首先,我们现在kiban上面绘制自己需要统计出来的数据
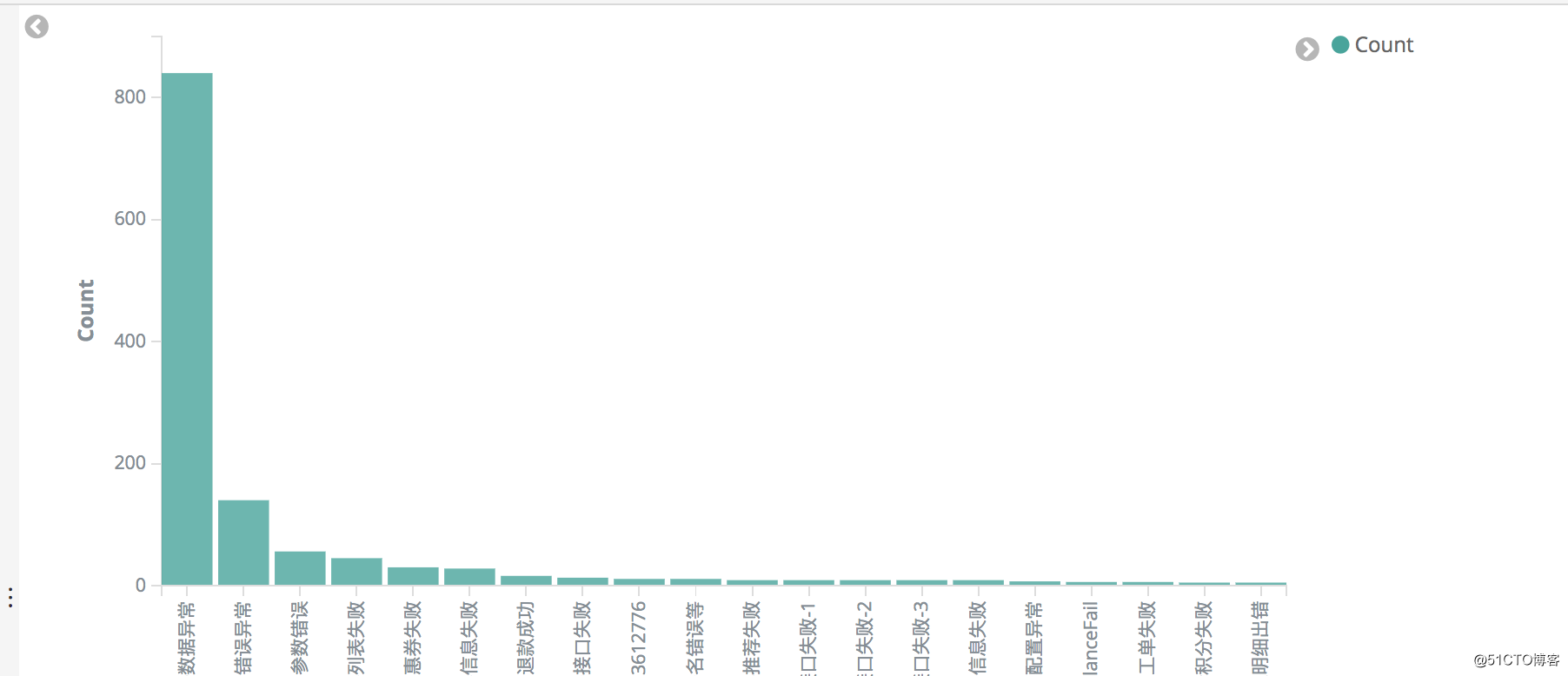
然后点击右上角inspect,将request的json格式复制
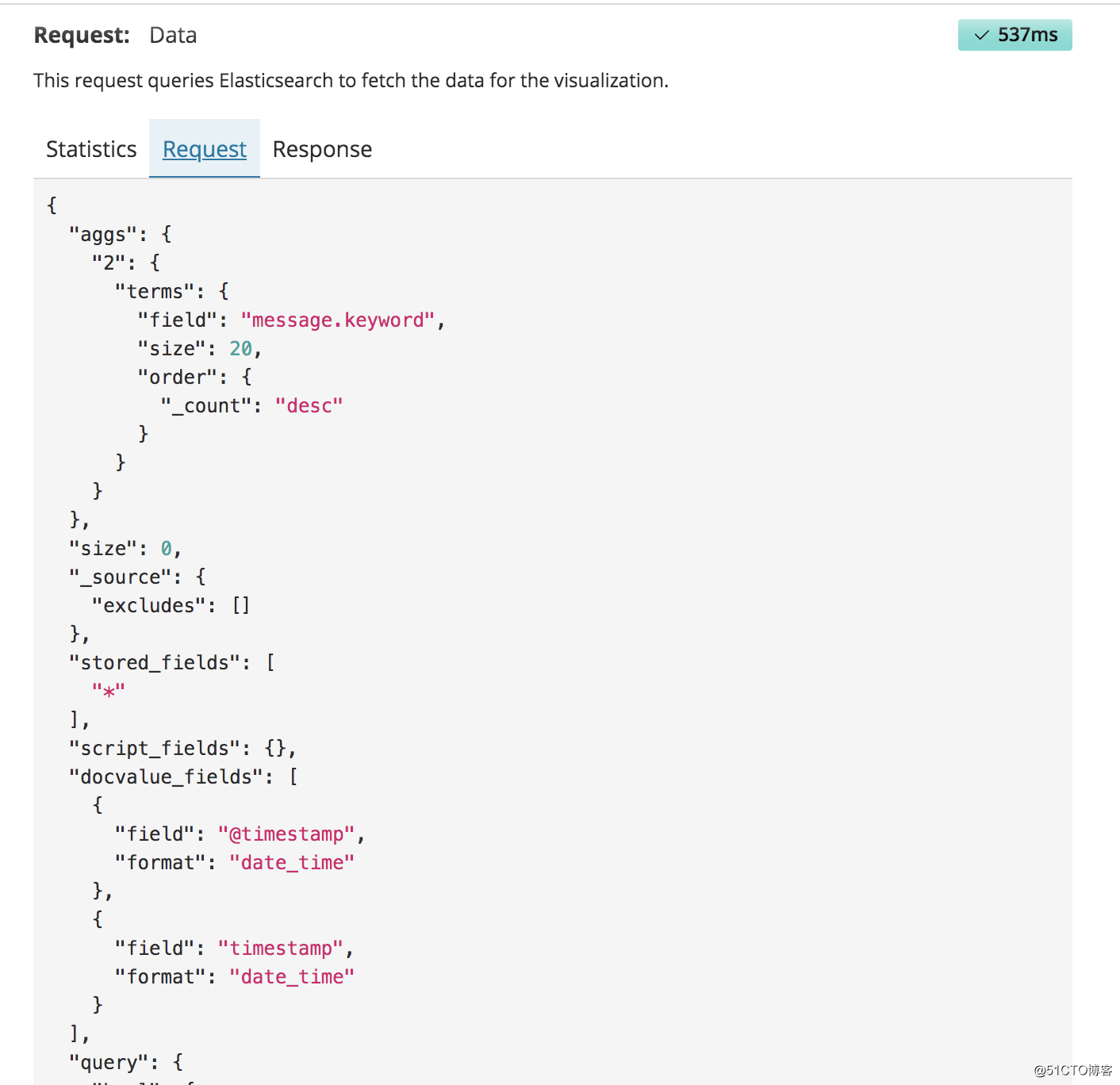
粘贴到Dev Tools上面,这样会将我们需要的数据,已json的形式返回
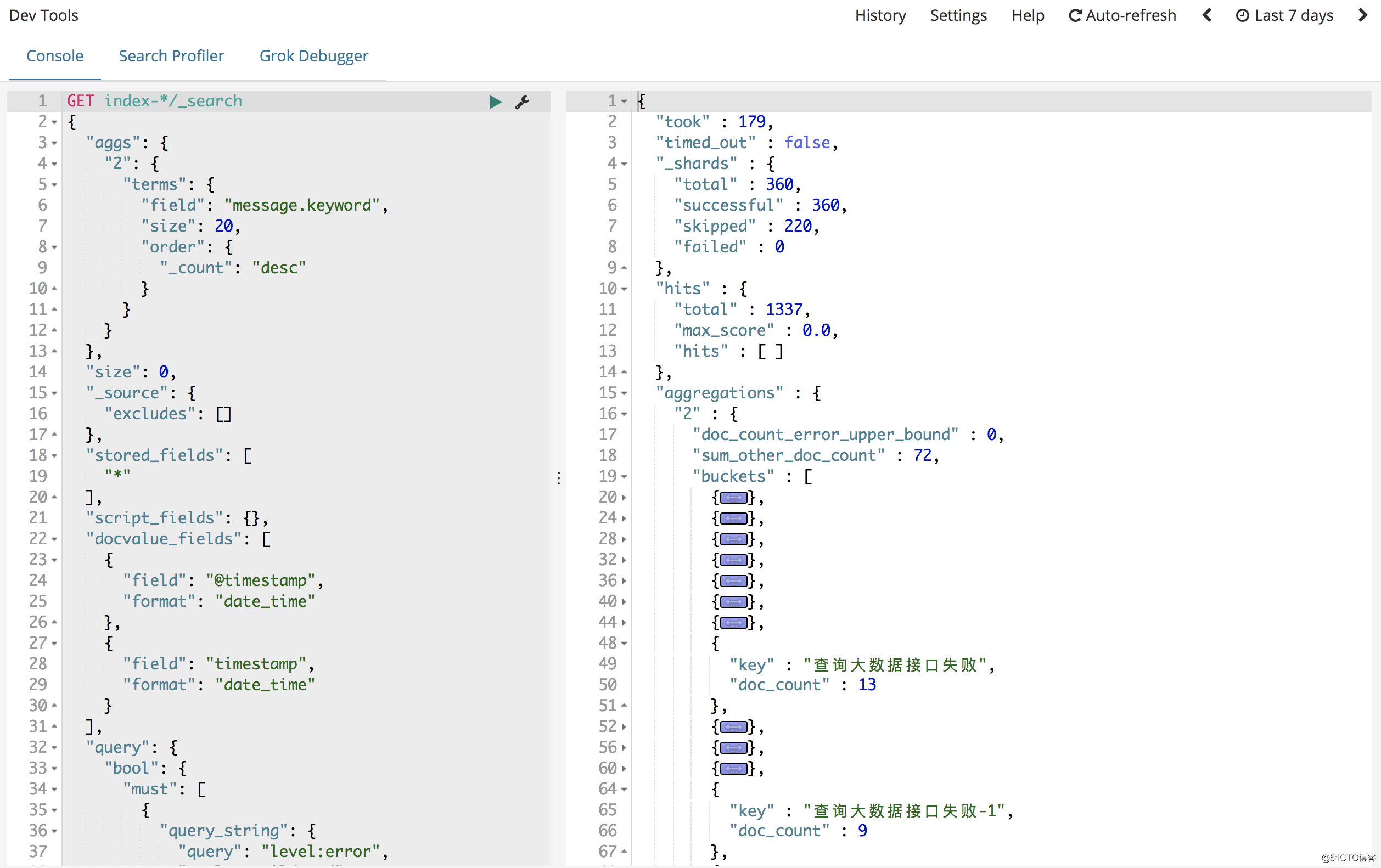
将请求的json格式保存下来,开始写py文件from elasticsearch import Elasticsearch
import datetime
#初始化链接
es = Elasticsearch([{'host':'10.3.2.1','port':9200}])
#获取当前时间和7天前的UTC格式时间戳
last_7day=datetime.datetime.utcnow()-datetime.timedelta(days=6, hours=16)
now_time=datetime.datetime.utcnow()+datetime.timedelta(hours=8)
last_7day=last_7day.strftime('%Y-%m-%dT%H:%M:%S.%f%z')
now_time=now_time.strftime('%Y-%m-%dT%H:%M:%S.%f%z')
#定义DSL请求体
query_json={
"aggs": {
"2": {
"terms": {
"field": "message.keyword",
"size": 30,
"order": {
"_count": "desc"
}
}
}
},
"size": 0,
"_source": {
"excludes": []
},
"stored_fields": [
"*"
],
"script_fields": {},
"docvalue_fields": [
{
"field": "@timestamp",
"format": "date_time"
},
{
"field": "timestamp",
"format": "date_time"
}
],
"query": {
"bool": {
"must": [
{
"query_string": {
"query": "level:error",
"analyze_wildcard": "true",
"default_field": "*"
}
},
{
"range": {
"@timestamp": {
"gte": last_7day,
"lte": now_time,
}
}
}
],
"filter": [],
"should": [],
"must_not": []
}
}
}
res=es.search(index='index-*', body=query_json)
res=res['aggregations']['2']['buckets']
for i in res:
print(i)