本篇文章对链路预测中的3个准局部相似性指标做阐述。
准局部相似性指标考虑的信息比局部指标更多,而放弃对预测精度没有贡献或贡献很小的多余信息。
(1)
。其作用范围比

更广,定义为:
是自由参数。显然,当
时,这个度量退化为
。如果
和
不是直接连接的,
等于连接x和y的长度为3的不同路径的数目,有:
为最大阶数。随着
的增加,这一指标对信息量和计算量提出了更高的要求。特别地,当
时,
将等价于考虑网络中所有路径的
指数。该指标在不相关网络中的计算复杂度为
,随
的增加而迅速增长,当
较大时,将超过
指标的计算复杂度(近似于
)。实验结果表明,最优
与网络的平均最短距离呈正相关。
指标的性能明显优于基于邻域的索引,如
。这是因为邻域信息的可区分性较差,并且两个节点对被分配相同的相似度分数的概率很高。以INT网络为例,其共有
多个节点对,其中
的节点对被
赋值为零。对于得分高于
的所有节点对,
被分配得分
,
被分配得分
。使用更多涉及下一个最近邻居的信息可能会打破状态的退化,并使相似性得分更容易区分。这就是
指标大幅提高预测精度的原因。
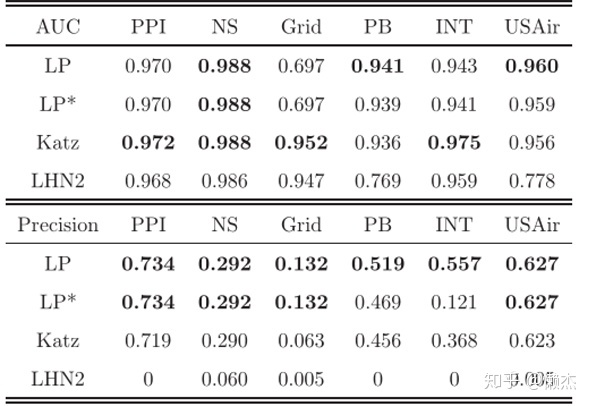
指标与另外两个依赖路径的全局指标(
和
指标)的比较如图所示,根据
值,
指标执行得最好,而
指标对于
而言是最好的。对于平均最短距离较小的网络(例如,USAIR和PB),
指标对
和
给出了最准确的预测。总而言之,与全局指标相比,而
指标提供了具有竞争力的良好预测,同时计算量要少得多。
(2)
。为了测量节点
和
之间的相似性,首先在节点
上放置一个随机游走器,因此初始密度向量
。当
时,该密度向量演化为
,则
指标在时间步长
定义为:
其中
是初始配置函数。在文献
中
和
应用了一个由节点度决定的简单形式,即
。
(3)
。与
类似,在起始点连续释放随机游走者,使得目标节点与附近节点具有更高的相似度。数学表达式为
为时间步长。
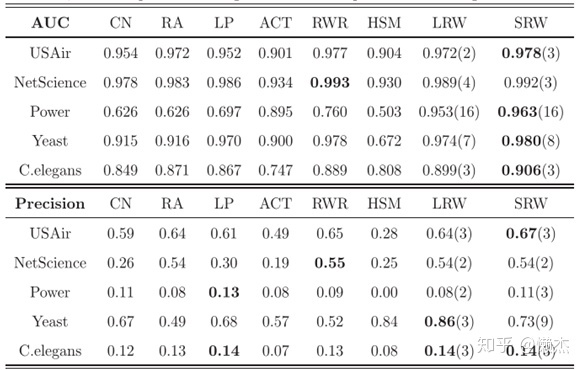
将指标
和
与三个局部(或准局部)指标
,以及另外两个基于随机游走的全局指数
和层次结构方法
进行比较。结果如图:
的参数
(在
为
),
的参数
。括号内的数字表示LRW和SRW标数的最佳步长。例如,
表示在
的第二步获得最佳
值。
和
方法的性能优于其他指标,它们各自的最优步行步长与网络的平均最短距离呈正相关。此外,
和
的计算复杂度低于
和
,其求逆和伪逆的时间复杂度约为
,而
步
和
的时间复杂度约为
,忽略了网络的异构度。也就是说,当
较小时,
和
的运行速度远远快于其他基于随机游走的全局相似性指数。
和
具有计算复杂度低的优点,在大型(即大
)和稀疏(即小
)网络中尤为突出。
与
和
动机相似。
应用于解决分类问题,既能降低时间复杂度,又能降低空间复杂度。