前言
最近公司有一个客户是使用PostgreSql来存储数据的,然后在导出功能中,发现在大数据的情况下,内存会一直增长直至内存溢出。因为按道理导出功能是设置了fetchSize来进行流查询了,按道理是不会内存溢出的。然后排查发现,获取数据是全部获取了,那肯定会内存溢出了。
具体什么是流查询,待写完下篇文章后就链接到这里。
目录
1、排查思路
首先,既然是内存溢出了,那肯定得先排查溢出的地方,以及为什么会溢出。
1.1 接到的bug是导出功能,内存一直增长不释放直至溢出,此时就简单了,直接打开java自带的jvisualvm,监控导出时内存的占用情况及线程的dump
1.2 经过jvisualvm监控后发现,线程并没有死锁或者wait过长的情况,并且发现耗时最长的线程是在CSVExport方法中,此时就可以判断出是这个方法导致了内存溢出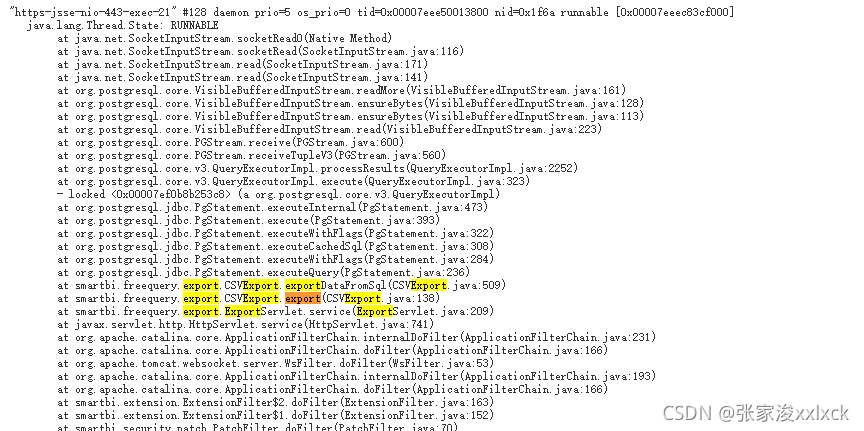
1.3 然后再去看内存监控的界面,看是哪个对象一直占用了内存,后发现是CellData(产品的数据存储对象),发现实例数及其的高,以及在eden区GC的时候并没有释放此内存,那很明显就是将数据库的数据全都获取出来了。
链接: 对象内存计算方式请看此博客.
1.4 但是又开始迷惑了,因为在我们的导出系统中,如果是大数据导出的话,会设置fetchSize设置游标查询获取数据,此时是不会获取全部数据在内存中的,如果全部数据都在内存了,那唯一的可能就是游标查询没生效。此时就要去解决为什么游标查询没生效了
2、解决过程
1.1 首先要了解游标查询没生效,很大的可能是因为数据库的设置有问题,如 Mysql游标查询不生效. 对于普通的数据库如oracle来说,简单的给jdbc设置setFetchSize()即可开启游标查询。但是当前来源数据库是 PostgreSql,那这个时候就得去看PostgreSql的文档以及源码,看得什么时候开启游标查询。
1.2 通过文档:https://jdbc.postgresql.org/documentation/head/connect.html,发现确实是支持流查询的

1.3 由于之前已经有处理过mysql游标查询不生效的问题,所以怀疑是连接字符串的问题,但是发现也没设置什么,只是设置了preferQueryMode =simple而已,然后尝试去除此属性。后续就发现,成功了使用流查询去获取数据了!但是为什么呢?这个就得去跟源码了(此时已经解决了内存溢出的问题了)
3、源码解析
1. 首先,我们得先拿到postgreSql的源码: https://github.com/pgjdbc 从github上把postgreSql的jdbc源码拉下来
2. 由于jdbc是通过返回resultSet包装数据的,那此时要判断是否是流式查询的话,基本上就是去找 getResultSet类似的方法,看到底是怎么开启查数的逻辑
3.找到类:
postgresql-9.4.1212.jre7-sources.jar!/org/postgresql/jdbc/PgPreparedStatement.java
查看到方法为 executeInternal
private void executeInternal(CachedQuery cachedQuery, ParameterList queryParameters, int flags)
throws SQLException {
closeForNextExecution();
// Enable cursor-based resultset if possible.
if (fetchSize > 0 && !wantsScrollableResultSet() && !connection.getAutoCommit()
&& !wantsHoldableResultSet()) {
flags |= QueryExecutor.QUERY_FORWARD_CURSOR;
}
if (wantsGeneratedKeysOnce || wantsGeneratedKeysAlways) {
flags |= QueryExecutor.QUERY_BOTH_ROWS_AND_STATUS;
// If the no results flag is set (from executeUpdate)
// clear it so we get the generated keys results.
//
if ((flags & QueryExecutor.QUERY_NO_RESULTS) != 0) {
flags &= ~(QueryExecutor.QUERY_NO_RESULTS);
}
}
if (isOneShotQuery(cachedQuery)) {
flags |= QueryExecutor.QUERY_ONESHOT;
}
// Only use named statements after we hit the threshold. Note that only
// named statements can be transferred in binary format.
if (connection.getAutoCommit()) {
flags |= QueryExecutor.QUERY_SUPPRESS_BEGIN;
}
// updateable result sets do not yet support binary updates
if (concurrency != ResultSet.CONCUR_READ_ONLY) {
flags |= QueryExecutor.QUERY_NO_BINARY_TRANSFER;
}
Query queryToExecute = cachedQuery.query;
if (queryToExecute.isEmpty()) {
flags |= QueryExecutor.QUERY_SUPPRESS_BEGIN;
}
if (!queryToExecute.isStatementDescribed() && forceBinaryTransfers
&& (flags & QueryExecutor.QUERY_EXECUTE_AS_SIMPLE) == 0) {
// Simple 'Q' execution does not need to know parameter types
// When binaryTransfer is forced, then we need to know resulting parameter and column types,
// thus sending a describe request.
int flags2 = flags | QueryExecutor.QUERY_DESCRIBE_ONLY;
StatementResultHandler handler2 = new StatementResultHandler();
connection.getQueryExecutor().execute(queryToExecute, queryParameters, handler2, 0, 0,
flags2);
ResultWrapper result2 = handler2.getResults();
if (result2 != null) {
result2.getResultSet().close();
}
}
StatementResultHandler handler = new StatementResultHandler();
result = null;
try {
startTimer();
connection.getQueryExecutor().execute(queryToExecute, queryParameters, handler, maxrows,
fetchSize, flags);
} finally {
killTimerTask();
}
result = firstUnclosedResult = handler.getResults();
if (wantsGeneratedKeysOnce || wantsGeneratedKeysAlways) {
generatedKeys = result;
result = result.getNext();
if (wantsGeneratedKeysOnce) {
wantsGeneratedKeysOnce = false;
}
}
}
其实可以发现是存在flags |= QueryExecutor.QUERY_FORWARD_CURSOR这种判断,就是说明当前获取数据用的方式是直接使用 flags这个变量得数值来判断的。然后我们可以看到,如果要游标查询的话,就需要满足此判断:
fetchSize > 0 && !wantsScrollableResultSet() && !connection.getAutoCommit()
&& !wantsHoldableResultSet()
/** 首先是
1、 fetchSize设置要大于0(我们setFetchSize了所以肯定大于0)
2、wantsScrollableResultSet()得为false(后续说)
3、connection.getAutoCommit()不能自动提交,此时jdbc.setCommit(false)即可
4、 !wantsHoldableResultSet() (代码直接返回的false,所以,不考虑这个) */
// 在源码中
protected boolean wantsScrollableResultSet() {
return resultsettype != ResultSet.TYPE_FORWARD_ONLY;
}
// statement默认是TYPE_FORWARD_ONLY的,那其实wantsScrollableResultSet也可以忽略
但是以目前来看,我们四个条件都是true,那应该就会去到方法里面 调用 flags |= QueryExecutor.QUERY_FORWARD_CURSOR;但是为什么还是不行呢?
因为:flags不是boolean,而是一个int类型,主要是通过数值大小来匹配用什么查询
// 代码我就不贴上来了,给路径自己去看
/**
processResults方法获取数据
postgresql-9.4.1212.jre7-sources.jar!/org/postgresql/core/v3/QueryExecutorImpl.java*/
/**
其实大概流程是这样
1、通过一系列的判断,去计算falgs数值
2、在processResults方法中判断falgs数值的大小,如果大于xx就会使用其他查询。
3、整体来说就是,由于刚才设置了preferQueryMode =simple,就会导致进入了下面的判断,而看QueryExecutor类的枚举,QUERY_EXECUTE_AS_SIMPLE是很大的,如果设置了此值,就会直接覆盖到游标查询了。
*/
if (connection.getPreferQueryMode() == PreferQueryMode.SIMPLE) {
flags |= QueryExecutor.QUERY_EXECUTE_AS_SIMPLE;
}
总结
总结下来,如果PostgreSql想要使用游标查询的话,需要以下几个条件
1、fechSize设置需要 > 0
2、jdbc连接字符串不能加 preferQueryMode =simple
3、需要设置autocommit为false