中的数据不一致,数据只存在于本Cache中(如果当前cpu副本数据如果与主内存中的数据不一致的情况下,则当前cpu状态为M)
E 独享、互斥 (Exclusive): 这行数据有效,数据和主内存中的数据一致,数据只存在于本Cache中(单核cpu线程的情况下,cpu副本数据与主内存数据如果保持一致的情况下,则该cpu状态为E状态独享)
S 共享 (Shared) :这行数据有效,数据和主内存中的数据一致,数据存在于很多Cache中(多核cpu线程的情况下,每个cpu副本之间数据如果保持一致的情况下,则当前cpu状态为S)
I 无效 (Invalid) :这行数据无效(多线程的情况下,如果主内存的共享变量值由线程A修改发生了改变,则会通知除了线程A的其它线程cpu状态变为I无效状态)
总结:拿上面代码举例,最开始flag为true,则主线程和子线程的状态均为S状态;主线程把flag改为false,主线程状态变为M,并把结果刷新到主内存flag变为false,此时总线嗅探机制会通知其它线程把每个工作内存的状态变为I,然后其它线程主动读取主内存的新值并刷新到工作内存中,此时主线程和子线程的flag均为false,从而状态又回到S状态。
volatile为什么不能保证原子性?
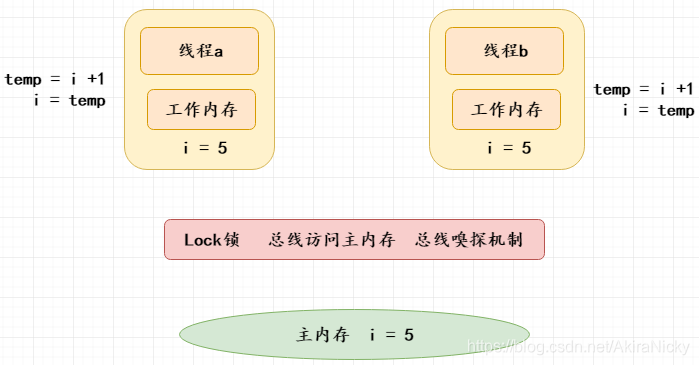
如上图所示,一个方法有3个操作:读取全局共享变量i,temp = i +1,i = temp;首先,i值初始化为5,线程a,b分别读取主内存i=5到工作内存,然后线程a执行了temp = i + 1的操作, 要注意,此时的 i 的值还没有变化,然后线程b也执行了 temp = i + 1的操作;此时线程a,b保存的i的值都是5,temp 的值都是6;然后线程a执行了i = temp(6)的操作,此时i的值会立即刷新到主存并通知其他线程保存的 i 值失效(总线),线程b需要重新读取主内存中 i 的值并更新到工作内存,那么此时线程b保存的i值为6,temp还仍然是6,然后线程b执行i = temp(6),所以导致了计算结果比预期少了1。
volatile关键字与双重检验锁
在实现单例模式时,如果未考虑多线程的情况,就容易写出下面的错误代码:
public class Singleton {
private static Singleton uniqueSingleton;
private Singleton() {
}
public Singleton getInstance() {
if (null == uniqueSingleton) {
uniqueSingleton = new Singleton();
}
return uniqueSingleton;
}
}在多线程的情况下,这样写可能会导致uniqueSingleton有多个实例,出现这种情况,第一反应就是加锁,如下:
public class Singleton {
private static Singleton uniqueSingleton;
private Singleton() {
}
public synchronized Singleton getInstance() {
if (null == uniqueSingleton) {
uniqueSingleton = new Singleton();
}
return uniqueSingleton;
}
}这样虽然解决了问题,但是因为用到了synchronized,会导致很大的性能开销,并且加锁其实只需要在第一次初始化的时候用到,之后的调用都没必要再进行加锁。
双重检查锁是对上述问题的一种优化。先判断对象是否已经被初始化,再决定要不要加锁。
public class Singleton {
// 使用了volatile关键字后,重排序被禁止,所有的写(write)操作都将发生在读(read)操作之前。
private volatile static Singleton uniqueSingleton;
private Singleton() {
}
public Singleton getInstance() {
// 如果把第一次判断去掉,则频繁进入synchronized,会导致很大的性能开销
if (null == uniqueSingleton) {
synchronized (Singleton.class) {
if (null == uniqueSingleton) {
uniqueSingleton = new Singleton();
}
}
}
return uniqueSingleton;
}
}synchronized与volatile区别
volatile保证线程可见性,当工作内存中副本数据无效之后,主动读取主内存中的数据刷新到工作内存
volatile可以禁止重排序的问题,底层采用内存屏障
volatile不会导致线程阻塞,不能够保证线程安全问题,不能保证原子性(案例:count++操作)
synchronized会导致线程阻塞,能够保证线程安全
四. CAS无锁机制
Java提供了非阻塞的volatile关键字来解决共享变量的可见性问题,这在一定程度上弥补了锁带来的开销问题,但是volatile只能保证共享变量的可见性,不能解决读 - 写 - 改等操作的原子性问题。CAS,是JDK提供的非阻塞原子性操作,CAS的原子性是通过unsafe jni技术实现的,即调用native方法调用由C++编写的硬件级别指令,jdk中提供Unsafe类执行这些操作。它通过硬件保证了比较 - 更新操作的原子性。JDK里面的Unsafe类提供了一系列的compareAndSwap*方法,简单来说,CAS包含三个参数(V,E,N)V表示要更新的变量,E表示预期值,N表示新值,仅当V值等于E值时,才会将V的值设为N,如果V值和E值不同,则说明已经有其他线程做了更新,则当前线程什么都不做。最后,CAS返回当前V的真实值。
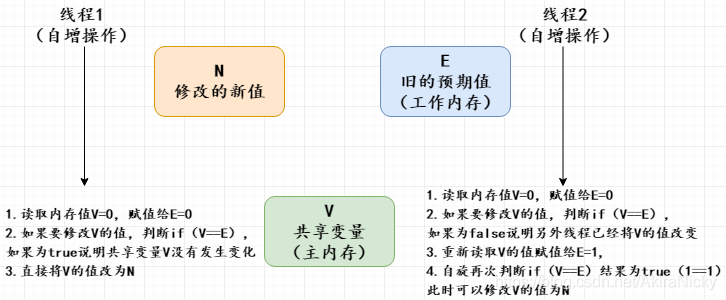
CAS 有一个典型问题就是ABA问题:我们知道 CAS 工作的基本原理是,先读取目标变量的值,然后调用原子指令判断该值是否等于我们期望的值,如果等于就认为没有被别人改过,否则视作数据脏了,重新去读变量的值。
但是问题是,如果变量 a 的值为 100,我们的 CAS 方法也读到了 100,接着来了一个线程将这个变量改为 999,之后又来一个线程再改了一下,改成 100 。而轮到我们的主线程发现 a 的值依然是 100,它视作没有人和它竞争修改 a 变量,于是修改 a 的值。
这种情况,虽然 CAS 会更新成功,但是会存在潜在的问题,中途加入的线程的操作对于后一个线程根本是不可见的。而一般的解决办法是为每一次操作加上加时间戳,CAS 不仅关注变量的原始值,还关注上一次修改时间。
in a word:当一个值从A更新为B,再从B更新为A,普通CAS机制会通过检测。解决方案是使用版本号,通过比较值和版本号来判断是否可以替换。
五. AQS 与 ReentrantLock 源码分析
AbstractQueuedSynchronizer抽象同步队列简称AQS,它是实现同步器的基础组件,并发包中锁的底层就是使用AQS实现的;AQS 是一个抽象同步队列,它提供了一个双向链表的FIFO队列,可以看成是一个用来实现同步锁以及其他涉及到同步功能的核心组件,常见的有:ReentrantLock、CountDownLatch等;AQS是一个抽象类,主要是通过继承的方式来使用,它本身没有实现任何的同步接口,仅仅是定义了同步状态的获取以及释放的方法来提供自定义的同步组件。
AQS核心字段:
Node内部类(perv,next,waitStatus)
head节点,tail节点
state状态(0没有任何线程获取到锁,1已经有线程抢到锁,234..代表重入锁,每重入一次都会+1;每次只要调用lock()方法,state都会+1,每次调用unlock()方法state都会 -1)
【ReentrantLock 的lock方法】
private static Lock lock = new ReentrantLock();
lock.lock();
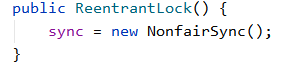

由图可知,lock锁方法有两个实现方式:公平锁和非公平锁,默认调无参构造方法即为非公平锁,如果传true,即为公平锁,关于两者区别会在下文结合源码说明,我们先以默认的非公平锁为例:

如上图所示,首先通过CAS无锁算法尝试将state改为1,如果设置成功,则执行 setExclusiveOwnerThread 方法设置锁的持有者为当前线程,代表当前线程抢到锁,并退出lock方法执行当前线程业务代码:

如果cas修改失败,则说明当前线程没有抢到锁,则进入acquire方法
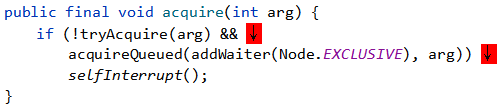
tryAcquire方法再次重试获取锁,当前线程没有获取到锁不会立马阻塞,会短暂自旋,如果再次获取锁失败,则把当前线程放入链表中,并打断让出执行权,如果tryAcquire方法返回true,则不会放入链表,也不会阻塞

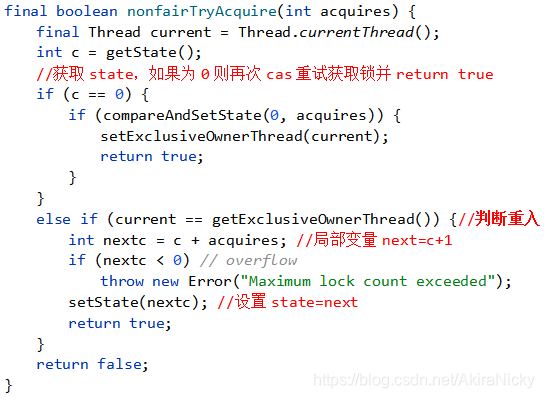
首先获取全局state的状态值,如果为0则再次CAS重试获取锁,获取成功则设置锁的持有者为当前线程,并return true;如果state不为0则代表锁已经被某个线程持有,此时,判断当前线程是否为锁的持有线程,如果是,则重入次数+1即state+1,并返回true;如果锁的持有者不是当前线程,则返回false。
继续回到acquire方法,如果tryAcquire方法返回true,则 ! true 即为false,所以不会执行&&后面的操作,即不会放入链表,也不会阻塞(返回true仅两种情况:抢到锁 or 重入锁);
否则即代表当前线程没有抢到锁,即会进入acquireQueued(addWaiter(Node.EXCLUSIVE), arg) 方法,首先执行到 addWaiter(Node.EXCLUSIVE)方法:

如源码所示,初始化当前线程为node节点,判断尾节点是否为空 ?
① 如果不为空则通过CAS设置当前node为新的尾节点,并且当前老的尾节点的next节点指向新节点;如果尾节点为空
② 如果尾节点为空则执行enq(node)方法,传入当前node节点

阅读源码不难看出,这也是一个自旋,只有当尾节点不为空时才可退出死循环;具体执行流程为:
因为只有当addWaiter方法判断的尾节点为空,才会进入enq(node)方法,所以首次进入该方法时,尾节点还是为空的,t即为null,则设置head节点为空Node,此时把head复制给tail;
此时再次进入循环,t就不是空了,所以会走到else,当前线程node节点的perv节点指向老尾节点t,老尾结点t的next指向当前线程node节点,由此一个双向链表从而形成;
至此,整个addWaiter方法执行结束,返回当前线程的node节点给acquire方法,然后按着执行 acquireQueued(当前线程node节点, 1)
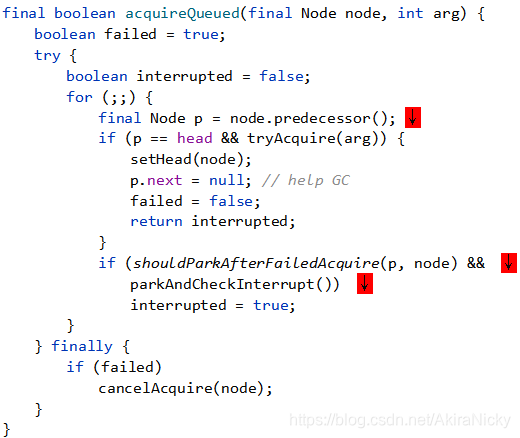

首先,拿到node(当前线程)的上一个节点p,判断一下p节点是否为头节点
如果p节点不是头节点,则会执行到shouldParkAfterFailedAcquire方法:
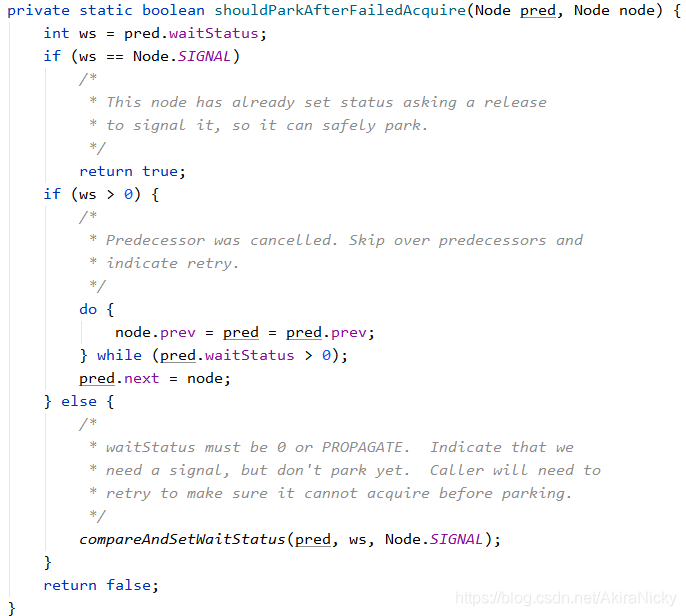
该方法是让当前线程的上一节点pred变为阻塞状态,这里维护了一个Node节点的waitStatus状态,状态说明如下:
CANCELLED,值为1,表示当前的线程被取消;
SIGNAL,值为-1,释放资源后需唤醒后继节点;当前线程变为阻塞
CONDITION,值为-2, 等待condition唤醒;
PROPAGATE,值为-3,工作于共享锁状态,需要向后传播,比如根据资源是否剩余,唤醒后继节点;
如果值为0,表示当前节点在sync队列中,等待着获取锁;当前线程还未阻塞
① 如果ws为0,则通过CAS无锁机制设置ws为-1(阻塞),场景如下:
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
lock.lock();
}, "t1");
t1.start();
t1.join();
Thread t2 = new Thread(() -> {
lock.lock(); //断点打在该行
}, "t2");
t2.start();
}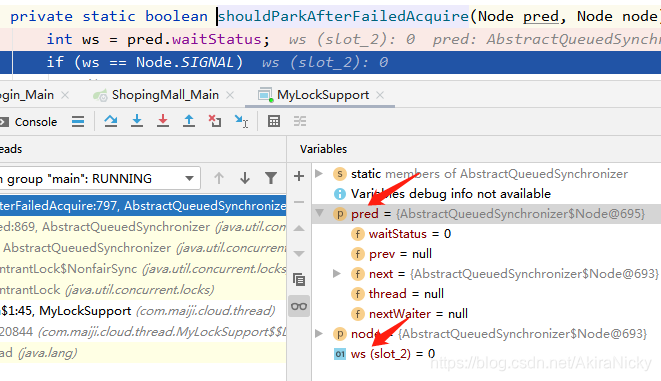
由于t1线程是优先获取到锁的(join会让主线程让出执行权,优先执行调用join的线程),所以t1线程并不会在双向链表的Node阻塞队列里,而t2尝试获取锁,此时t2会是第一个放入阻塞队列的线程;由于上文中讲过head会是一个空Node节点,所以debug调试可以看出,当前线程(t2)的上个节点为空head,即shouldParkAfterFailedAcquire方法的pred参数即为空head节点,所以waitStatus默认为0,即会执行到else里面的代码,设置当前线程的node节点的waitStatus为-1。
②如果ws为-1,则返回true给acquireQueued方法,然后执行parkAndCheckInterrupt方法,由该方法阻塞当前线程

场景如下:
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
lock.lock();
}, "t1");
t1.start();
t1.join();
Thread t2 = new Thread(() -> {
lock.lock();
}, "t2");
t2.start();
Thread.sleep(100L);
Thread t3 = new Thread(() -> {
lock.lock(); //断点打在该行
}, "t3");
t3.start();
}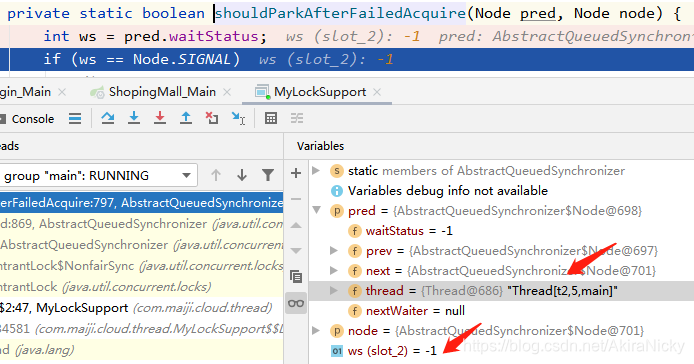
不难看出,当前节点(t3线程)的上一节点为t2线程,即会在acquireQueued方法循环遍历重复执行到shouldParkAfterFailedAcquire方法,把prev线程,当前线程Node节点的waitStatus改为-1。
至此,基于AQS思想ReentrantLock的lock方法源码已经走了一遍 ~
【ReentrantLock 的unlock方法】

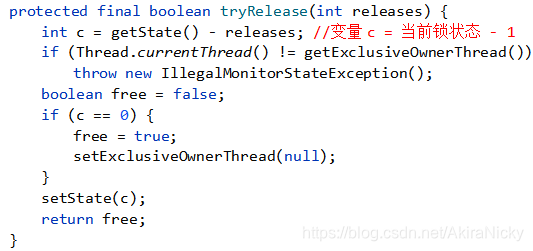
如图,首先执行tryRelease方法,定义局部变量 c = 当前AQS锁的状态 -1;判断当前调用unlock的线程和持有锁的线程是否一致,如果不一致,则抛出异常,即调用lock和unlock必须是同一个线程,谁持有的锁谁释放;
如果 c 等于0,则置空占有锁的线程,并返回true;否则返回false给release方法
继续回到release方法,返回true,则执行unparkSuccessor方法

拿到node节点(即head)的next节点,即链表中第二个节点假设为t2,然后唤醒t2,此时,唤醒的t2在acquireQueued方法重新唤醒:
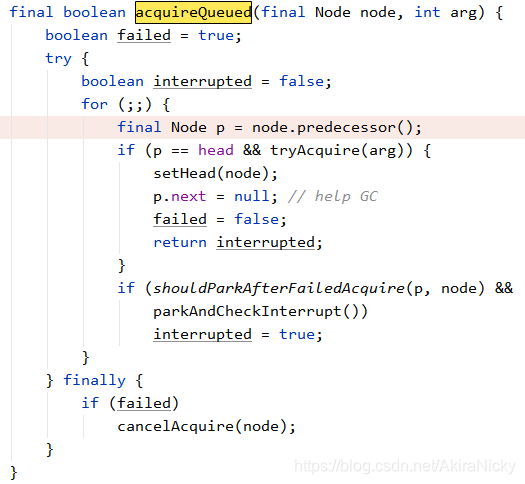
然后t2线程会执行上文中tryAcquire方法重试获取锁;那么小伙伴们是否有个疑问? 既然唤醒一个线程,那肯定就是从头到尾依次执行,即执行顺序是公平的,那么何来非公平锁呢? 请看下文 ~
【公平锁与非公平锁】
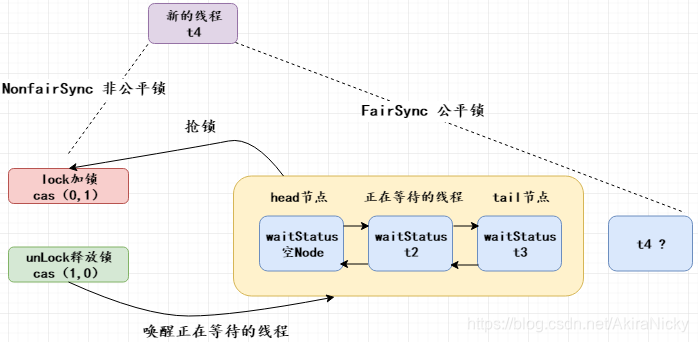
公平锁(FairSync):唤醒t2的时候,突然进来一个新的线程t4,此时t4不会和t2抢锁,会插到链表尾部
非公平锁(NonfairSync):唤醒t2的时候,突然进来一个新的线程t4,此时t4会和t2抢锁,抢不到锁的则会放入阻塞队列的双向链表中

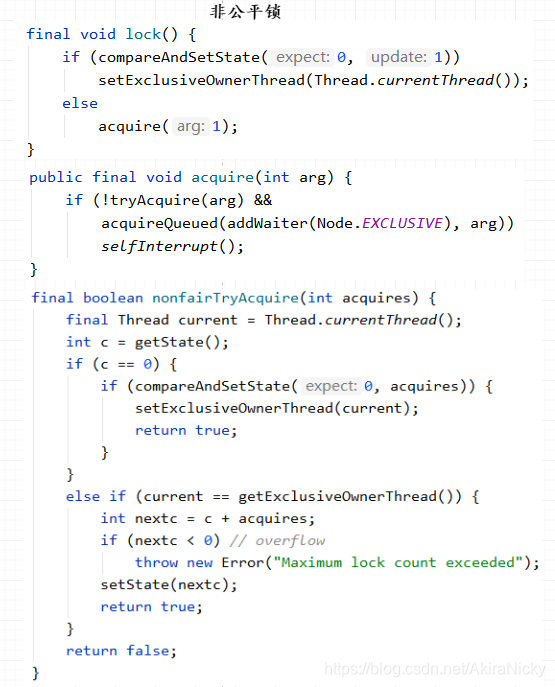
两者区别在于:尝试获取锁的时候,公平锁加了一个hasQueuedPredecessors方法判断:
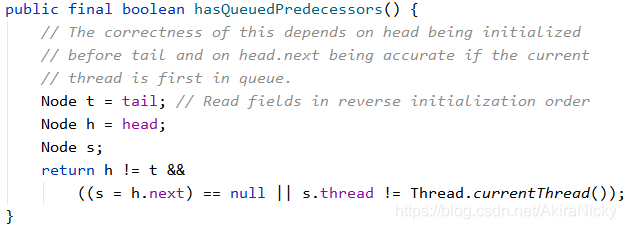
如果当前线程不是head.next节点,则不能进行CAS操作进行抢锁,必须乖乖放到链表后边 ~
为什么AQS阻塞队列的head节点是空Node节点,即没有绑定任何线程?
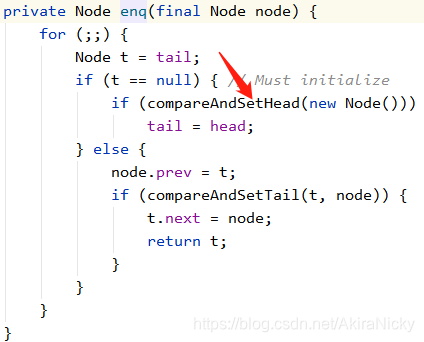
假如两个线程t1,t2同时抢锁,t1抢到了锁,则t2抢锁失败,进入acquire方法的 addWaiter 方法的 enq 方法,如果链表为空则初始化一个空Node节点node,此时node为head和tail,然后 head.next = t2, t2.prev = head;
组装完Node双向链表后,会执行到 acquireQueued 方法:
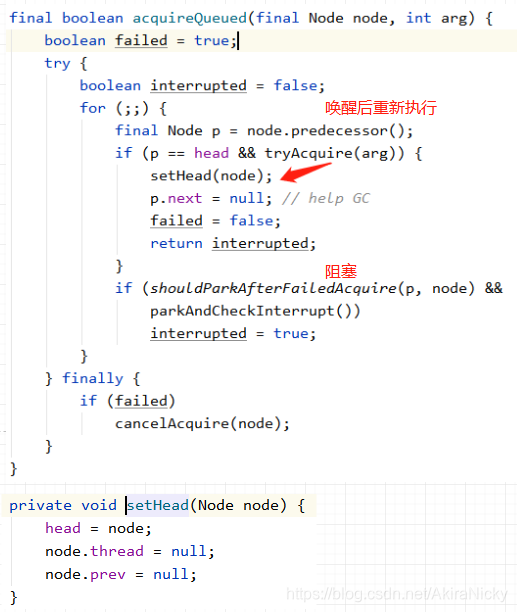
此时t2线程会会被parkAndCheckInterrupt方法阻塞,等待唤醒重新进入for循环第一行:
final Node p = node.predecessor();此时的node节点还是为t2,p为t2的上一个节点即为空Node节点,链表结构为:
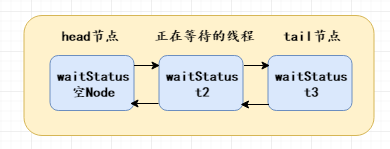
会执行到 tryAcquire(arg) 方法,如果获取锁成功,则 setHead(node) 设置t2为head;即当前线程如果获取到锁,则当前线程变为头节点;并把当前节点(头节点)的thread和prev全部置为空;
执行完setHead方法后,也会把 p (之前的head) .next置为空,此时p节点没有任何引用,等待GC回收;最后退出自旋,执行线程具体业务逻辑。
上述过程即为一个指针交换的过程,执行完后的双向链表结构为:
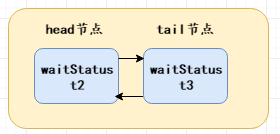
综上所述,头节点是不参与排队的,因为它已经获得了同步状态了,可以理解为头节点即为获取到锁的线程(虽然Thread为null),所以只有头节点才是成功获取了同步状态的节点,而当头节点释放了同步状态后,头节点会唤醒它的后继节点,同时后继节点的线程被唤醒后还需要检查自己的前驱节点是不是头节点,这是为了保证队列的FIFO规则,防止有节点被中断唤醒,出现插队行为;当释放同步状态后,该头节点是肯定要被垃圾回收的,防止内存空间的浪费,这里就涉及到了gc root,如果对象还有引用的话,垃圾回收器是不会回收它的,所以需要把头节点持有的各种引用都置为null,方便之后的GC垃圾回收。
【AQS - Condition源码解读】
相信用过synchronized的都知道,wait和notify是配合synchronized内置锁实现线程同步的基础设置;而基于AQS思想实现的Lock锁也有实现阻塞和唤醒线程的方法:signal和await。该两个方法是Condition接口提供的,其实现类ConditionObject,是AQS中的一个子类,好了废话不多说直接先上代码熟悉一下:
public class MyCondition {
private static ReentrantLock lock = new ReentrantLock();
private static Condition condition = lock.newCondition(); //条件变量
public static void main(String[] args) throws Exception{
new Thread(()->{
System.out.println(1);
try {
lock.lock();
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(2);
lock.unlock();
}, "t1").start();
Thread.sleep(1000L);
System.out.println(3);
lock.lock();
condition.signal();
lock.unlock();
}
}正如wait()方法必须要在synchronized同步代码块中调用一样,Condition的await()方法也必须在Lock.lock()上锁后调用,否则也会报错:IllegalMonitorStateException。
lock.newCondition()的作用其实是new了一个在AQS内部声明的ConditionObject对象,ConditionObject是AQS的内部类,可以访问AQS内部的变量(例如状态变量state)和方法;在每个条件变量内部都维护了一个条件队列,用来存放调用条件变量的await()方法时被阻塞的线程,需要注意这个条件队列和AQS队列不是一回事;当另外一个线程调用条件变量的signal方法时,在内部会把条件队列的第一个节点(头节点)从条件队列里面移除来放入AQS的阻塞队列里面,然后等待唤醒。下面画图说明一下:
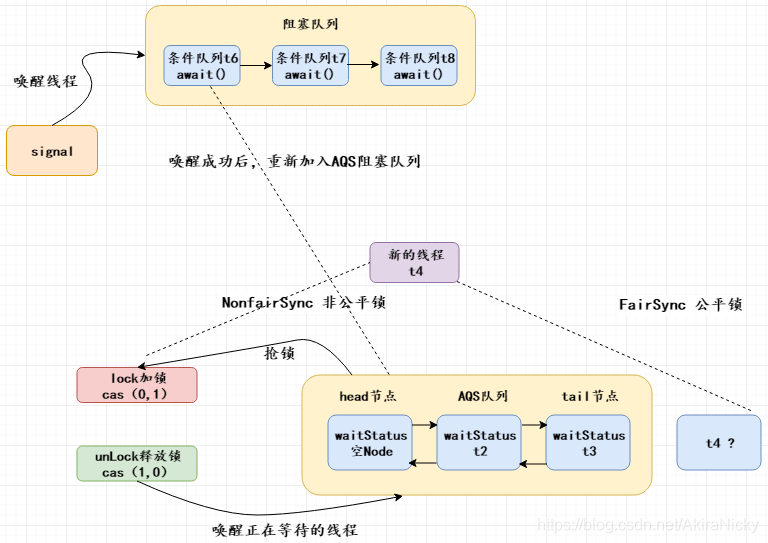
接下来结合源码具体分析await()和signal()的实现原理:
1. 线程等待await()
首先先整理出await()内部调用流程:
// 向条件队列中添加节点并返回
private Node addConditionWaiter() {...}
// 释放节点持有的锁
final int fullyRelease(Node node) {...}
// 判断节点是否在同步队列中
final boolean isOnSyncQueue(Node node) {...}
// 检查线程是否中断,如果是则终止Condition状态并加入到同步队列
private int checkInterruptWhileWaiting(Node node) {...}
// 操作节点去申请锁
final boolean acquireQueued(final Node node, int arg) { ...}
// 清理等待队列中无效节点
private void unlinkCancelledWaiters() {...}
// 处理线程中断情况
private void reportInterruptAfterWait(int interruptMode){...}接下来具体分析执行流程,先从await()方法开始:

在t1位置,先看一下addConditionWaiter()方法,看名字是增加了一个条件等待对象,应该就是向条件队列中操作了
private Node addConditionWaiter() {
Node t = lastWaiter; //获取尾部指针(单向链表)
// If lastWaiter is cancelled, clean out.
if (t != null && t.waitStatus != Node.CONDITION) {
unlinkCancelledWaiters(); //t7'
t = lastWaiter;
}
Node node = new Node(Thread.currentThread(), Node.CONDITION); //创建一个新节点,线程为当前线程,waitStatus为-2
if (t == null) //尾结点为空,说明队列是空的
firstWaiter = node; //头节点设置为node
else
t.nextWaiter = node; //尾插法
lastWaiter = node; //设置当前node为尾节点
return node; //返回新增node节点对象
}t7和t7',在await()和addConditionWaiter()方法中,都调用了unlinkCancelledWaiters(),先看一下它做了什么:
private void unlinkCancelledWaiters() {
Node t = firstWaiter; //拿到头节点
Node trail = null;
while (t != null) { //如果头节点不为空,队列不为空
Node next = t.nextWaiter; // 遍历等待队列
if (t.waitStatus != Node.CONDITION) { //如果节点的状态不是CONDITION
t.nextWaiter = null; //将节点移除队列
if (trail == null) //首次遍历,进度为0
firstWaiter = next; //头节点指向被移除节点的下一个节点
else
trail.nextWaiter = next; //进度指向下一个节点,也是将修复被移除队列节点的影响,保证队列连续
if (next == null)
lastWaiter = trail; //如果next为空,说明队列遍历完成,将尾指针指向进度节点
}
else //如果节点的状态是CONDITION
trail = t; //保存进度
t = next;
}
}那么unlinkCancelledWaiters()方法就做了一件事,遍历等待队列,将非CONDITION状态到的节点移除。
说回addConditionWaiter()方法,它其实和addWaiter()方法功能差不多,向队列中添加节点,这里的队列是“等待队列”;接着分析await()方法的t2位置→调用fullyRelease(node),传入新添加的node节点,并返回一个状态:
final int fullyRelease(Node node) {
boolean failed = true;
try {
int savedState = getState(); //获取AQS中的state值
if (release(savedState)) { //调用释放锁方法
failed = false;
return savedState; //如果释放成功,返回state值
} else {
throw new IllegalMonitorStateException();
}
} finally {
if (failed)
node.waitStatus = Node.CANCELLED;
}
}在fullyRelease()方法中,主要是调用了release()去释放锁。这里有个前提就是线程必须先持有锁,才能调用await()方法,进而release()释放锁;那么就引出了await()方法暂停线程,会导致锁被释放的逻辑 ~
接下来继续分析await()方法:
在t3位置,调用了while循环,条件是!isOnSyncQueue(node),是否不在同步队列中? 如果不在,将会执行下面的内容
final boolean isOnSyncQueue(Node node) {
if (node.waitStatus == Node.CONDITION || node.prev == null)
return false; //以节点状态作为判断条件,如果等于CONDITION即-2(说明在条件队列中)、或者前置节点为空,是一个独立节点
if (node.next != null) //If has successor, it must be on queue
return true; //如果后继节点不为空,说明它还在AQS阻塞队列中,返回true
/*
* node.prev can be non-null, but not yet on queue because
* the CAS to place it on queue can fail. So we have to
* traverse from tail to make sure it actually made it. It
* will always be near the tail in calls to this method, and
* unless the CAS failed (which is unlikely), it will be
* there, so we hardly ever traverse much.
* 前置节点为空,并不代表节点不在队列上,因为 CAS操作有可能失败。 因此需要从尾部遍历队列来保证它不在队列上。
*/
return findNodeFromTail(node); // 从尾部找到node节点
}//这个方法没什么好解释的
private boolean findNodeFromTail(Node node) {
Node t = tail;
for (;;) {
if (t == node)
return true;
if (t == null)
return false;
t = t.prev;
}
}这里要注意一点,node的next属性是AQS的同步队列范畴的属性,在ConditionObject中是没有使用next属性的。
那么,如果while (!isOnSyncQueue(node)) 成立,就是node节点不在AQS阻塞队列上,则说明node已经释放锁了,并且进入了条件队列。接下来让线程挂起、等待被唤醒就可以了(即执行t4)
在t5位置,执行的条件是线程被唤醒,唤醒后首先要检查的是,在这期间线程是否有被中断,保证线程安全:
private int checkInterruptWhileWaiting(Node node) {
return Thread.interrupted() ?
(transferAfterCancelledWait(node) ? THROW_IE : REINTERRUPT) : //t5-1
0;
}
final boolean transferAfterCancelledWait(Node node) {
if (compareAndSetWaitStatus(node, Node.CONDITION, 0)) { //将节点状态由CONDITION调整为0
enq(node); //加入AQS阻塞队列
return true;
}
/*
* If we lost out to a signal(), then we can't proceed
* until it finishes its enq(). Cancelling during an
* incomplete transfer is both rare and transient, so just
* spin.
* 如果忘记调用signal,那么就不能继续执行了,要让它回到同步队列中。
*/
while (!isOnSyncQueue(node)) //判断线程是否在AQS阻塞队列,直到回到AQS阻塞队列(取消,也要先让node回到AQS阻塞队列)
Thread.yield(); //让出CPU时间
return false; //修改node状态失败,返回false
}总结t5的逻辑,线程被唤醒后,检查线程状态,如果是中断状态,要尝试将node的节点状态变更为0,如果变更成功,则判定中断原因是异常,如果变更失败,要给线程时间让其他线程将node放回同步队列。
在t5位置,如果返回的不是初始值,则外层while会被break;如果是初始值,则会判断是否进入同步队列,是则结束循环,否则说明还在等待队列,需要继续被挂起。
当循环结束,后续流程就需要让线程重新进入锁竞争状态,并且前面判断了那么多线程状态,也要根据返回值处理一下:
在t6位置,让节点线程再次去申请锁,同时传入挂起前保存的资源值saveState,节点回到竞争状态后就是AQS申请逻辑,可以交给AQS了;对于await()来说,剩下的就是处理线程状态了。
如果interruptMode != -1,则调整interruptMode的值为1。也就是说,如果线程申请锁成功,未来会让线程中断。
在t7位置,如果节点node有后继节点,那么需要将node从等待队列移除
在t8位置,如果interruptMode的值不为0,也就是不正常状态,进入reportInterruptAfterWait()方法。
private void reportInterruptAfterWait(int interruptMode)
throws InterruptedException {
if (interruptMode == THROW_IE) //如果为异常状态
throw new InterruptedException(); //抛出异常
else if (interruptMode == REINTERRUPT) //如果为中断状态
selfInterrupt(); //设置线程中断
}
static void selfInterrupt() {
Thread.currentThread().interrupt();
}以上就是await()方法的全部流程,大致可归纳为:
1. 将持有锁的线程包装为node,并放入等待队列
2. 将持有的锁释放,保持持有锁时申请的资源值
3.循环判断节点node释放在同步队列中,如果没有则挂起线程
4. 线程被唤醒后,要判断线程状态
5. 让线程去申请锁,根据申请规则,如果申请失败会在同步队列挂起
6. 如果申请成功,要根据线程状态对线程进行合理的处理:抛异常或中断
2. 线程唤醒signal()
先整理出一个signal()内部调用流程:
public final void signal() {...} //唤醒线程入口
protected boolean isHeldExclusively(); //判定当前线程是否持有锁
private void doSignal(Node first) {...} //唤醒first节点
final boolean transferForSignal(Node node) {...} //转换节点状态接下来具体分析执行流程,先从入口signal()方法开始:

首先判断当前线程是否持有锁,只有持有锁的线程才能操作唤醒;接下来获取条件队列的头节点,头节点不为空的情况下执行doSignal(first)方法进行唤醒操作:
private void doSignal(Node first) {
do {
//t1
if ( (firstWaiter = first.nextWaiter) == null)
lastWaiter = null;
first.nextWaiter = null;
} while (!transferForSignal(first) && //t2
(first = firstWaiter) != null); //t3
}方法进入后,遇到一个do..while循环,先执行do内逻辑;
在t1位置,判断给定的节点first是否存在后继节点,如果不存在,将lastWaiter置为null,这里就是将条件队列清空;
接着进入t2位置,调用transferForSignal()方法:
final boolean transferForSignal(Node node) {
if (!compareAndSetWaitStatus(node, Node.CONDITION, 0)) //cas把-2变为0
return false; //t2-1 (cas操作失败,返回false)
/*
* Splice onto queue and try to set waitStatus of predecessor to
* indicate that thread is (probably) waiting. If cancelled or
* attempt to set waitStatus fails, wake up to resync (in which
* case the waitStatus can be transiently and harmlessly wrong).
*/
//cas成功
Node p = enq(node); //把node节点加入AQS阻塞队列
int ws = p.waitStatus; //获取加入节点的waitStatus,0
if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL)) //t2-2 cas把p的waitStatus改为-1成功,取反则改不成功才会唤醒;如果改成功,则下面一行不会走
LockSupport.unpark(node.thread); //唤醒线程
return true;
}首先把传入的条件队列的头节点通过cas把waitStatus变为0,然后把该条件队列里的头节点放入AQS阻塞队列的尾节点(enq方法上文中讲到),接着cas把p节点(之前的尾节点,可看enq方法)的waitStatus改为-1,成功则return true,否则唤醒线程。
以上就是signal()方法的所有源码,归纳一下:
1. 只有持有锁的线程才能操作唤醒
2. 唤醒时要针对条件队列 的头节点所代表的线程
3. 唤醒 = (线程节点node状态重置即-2变为0 + node回到aqs阻塞队列 + unpark线程)
CANCELLED,值为1,表示当前的线程被取消;
SIGNAL,值为-1,释放资源后需唤醒后继节点;当前线程变为阻塞
CONDITION,值为-2, 等待condition唤醒;
PROPAGATE,值为-3,工作于共享锁状态,需要向后传播,比如根据资源是否剩余,唤醒后继节点;
如果值为0,表示当前节点在sync队列中,等待着获取锁;当前线程还未阻塞
3. 唤醒所有线程signalAll()
在Condition接口中,还有一个signalAll()方法,目的是唤醒所有等待的节点,来看一下源码:
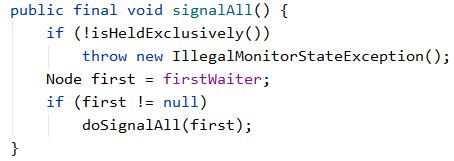

与doSignal()的区别是 while流程有变化,它不是找到一个可被唤醒的节点就结束,而是遍历整个等待队列,将所有节点唤醒。 至此,AQS条件队列Condition源码分析完毕 ~
六. CountDownLatch
CountDownLatch是一种java.util.concurrent包下一个同步工具类,它允许一个或多个线程等待直到在其他线程中一组操作执行完成,和Thread的join方法非常类似
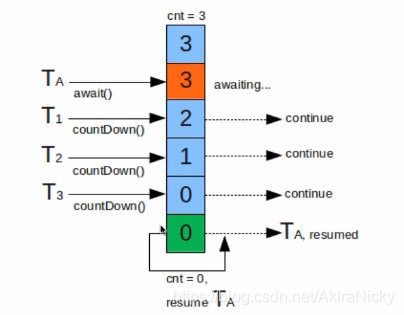
底层基于 AbstractQueuedSynchronizer(AQS后面会重点讲解) 实现,CountDownLatch 构造函数中指定的count直接赋给AQS的state;每次countDown()则都是release(1)减1,最后减到0时unpark阻塞线程;这一步是由最后一个执行countdown方法的线程执行的。
而调用await()方法时,当前线程就会判断state属性是否为0,如果为0,则继续往下执行,如果不为0,则使当前线程进入等待状态,直到某个线程将state属性置为0,其就会唤醒在await()方法中等待的线程。
场景1 让多个线程等待:模拟并发,让并发线程一起执行
田径赛跑时,运动员会在起跑线做准备动作,等到发令枪一声响,运动员就会奋力奔跑,代码实现如下:
CountDownLatch countDownLatch = new CountDownLatch(1);
for (int i = 0; i < 5; i++) {
new Thread(() -> {
try {
//准备完毕……运动员都阻塞在这,等待号令
countDownLatch.await();
String parter = "【" + Thread.currentThread().getName() + "】";
System.out.println(parter + "开始执行");
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
Thread.sleep(2000);// 裁判准备发令
countDownLatch.countDown();// 发令枪:执行发令运行结果:
【Thread-0】开始执行
【Thread-1】开始执行
【Thread-4】开始执行
【Thread-3】开始执行
【Thread-2】开始执行我们通过CountDownLatch.await(),让多个参与者线程启动后阻塞等待,然后在主线程 调用CountDownLatch.countdown(1) 将计数减为0,让所有线程一起往下执行;以此实现了多个线程在同一时刻并发执行,来模拟并发请求的目的
场景2 让单个线程等待:多个线程(任务)完成后,进行汇总合并
很多时候,我们的并发任务,存在前后依赖关系;比如数据详情页需要同时调用多个接口获取数据,并发请求获取到数据后、需要进行结果合并;或者多个数据操作完成后,需要数据check;这其实都是:在多个线程(任务)完成后,进行汇总合并的场景。
CountDownLatch countDownLatch = new CountDownLatch(5);
for (int i = 0; i < 5; i++) {
final int index = i;
new Thread(() -> {
try {
Thread.sleep(1000 + ThreadLocalRandom.current().nextInt(1000));
System.out.println("finish-" + index + Thread.currentThread().getName());
countDownLatch.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
countDownLatch.await();// 主线程在阻塞,当计数器==0,就唤醒主线程往下执行。
System.out.println("主线程:在所有任务运行完成后,进行结果汇总");运行结果:
finish-4Thread-4
finish-1Thread-1
finish-2Thread-2
finish-3Thread-3
finish-0Thread-0
主线程:在所有任务运行完成后,进行结果汇总从上面两个例子的代码,可以看出 CountDownLatch 的API并不多;
- CountDownLatch的构造函数中的count就是闭锁需要等待的线程数量。这个值只能被设置一次,而且不能重新设置
- await():调用该方法的线程会被阻塞,直到构造方法传入的 N 减到 0 的时候,才能继续往下执行
- countDown():使 CountDownLatch 计数值 减 1
CountDownLatch与Thread.join
CountDownLatch与join的区别:调用thread.join() 方法必须等thread 执行完毕,当前线程才能继续往下执行,而CountDownLatch通过计数器提供了更灵活的控制,只要检测到计数器为0当前线程就可以往下执行而不用管相应的thread是否执行完毕。
(当前线程让出执行权,如主线程调用子线程.join,则主线程阻塞,子线程优先执行)
七. Semaphore
Semaphore顾名思义就是信号量,Semaphore可以阻塞线程并且可以控制同时访问线程的个数,通过acquire()获取一个许可,如果没有获取到就继续等待,通过release()释放一个许可,将其返回给信号量。Semaphore和锁有点类似,都可以控制对某个资源的访问权限。 CountDownLatch和Semaphore通常和线程池配合使用。Semaphore适合控制并发数,CountDownLatch比较适合保证线程执行完后再执行其他处理,因此模拟并发时,使用两者结合起来是最好的。
Semaphore可以用来做流量分流,特别是对公共资源有限的场景,比如数据库连接。 假设有这个的需求,读取几万个文件的数据到数据库中,由于文件读取是IO密集型任务,可以启动几十个线程并发读取,但是数据库连接数只有10个,这时就必须控制最多只有10个线程能够拿到数据库连接进行操作。这个时候,就可以使用Semaphore做流量控制;Semaphore信号量也可以实现对接口限流,底层是基于AQS实现

public class SemaphoreTest {
public static void main(String[] args) throws InterruptedException {
ExecutorService executor = Executors.newFixedThreadPool(10);
Semaphore semaphore = new Semaphore(4);
for (int i = 0; i < 10; i++) {
executor.execute(()->{
try {
semaphore.acquire();
System.out.println("处理数据中...");
Thread.sleep(2000);
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
executor.shutdown();
}
}处理数据中..
处理数据中..
处理数据中..
处理数据中..
处理数据中..
处理数据中..
处理数据中..
处理数据中..
处理数据中..
处理数据中..如果把注释掉semaphore.release()注释掉,信号量一直为4,只有四个线程能获取到许可,其他线程则会继续等待:
八. 什么是ThreadLocal
从名字我们就可以看到ThreadLocal叫做线程变量,意思是ThreadLocal中填充的变量属于当前线程,该变量对其他线程而言是隔离的。ThreadLocal为变量在每个线程中都创建了一个副本,那么每个线程可以访问自己内部的副本变量,ThreadLocal相当于提供了一种线程隔离,将变量与线程相绑定,Threadloca适用于在多线程的情况下,可以实现传递数据,实现线程隔离。threadlocal使用方法很简单:
public class MyThreadLocal {
public static void main(String[] args) {
ThreadLocal<String> threadLocal = new ThreadLocal<>();
threadLocal.set("smile");
System.out.println(threadLocal.get());
}
}threadlocal而是一个线程内部的存储类,可以在指定线程内存储数据,数据存储以后,只有指定线程可以得到存储数据,官方解释如下:
/**
* This class provides thread-local variables. These variables differ from
* their normal counterparts in that each thread that accesses one (via its
* {@code get} or {@code set} method) has its own, independently initialized
* copy of the variable. {@code ThreadLocal} instances are typically private
* static fields in classes that wish to associate state with a thread (e.g.,
* a user ID or Transaction ID).
*/大致意思就是ThreadLocal提供了线程内存储变量的能力,这些变量不同之处在于每一个线程读取的变量是对应的互相独立的。通过get和set方法就可以得到当前线程对应的值。
做个不恰当的比喻,从表面上看ThreadLocal相当于维护了一个map,key就是当前的线程,value就是需要存储的对象。
这里的这个比喻是不恰当的,实际上是ThreadLocal的静态内部类ThreadLocalMap为每个Thread都维护了一个Entry类型的数组table,ThreadLocal确定了一个数组下标,而这个下标就是value存储的对应位置。。
作为一个存储数据的类,关键点就在get和set方法:
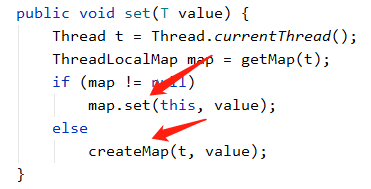
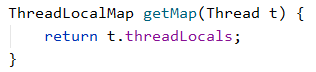
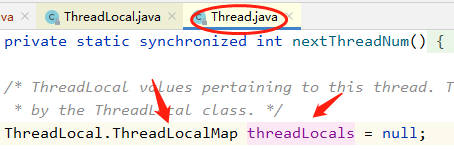
每个线程持有一个ThreadLocalMap对象,每一个新的线程Thread都会实例化一个ThreadLocalMap并赋值给Thread成员变量threadLocals,使用时若已经存在threadLocals则直接使用已经存在的对象进行set操作,否则createMap创建ThreadLocalMap实例
【ThreadLocalMap】
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
private static final int INITIAL_CAPACITY = 16;
private Entry[] table;
private int size = 0;
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}
}通过阅读ThreadLocalMap源码,可以看出它基于一个Entry键值对的数组table存储数据,在实例化ThreadLocalMap时创建了一个长度为16的Entry数组。通过hashCode与length位运算确定出一个索引值i,这个i就是被存储在table数组中的位置。
前面讲过每个线程Thread持有一个ThreadLocalMap类型的实例threadLocals,结合此处的构造方法可以理解成每个线程Thread都持有一个Entry型的数组table,而一切的读取过程都是通过操作这个数组table完成的。
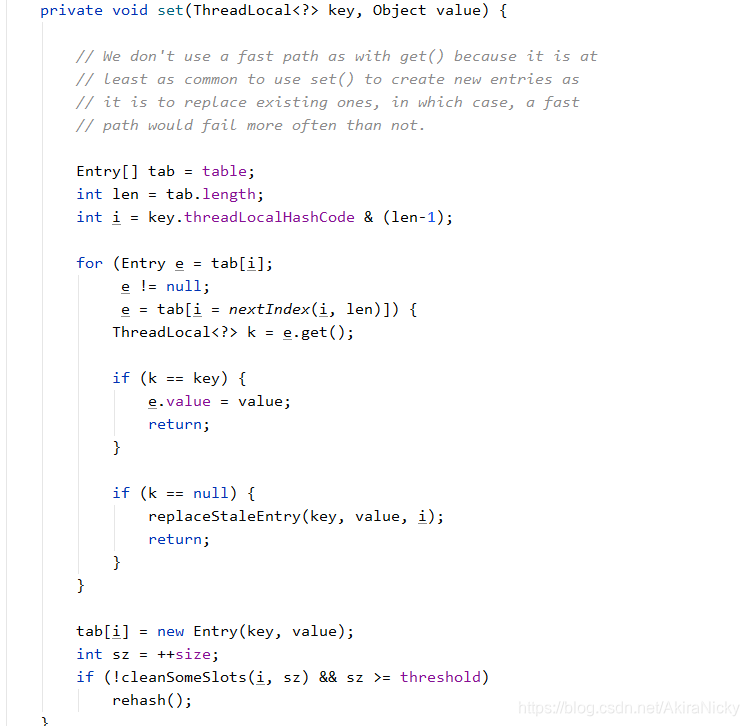
显然table是set和get的焦点,在看具体的set和get方法前,先看下面这段代码。
//在某一线程声明了ABC三种类型的ThreadLocal
ThreadLocal<A> sThreadLocalA = new ThreadLocal<A>();
ThreadLocal<B> sThreadLocalB = new ThreadLocal<B>();
ThreadLocal<C> sThreadLocalC = new ThreadLocal<C>();由前面我们知道对于一个Thread来说只有持有一个ThreadLocalMap,所以ABC对应同一个ThreadLocalMap对象。为了管理ABC,于是将他们存储在同一个数组的不同位置,而这个数组就是上面提到的Entry型的数组table。
那么问题来了,ABC在table中的位置是如何确定的?为了能正常够正常的访问对应的值,肯定存在一种方法计算出确定的索引值i,简而言之就是将threadLocalHashCode进行一个位运算(取模)得到索引i(详情参考博客 ThreadLocal - 简书)
总结如下:
- 对于某一ThreadLocal来讲,他的索引值i是确定的,在不同线程之间访问时访问的是不同的table数组的同一位置即都为table[i],只不过这个不同线程之间的table是独立的。
- 对于同一线程的不同ThreadLocal来讲,这些ThreadLocal实例共享一个table数组,然后每个ThreadLocal实例在table中的索引i是不同的。
//ThreadLocal中get方法
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
//ThreadLocalMap中getEntry方法
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}理解了set方法,get方法也就清楚明了,无非是通过计算出索引直接从数组对应位置读取即可。
ThreadLocal实现主要涉及Thread,ThreadLocal,ThreadLocalMap这三个类。关于ThreadLocal的实现流程正如上面写的那样,具体可以断点调试走一下流程看一下执行原理~
【ThreadLocal特性】
ThreadLocal和Synchronized都是为了解决多线程中相同变量的访问冲突问题,不同的点是
- Synchronized是通过线程等待,牺牲时间来解决访问冲突
- ThreadLocal是通过每个线程单独一份存储空间,牺牲空间来解决冲突,并且相比于Synchronized,ThreadLocal具有线程隔离的效果,只有在线程内才能获取到对应的值,线程外则不能访问到想要的值。
正因为ThreadLocal的线程隔离特性,使他的应用场景相对来说更为特殊一些。在android中Looper、ActivityThread以及AMS中都用到了ThreadLocal。当某些数据是以线程为作用域并且不同线程具有不同的数据副本的时候,就可以考虑采用ThreadLocal。
关于Java并发编程还有很多的知识点,这里只是分析了很多并发包和线程锁的核心,还有很多东西值得我们去探索;接下来我也会去慢慢探索Java并发编程之美 !
最后附上我的格言:世界上最可怕的事,是比你优秀的人,比你还努力 ~