接下来写随手写一些上课笔记,就当作在学习探索~
存在些理解错误或偏差,也会记录些问题,看到的小伙伴懂的话可顺便给个回复或纠正些问题,看了哪些不懂的伙伴也可以留言,看到后会给回复(有些不大懂的就略过啊~)
一、数据时代的演变
票据——> 在线业务处理(OLTP)——> 数据分析查看(OL AP)
这时候的数据特点:
1.1、数据量大,如阿里巴巴亿级别;
1.2、海量并发
1.3、数据格式相对丰富:视频、音频、文本等(结构化与非结构化均有,只有只有结构化数据),如可通过视频解析球员在球场位置。
2、DIKM
数据(data) ——> 信息(information) ——> 知识(knowledge) ——> 智慧(wisdom)
| 开源数据库(不要钱的) | mysql、postgre sql |
| 商用数据库(要收钱的) | oracle、DB2、MySQL Server(1989)、SAP Sybase ASE(1987) |
数据库特点
| 数据库 | 特点 |
| Teradata(1984) | 一体机、MPP、列存 |
| SAP SYbaseIQ | 列存、数据及索引 |
| SAP HANA | 内存数据库、列存、一体机 |
| IBM Netezza | AMpp、FPGA、一体机 |
| Oracle ExaPata | 一体机、Mpp |
| EMC GreenPlum | 列存、一体机、Mpp |
nosql(not only sql)
| nosql数据库分类 | 数据库 |
| 健值存储数据库 | Redis、Riak、Mencacha DB |
| 列值存储数据库 | Hbase. Carssandra |
| 文档型数据库 | MongoDB. couchDB |
| 图形数据库 | Neo4J InfoGrid Infinite. Graph |
二、建模基本流程
1、概念型模型
确定系统的核心,以及划清系统范围和边界
2、逻辑型模型
梳理业务规则以及对概念模型的求精
3、物理型模型
从性能、访问、并发等多方面考虑,做系统实现
数据表搭建注意点:
1、先规范化、再逆规范化
2、使用case工具做逻辑模型
3、成熟的模型pattern
4、逻辑模型占时比较多,约80%
高质量模型的定义:
1、重要关联关系需要、强制建立主外健
2、DDL中注意注释的生成、元数据的读取
三、实体分类方式
1、5WH:what、where、who、when、why、how
2、按照含义定义(IBM):
2.1、安排(how)
2.2、业务指导(如合同)(what)
2.3、相关方(who)
2.4、产品(what)
2.5、事件(what)
2.6、资源(why)
2.7、位置(where)
2.8、分类(5wh 没有提到该点,但该点却也是建模的重要依据)
四、属性分类
不是官方分类方法,是看视频课时老师提出的,仅供参考
1、ID
2、描述
3、饮用
4、分类
5、限制
6、数量
7、时间相关
8、人物相关
9、地点相关
10、状态
11、审计(如时间撮、更新人等)
12、派生
五、属性值的一些特点
1、强制还是可选
2、原子还是组合、直接还是派生;
3、单指还是多值
4、可选健
5、属性数据类型(字符串、整数、浮点数等)
6、是否有默认值
7、派生属性如何计算(加注释说明)
六、域(Domain)
可用来增加约束,一个域可以是一组符合一定规范的数据组合,如性别:男、女,年龄:1~150岁。
域带来的好处
提高数据质量(如年龄如果随便输入200、张三等不符合要求,被过滤掉)
域类型
1、格式:email、varchar、integer...(如上面的性别为字符串、年龄为整数)
2、列表:枚举、Gender(如上面的性别)
3、范围:from X to Y (如上面的年龄)
七、关系
定义:实体域实体之间的关系
实体、域、关系之间的个人解释
实体
可以理解为一张张表,如用户表、商品表等
属性
其实是实体的介绍,也就是列表中的列信息,如用户表中的用户ID、用户名、地址、年龄、性别等...
域
属性的取值约束,属于数据类型的一部分(不能直接定、需要补充定义的那部分)。如用户ID数据类型为char(8),这个可以直接定义,就不管;
但用户年龄,选择integer(整数)还不够,因为要限制在1~150岁之内(提高数据质量),那么久需要增加一个域;
再如用户性别,单独一个字符串要求是不够的,你可以提供两个选项:男、女(还可未知),这两三个选项就是性别的域。
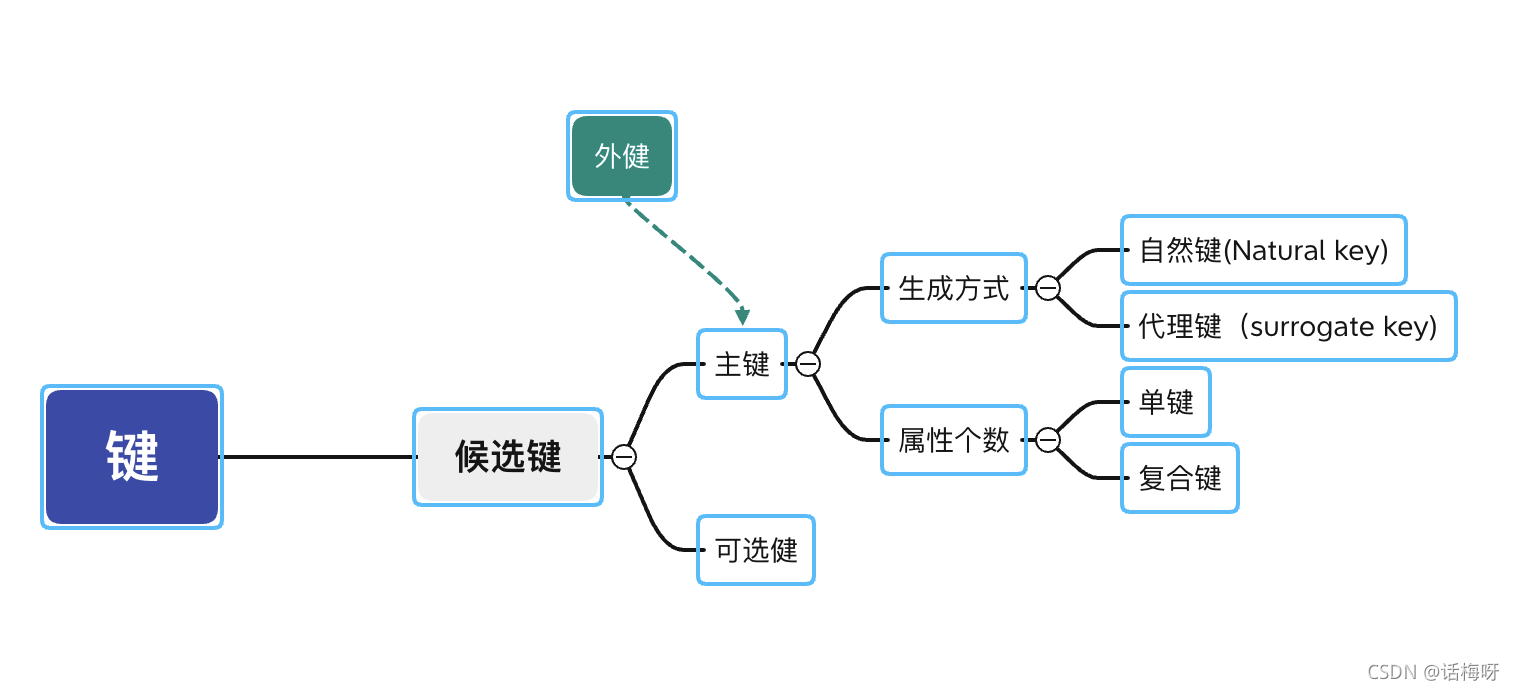
八、健
1、侯选健
一个或多个属性的组合,可以唯一确定实体的一个实例(简单一点理解就是表中的列值,或是实体中的一个个属性值)
2、主键(primary key)
从侯选健中选择一个或多个用来作为对应实体的唯一标识。
主键的特点:
2.1、唯一性,不可重复
2.2、强制性:不可为空
2.3、永久性:不可改变
2.4、最小集合:不可参杂多余的属性
3、可选健
候选健中除了主键,剩下就是可选健
4、单键(simple Key):
主键如果是一个属性值(一个列值),称为单键
5、复合健(composite key)
如果主键是多个属性值组合,称为复合健
6、外健
引用其他表的主键,保证数据的一致性与唯一性
员工表有“员工ID”(主键),但员工工资表中,主键(复合健)为“月份”与员“工ID”(也就是某月份中某员工的工资),那么员工ID则是员工工资表的外健,外健可以为空(现在还不知道这是啥逻辑)
7、自然健
有商业意义的健,可单键或复合健(单键可作为搜索),如身份证号码(可代码居民),输入可搜索到居民个人信息
8、代理健
没有商业价值,当下系统自动生成、只能为单键。
它们的关系可整理为:
自然健 VS 代理健
| 自然健 | 代理健 | |
| 灵活性 | 主键不可修改(永久性),实体主键改变会带来外健相关表的连锁反应 (如员工离职后复职),如用员工身份证为主键,那么该主键作为外健的相关表不好更新(可能会理解直接删除该行数据就行,蒙圈中 ...) | 代理健本身无意义,可以修改原自然健内容 |
| 新系统接入时,合并存在一定的困难 | 新系统接入时,合并维度表相对容易 | |
| 程序编写 | 相对事实表而言,如需按照自然健直接搜索,则可以不用关联到维度表 | 由于代理健无法直接作为查询条件,因此无须关联到维度表进行关联查询 |
| 如果维度表时复合健,则程序书写更复杂 | 代理模型相对简单 | |
| 查询功能 | 数据大于100万时,时间相对长 | 时间缩短在10%左右(相对于自然健) |
| 存储空间 | 就维度表而言,占用空间少; 事实表而言:视各个维度健值数据类型而定,通常需要更多空间; 总体来看相对占空间。 (小补充:数据仓库中事实表占据空间较大,约80%) | 维度表而言:需要更多空间; 事实表而言:视各个维度健值数据类型而定,通常占用较少空间; 总体来看占空间相对少 |
| 数据加载 | 就维度而言,直接从源系统过数据,除正常转换外,没有额外开销 | 就维度表而言。代理健插入须计算新插入的代理健值 |
整体而言,代理健相对于自然健好处多多。
代理健使用的其他场景
1、没有主键时
2、主键复合健很多时(程序写起来很麻烦,需要很多where)
数据仓库特点的处理方式
特点:多并发
处理方式:
1、高低位法:XXX - YYYYYYYY。 比如多个node同时加载,则XXX表示node编号;YYYYYYYY为自动生成的序列号,比如101 00000001,102 00000001 ......
2、UUID,GUID:以太网卡 MAC地址便秘 + 时间撮
九、约束(constraint)
约束存在的目的是根据需要把商业规则应用到数据库的设计中。
1、唯一标识,唯一确定实体
2、非空约束
3、默认值
4、检查
5、参照完整性(RI),保证数据质量
4、非空约束
1、建表时设定 not null
2、check 时设定 is not null
正则表达
5、参照完整性(可以理解为设置约束条件)
none、Restrict、cascade、set null 、set default
none、Restrict:不能延时生效,数据删啦,但维表还在
cascade:直接删主表数据,也把维度表记录删啦
set null 、set default:只是单独删除了数据
这一part不是很懂