目录
LSTM-CRF模型在英文命名实体识别任务中具有显著效果,在中文NER任务中,基于字符的NER模型也明显优于基于词的NER模型(避免分词错误对NER任务的影响),但如何在基于字符的NER模型中引入词汇信息,确定实体边界,对中文NER任务有明显提升效果。
Lattice LSTM模型是基于词汇增强方法的中文NER的开篇之作。在该模型中,使用了字符信息和所有词序列信息,避免因分词错误导致实体识别错误,在中文NER任务上有显著效果。
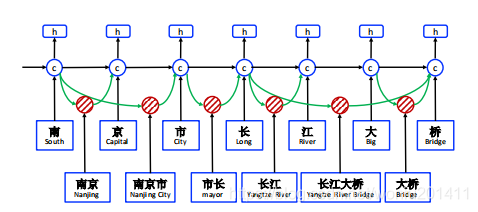
一、Lattice LSTM 模型
1、字符序列输入
Lattice LSTM处理字符序列的LSTM结构如下(原始的LSTM模型):
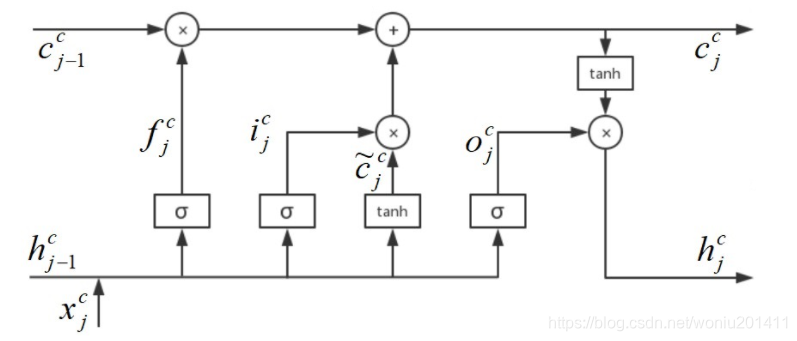
对应的数学公式如下,其中c是字粒度变量,j表示序列的当前位置,![]() 表示当前输入的字粒度信息:
表示当前输入的字粒度信息:
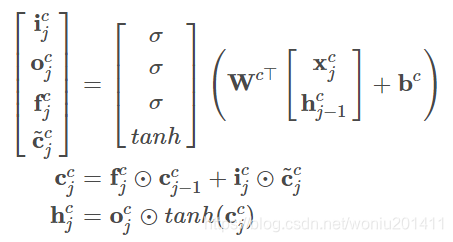
2、词粒度输入
Lattice LSTM处理词粒度的LSTM结构如下,与字符的LSTM相比,没有输出向量:
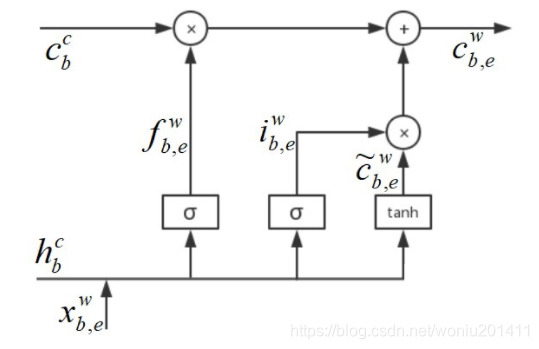
对应的数学公式:
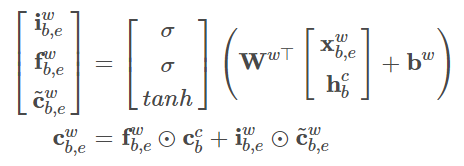
3、字粒度和词粒度信息选取
Lattice LSTM处理字符序列附加词信息,采用上述两个结构(字粒度+词粒度)的组合,通过一个额外的门控制字粒度信息与词粒度信息的选取,额外的门计算如下:
![]()
处理字粒度的隐状态变化如下:
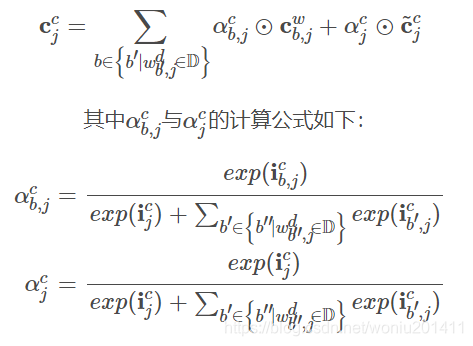
当当前位置j存在词粒度信息时,Lattice LSTM处理字粒度结构的隐状态发生了变化,隐状态用学到的词粒度信息替换掉了来自字粒度的信息,但这并不意味着将当前位置之前所有字粒度信息都丢弃了,因为词粒度信息中保留了来自词在序列中开始位置之前的字粒度信息。
二、模型训练
标准的CRF层被用在Lattice LSTM的输出向量![]() 上面,一个标签序列
上面,一个标签序列![]() 的概率为:
的概率为:
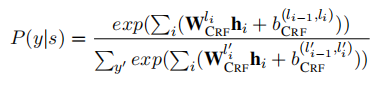
其中,分母是所有标签序列。我们需要寻找一个输入序列中得分最高的标签序列,损失函数为:
![]()
其中正则项是所有参数集合
参考文献:
<Chinese NER Using Lattice LSTM>
版权声明:本文为woniu201411原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。