文章目录
一、窗口函数:
窗口函数也称为OLAP函数,OLAP 是OnLine Analytical Processing 的简称,意思是对数据库数据
进行实时分析处理。例如,市场分析、创建财务报表、创建计划等日常性商务工作。窗口函数就是为了实现OLAP 而添加的标准SQL 功能。
1.窗口函数的基本用法:
<窗口函数> OVER ([PARTITION BY <列清单>]
ORDER BY <排序用列清单>)
over关键字用来指定函数执行的窗口范围,若后面括号中什么都不写,则意味着窗口包含满足WHERE条件的所有行,窗口函数基于所有行进行计算;如果不为空,则支持以下4中语法来设置窗口。
①window_name:给窗口指定一个别名。如果SQL中涉及的窗口较多,采用别名可以看起来更清晰易读
②partition by子句:窗口按照哪些字段进行分组,窗口函数在不同的分组上分别执行
③order by子句:按照哪些字段进行排序,窗口函数将按照排序后的记录顺序进行编号
④frame子句:frame是当前分区的一个子集,子句用来定义子集的规则,通常用来作为滑动窗口使用
2.窗口函数与普通聚合函数的区别:
①聚合函数是将多条记录聚合为一条;窗口函数是每条记录都会执行,有几条记录执行完还是几条。
窗口函数兼具之前我们学过的GROUP BY 子句的分组功能以及ORDER BY 子句的排序功能。但是,PARTITION BY子句并不具备GROUP BY 子句的汇总功能。因此,使用RANK 函数并不会减少原表中 记录的行数。
②聚合函数也可以用于窗口函数。
原因就在于窗口函数的执行顺序(逻辑上的)是在FROM,JOIN,WHERE,GROUP BY,HAVING之后,在ORDER BY,LIMIT,SELECT DISTINCT之前。它执行时GROUP BY的聚合过程已经完成了,所以不会再产生数据聚合。
注:窗口函数是在where之后执行的,所以如果where子句需要用窗口函数作为条件,需要多一层查询,在子查询外面进行,例如:求30天内后一天比前一天平均时间差
select user_id,avg(diff)
from
(
select user_id,lead(log_time)over(partition by user_id order by log_time) - log_time as diff
from user_log
)t
where datediff(now(),t.log_time)<=30
group by user_id
计算移动平均
窗口函数
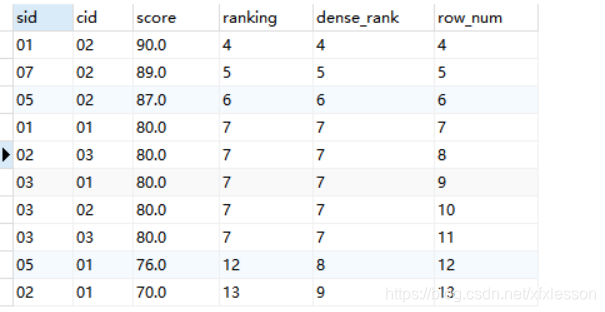
3.(面试考点)序号函数:row_number(),rank(),dense_rank()的区别
- rank函数:相同值排名相同,下一排名根据之前的记录个数而定
- dense_rank函数:相同值排名相同,排名连续不间断
- row_number函数:不管值是否相同,依次连续排名
4.分布函数:percent_rank(),cume_dist()
- percent_rank():
每行按照公式(rank-1) / (rows-1)进行计算。其中,rank为RANK()函数产生的序号,rows为当前窗口的记录总行数
SELECT
RANK() OVER w AS 排名,
PERCENT_RANK() OVER w AS 排名百分比,
sid
FROM score_table
WHERE sid = 1
WINDOW w AS (PARTITION BY sid ORDER BY score);

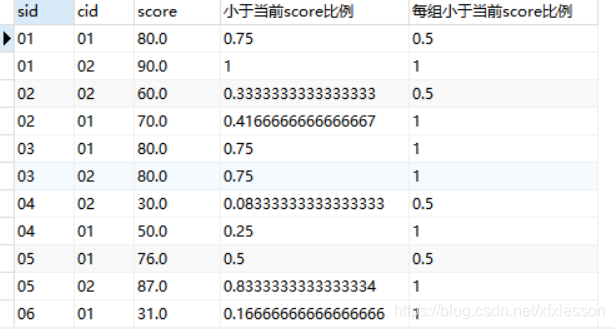
- cume_dist():
分组内小于、等于当前rank值的行数 / 分组内总行数 eg:查询小于等于当前成绩(score)的比例
SELECT *,
CUME_DIST() OVER (ORDER BY score) AS 小于当前score比例,
CUME_DIST() OVER (PARTITION BY sid ORDER BY score) AS 每组小于当前score比例
FROM score_table
WHERE cid IN ('01','02');
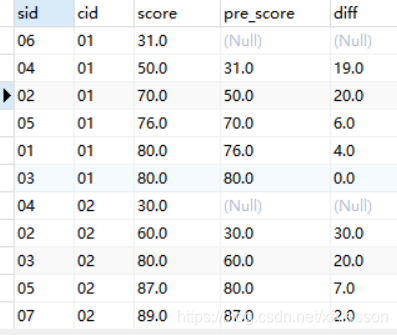
5.前后函数:lag(expr,n),lead(expr,n)
用途:返回位于当前行的前n行(LAG(expr,n))或后n行(LEAD(expr,n))的expr的值
应用场景:查询前1名同学的成绩和当前同学成绩的差值
SELECT *,score-pre_score AS diff
FROM(
SELECT sid, cid, score,
LAG(score,1) OVER w AS pre_score
FROM score_table
WHERE cid IN ('01','02')
WINDOW w AS (PARTITION BY cid ORDER BY score)) t
6.头尾函数:FIRST_VALUE(expr),LAST_VALUE(expr)
返回第一个(FIRST_VALUE(expr))或最后一个(LAST_VALUE(expr))expr的值
截止到当前成绩,按照学号查询第1个和最后1个同学的分数
SELECT *,
FIRST_VALUE(score) OVER w AS first_score,
LAST_VALUE(score) OVER w AS last_score
FROM score_table
WHERE sid IN ('01','02')
WINDOW w AS (PARTITION BY cid ORDER BY sid)

二、面试题
1.用户行为分析
表1——用户行为表tracking_log,大概字段有(user_id‘用户编号’,opr_id‘操作编号’,log_time‘操作时间’)如下所示:
user_id opr_id log_time
001 A 2020-01-01 12:01:44
001 B 2020-01-01 12:02:44
002 C 2020-02-01 11:01:44
002 A 2020-02-03 12:02:44
问题:
1.统计每天符合以下条件的用户数:A操作之后是B操作,AB操作必须相邻
分析:
(1)统计每天,所以需要按天分组统计求和
(2)A操作之后是B,且AB操作必须相邻,那就涉及一个前后问题,所以想到用窗口函数中的lag()或lead()。
select date,count(*)
from(
select user_id
from(
select user_id,convert(log_time,date) date,opr_id f,lag(opr_id,1) over(partition by user_id,convert(log_time,date) order by log_time) l
from tracking_log
) a
where f='A' and l='B'
) b
group by date;
2.统计用户行为序列为A-B-D的用户数,其中:A-B之间可以有任何其他浏览记录(如C,E等),B-D之间除了C记录可以有任何其他浏览记录(如A,E等)
select count(*)
from(
select user_id,group_concat(opr_id) ubp
from tracking_log
group by user_id
) a
where ubp like '%A%B%D%' and ubp not like '%A%B%C%D%'
2.学生成绩分析
表:Enrollments
student_id course_id grade
001 1 60
001 2 75
002 2 33
002 3 97
1.查询每位学生获得的最高成绩和它所对应的科目,若科目成绩并列,取 course_id 最小的一门。查询结果需按 student_id 增序进行排序。
分析:因为需要最高成绩和所对应的科目,所以可采用窗口函数排序分组取第一个
按每位学生的成绩排名
SELECT student_id,course_id,grade
RANK_NUMBR() OVER (PARTITION BY student_id order by grade DESC) as Rank
FROM Enrollments
ORDER BY Rank, course_id
取其中最高的成绩
SELECT student_id,course_id,grade
FROM (SELECT student_id,course_id,grade
RANK_NUMBR() OVER (PARTITION BY student_id order by grade DESC) as Rank
FROM Enrollments
ORDER BY Rank, course_id) as A
where A.Rank = 1
order by student_id
解法2:IN
先取最大成绩
SELECT student_id,max(grade)
FROM Enrollments
GROUP BY student_id
然后取成绩在最大成绩之中的学生的最小课程号的课程
2.查询每一科目成绩最高和最低分数的学生,输出course_id,student_id,score
我们可以按科目查找成绩最高的同学和最低分的同学,然后利用union连接起来
select c_id,s_id
from(
select *,row_number() over(partition by c_id order by s_score desc) r
from score
) a
where r=1
union
select c_id,s_id
from(
select *,row_number() over(partition by c_id order by s_score) r
from score
) a
where r=1;