C4.5算法较之ID3算法主要有4点改进:
- 采用信息增益率作为最优划分属性。
- 能够处理连续值类型的属性。
- 能够处理缺失值属性。
- 增加了剪枝处理,从而避免过拟合。
其中第2、3、4点在之前文章中都详细讨论过,此文主要补充说明第一点信息增益率准则,并对C4.5算法给出完整的Python代码。
一、信息增益率
ID3算法中的信息增益准则对取值数目较多的属性有所偏好,例如西瓜数据集中,如果把“编号”也作为候选划分属性,它的信息增益为0.998,但是如果用“编号”作为划分属性显然是不合理的。为了减少这种偏好可能带来的不利影响,C4.5决策树算法中使用增益率(gain ratio)来选择最优划分属性。
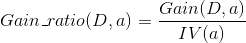
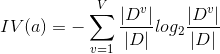
IV(a)称为属性a的固有值,属性a的可能取值数目越多,则IV(a)的值通常会越大。因此,增益率准则对可取值数目较少的属性有所偏好,因此,C4.5算法并不是直接选择增益率最大的候选划分属性,而是先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
主要Python代码:
def calcGainRatio(dataSet, labelIndex, labelPropertyi):
"""
type: (list, int, int) -> float, int
计算信息增益率,返回信息增益率和连续属性的划分点
dataSet: 数据集
labelIndex: 特征值索引
labelPropertyi: 特征值类型,0为离散,1为连续
"""
baseEntropy = calcShannonEnt(dataSet, labelIndex) # 计算根节点的信息熵
featList = [example[labelIndex] for example in dataSet] # 特征值列表
uniqueVals = set(featList) # 该特征包含的所有值
newEntropy = 0.0
bestPartValuei = None
IV = 0.0
totalWeight = 0.0
totalWeightV = 0.0
totalWeight = calcTotalWeight(dataSet, labelIndex, True) # 总样本权重
totalWeightV = calcTotalWeight(dataSet, labelIndex, False) # 非空样本权重
if labelPropertyi == 0: # 对离散的特征
for value in uniqueVals: # 对每个特征值,划分数据集, 计算各子集的信息熵
subDataSet = splitDataSet(dataSet, labelIndex, value)
totalWeightSub = 0.0
totalWeightSub = calcTotalWeight(subDataSet, labelIndex, True)
if value != 'N':
prob = totalWeightSub / totalWeightV
newEntropy += prob * calcShannonEnt(subDataSet, labelIndex)
prob1 = totalWeightSub / totalWeight
IV -= prob1 * log(prob1, 2)
else: # 对连续的特征
uniqueValsList = list(uniqueVals)
if 'N' in uniqueValsList:
uniqueValsList.remove('N')
# 计算空值样本的总权重,用于计算IV
totalWeightN = 0.0
dataSetNull = splitDataSet(dataSet, labelIndex, 'N')
totalWeightN = calcTotalWeight(dataSetNull, labelIndex, True)
probNull = totalWeightN / totalWeight
if probNull > 0.0:
IV += -1 * probNull * log(probNull, 2)
sortedUniqueVals = sorted(uniqueValsList) # 对特征值排序
listPartition = []
minEntropy = inf
if len(sortedUniqueVals) == 1: # 如果只有一个值,可以看作只有左子集,没有右子集
totalWeightLeft = calcTotalWeight(dataSet, labelIndex, True)
probLeft = totalWeightLeft / totalWeightV
minEntropy = probLeft * calcShannonEnt(dataSet, labelIndex)
IV = -1 * probLeft * log(probLeft, 2)
else:
for j in range(len(sortedUniqueVals) - 1): # 计算划分点
partValue = (float(sortedUniqueVals[j]) + float(
sortedUniqueVals[j + 1])) / 2
# 对每个划分点,计算信息熵
dataSetLeft = splitDataSet(dataSet, labelIndex, partValue, 'L')
dataSetRight = splitDataSet(dataSet, labelIndex, partValue, 'R')
totalWeightLeft = 0.0
totalWeightLeft = calcTotalWeight(dataSetLeft, labelIndex, True)
totalWeightRight = 0.0
totalWeightRight = calcTotalWeight(dataSetRight, labelIndex, True)
probLeft = totalWeightLeft / totalWeightV
probRight = totalWeightRight / totalWeightV
Entropy = probLeft * calcShannonEnt(
dataSetLeft, labelIndex) + probRight * calcShannonEnt(dataSetRight, labelIndex)
if Entropy < minEntropy: # 取最小的信息熵
minEntropy = Entropy
bestPartValuei = partValue
probLeft1 = totalWeightLeft / totalWeight
probRight1 = totalWeightRight / totalWeight
IV = -1 * (probLeft * log(probLeft, 2) + probRight * log(probRight, 2))
newEntropy = minEntropy
gain = totalWeightV / totalWeight * (baseEntropy - newEntropy)
if IV == 0.0: # 如果属性只有一个值,IV为0,为避免除数为0,给个很小的值
IV = 0.0000000001
gainRatio = gain / IV
return gainRatio, bestPartValuei
二、连续属性离散化
对于连续属性,C4.5算法中策略是采用二分法将连续属性离散化处理:假定样本集D的连续属性有n个不同的取值,对这些值从小到大排序,得到属性值的集合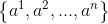
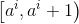
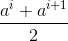
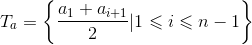
基于每个划分点t,可将样本集D分为子集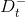
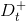

对于每个划分点t,按如下公式计算其信息增益,然后选择使信息增益最大的划分点进行样本集合的划分。
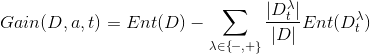
更详细的介绍参考之前的文章:机器学习笔记(5)——C4.5决策树中的连续值处理和Python实现
说明:您可以通过之前的文章了解算法的原理,其中的Python代码在后期做过优化,如果需要请下载最新的代码:https://download.csdn.net/download/leaf_zizi/10867159。(下载需要积分,如没有积分可在评论留下邮箱地址)
三、缺失值的处理
缺失值样本的处理主要考虑三个问题:
(1)如何在属性值缺失的情况下选择最优划分属性?
选择信息增益率最大的属性作为最优划分属性。对于有缺失值的属性,其信息增益是无缺失值样本所占的比例乘以无缺失值样本子集的信息增益。但在计算固有值时,要将缺失样本数也一并考虑,从而计算信息增益率。
(2)选定了划分属性,若样本在该属性上的值是缺失的,那么该如何对这个样本进行划分?
将缺失值样本按不同的概率划分到了所有分支中,而概率则等于无缺失值样本在每个分支中所占的比例。
(3)决策树构造完成后,如果测试样本的属性值不完整,该如何确定该样本的类别?
如果分类进入某个属性值未知的分支节点时,探索所有可能的分类结果并把所有结果结合起来考虑。这样,会存在多个路径,分类结果将是类别的分布而不是某一类别,从而选择概率最高的类别作为预测类别。
详细介绍参考文章:机器学习笔记(7)——C4.5决策树中的缺失值处理
四、剪枝处理
剪枝处理有预剪枝和后剪枝两种方法,预剪枝的训练时间和测试时间优于后剪枝,但是容易带来欠拟合的风险。后剪枝通常比预剪枝保留更多的分支,欠拟合风险小。但是后剪枝是在决策树构造完成后进行的,其训练时间的开销会大于预剪枝。
详细介绍参考文章:机器学习笔记(6)——C4.5决策树中的剪枝处理和Python实现
五、构建决策树和测试算法
算法的完整代码较长不便于粘贴,现已将完整代码和样本数据上传,下载地址:https://download.csdn.net/download/leaf_zizi/10867159。
资源中包含完整的代码和测试数据,其中有4个文件:C45.py是算法的实现代码,treePlotter.py是绘制决策树代码,PlayData.txt是样本数据,C45test.py用来构建、绘制并测试决策树,您可以运行该文件来依次进行决策树的构建、剪枝、绘制树型图,并对测试样本进行分类。
训练样本:

在C45test.py中,依次读取样本数据、构建决策树、对树剪枝(自编了两个验证样本)、再对测试样本分类。
import C45
import treePlotter
# 读取数据文件
fr = open(r'D:\Projects\PyProject\DecisionTree\PlayData.txt')
# 生成数据集
lDataSet = [inst.strip().split('\t') for inst in fr.readlines()]
# 样本特征标签
labels = ['Outlook', 'Temp', 'Humidity', 'Windy']
# 样本特征类型,0为离散,1为连续
labelProperties = [0, 1, 1, 0]
# 类别向量
classList = ['Play', 'Don’t Play']
# 验证集
dataSet_test = [['rain', '72', '95', 'false', 1, 'Don’t Play'], ['rain', '72', '90', 'true', 1, 'Play']]
# 构建决策树
trees = C45.createTree(lDataSet, labels, labelProperties)
# 绘制决策树
treePlotter.createPlot(trees)
# 利用验证集对决策树剪枝
C45.postPruningTree(trees, classList, lDataSet, dataSet_test, labels, labelProperties)
# 绘制剪枝后的决策树
treePlotter.createPlot(trees)
# 重新赋值类别标签和类型
labels = ['Outlook', 'Temp', 'Humidity', 'Windy']
labelProperties = [0, 1, 1, 0]
# 测试样本
testVec = ['sunny', 70, 'N', 'false']
# 对测试样本分类
classLabel = C45.classify(trees, classList, labels, labelProperties, testVec)
# 打印测试样本的分类结果
print(classLabel)剪枝前的决策树:

剪枝后的决策树:

可以看到,每个叶子节点中,除了类别还有两个数值,第一个数值为属于该分类的样本数,第二个数值为该节点中与类别相反的样本数。(为了便于计算,此处与昆兰的文章中略有不同,但不影响最后的分类结果)
对测试样本['sunny', 70, 'N', 'false']分类,得到的结果是{'Play': 2.4, 'Don’t Play': 1.0},因此该样本的分类为Play。
系列文章:
机器学习笔记(5)——C4.5决策树中的连续值处理和Python实现
机器学习笔记(6)——C4.5决策树中的剪枝处理和Python实现
代码资源下载地址(留言回复可能不及时,请您自行下载):
https://download.csdn.net/download/leaf_zizi/10867159
参考:
周志华《机器学习》
J.Ross Quinlan C4.5: Programs For Machine Learning