一. 官方参考链接
二. Spark Streaming核心抽象DStream
简介
is an extension of the core Spark API
tenables scalable, high-throughput, fault-tolerant
stream processing of live data streams.
流
输入: Kafka, Flume, Kinesis, or TCP sockets
//To do 业务逻辑处理
输出: filesystems, databases, and live dashboards
常用流处理操作框架
Storm: 真正的实时流处理 Tuple
Spark Streaming: 并不是真正实时流处理,而是mini batch操作(将数据流按时间间隔拆分成很小的批次)
使用spark一栈式解决问题,批处理出发
receives live input data streams
divides the data into batches
batches are then processed by the Spark engine to generate
the final stream of results in batches
Flink: 流处理出发
Kafka Stream:
DStreams can be created either from input data streams from sources such as Kafka, Flume, and Kinesis, or by applying high-level operations on other DStreams.
Internally, a DStream is represented as a sequence of RDDs.


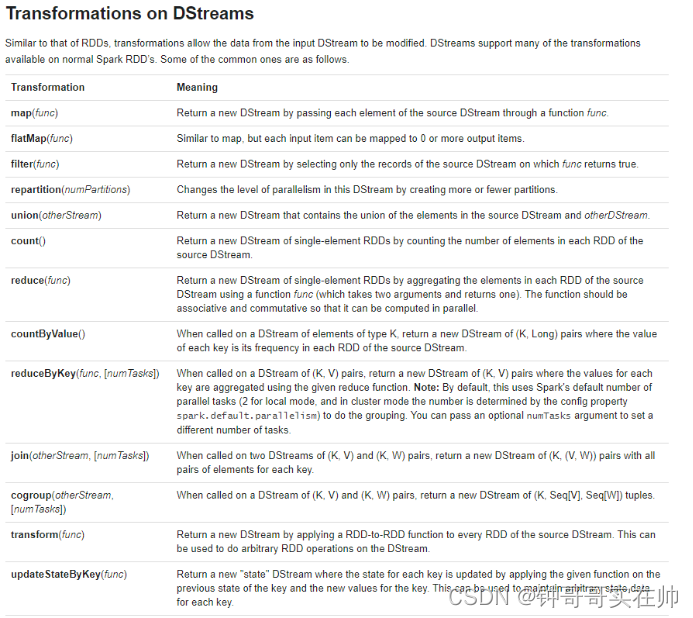

三. 范例
from pyspark import SparkContext, SparkConf from pyspark.streaming import StreamingContext,kafka if __name__ == '__main__': # nc -lk 9999 做测试 conf = SparkConf().setAppName('spark_streaming').setMaster('local[2]') sc = SparkContext(conf=conf) scc = StreamingContext(sc, 10) lines = scc.socketTextStream('localhost', 9999) words = lines.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda x, y: x+y) words.pprint() scc.start() scc.awaitTermination() # sc.stop()