利用朴素贝叶斯贝叶斯算法实现分类
本文主要通过python构建朴素贝叶斯分类算法:
原理:
贝叶斯公式,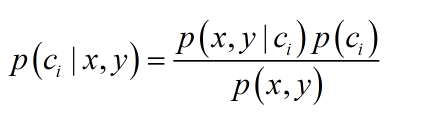
朴素的理解:假设个特征之间相互独立,则上面公式中: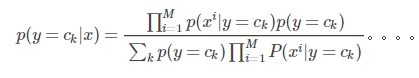
通过此公式,可将未知的条件概率转换为已知条件概率的计算
实现步骤:
1,创建Beyes类
2,类中包括四个方法,初始化方法用来创建保存中间计算结果的容器
3,fit 方法用来计算数据长度、计算条件概率所需数据集、
P(X)=∑kP(X|Y=Yk)P(Yk)
计算P(Yk):p_train_target
4,p_test_data用来计算一个样本的分类结果
5,classifier用来计算测试集所有分类结果
6,score用来计算准确率
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
import time
class Beyes(object):
def __init__(self):
self.length = -1 # 保存测试集数据量
self.train_target_list = [] # 目标值类别集合
self.p_train_target = {} # 保存个目标值概率
self.split_data_lis = [] # 保存各条件概率对应的数据集
self.feature_p_lis = [] # 保存特征概率
self.predict = [] # 保存分类结果
def fit(self, train_data, train_target):
"""
P(X)=∑kP(X|Y=Yk)P(Yk)
计算P(Yk):p_train_target
准备计算条件概率所需数据集:self.split_data_lis
:param train_data:<arr_like>
:param train_target:<arr_like>
:return:
"""
train_length = train_data.shape[0]
self.length = train_length
target_list = list(set(train_target)) # 队训练集目标值去重
self.train_target_list = target_list # 写入对象特征
target_classifier = dict(Counter(train_target)) # 保存目标值的分类计数(字典格式)
train_data = pd.DataFrame(train_data)
train_data['target'] = train_target # 将数据转换为DataFrame格式方便后续聚合
for target in self.train_target_list:
self.p_train_target[target] = target_classifier[target]/self.length # 保存各目标值的概率
split_data = train_data[train_data['target'] == target]
self.split_data_lis.append(split_data)
print('model had trained please use classifier() to get result')
def p_test_data(self, sample):
"""
映射函数:取测试集的一个样本,计算各特征对应条件概率及最终的分类结果
并将结果映射到测试集的target列
:param sample:Serise
:return self.train_target_list[position]:概率最大的类别
"""
result_p = []
for j in range(len(self.train_target_list)):
p_label = 1
this_target = self.train_target_list[j]
this_data = self.split_data_lis[j]
for i in range(0, sample.shape[0]):
feature_num_dict = dict(Counter(this_data[i])) # 计算一列数据中各类别的数量
if sample[i] in feature_num_dict:
label_num = feature_num_dict.get(sample[i])
p_label = p_label*(label_num/this_data.shape[0]) # 计算单个特征的条件概率
else:
# 加入拉普拉斯平滑系数解决概率为0的情况'
p_label = p_label*(1/(this_data.shape[0]+len(feature_num_dict)))
this_target_p = p_label*self.p_train_target.get(this_target) # 计算该样本属于该特征的概率
result_p.append(this_target_p)
position = result_p.index(max(result_p)) # 概率最大的分类
return self.train_target_list[position]
def classifier(self, test_data):
"""
计算分类结果
:param test_data:Serise
:return:
"""
if self.length == -1:
raise ValueError('please use fit() to train the train data set ')
else:
test_data = pd.DataFrame(test_data)
test_data['target'] = test_data.apply(self.p_test_data, axis=1) #
self.predict = list(test_data['target'])
print('classfier result:', self.predict)
def score(self, test_target):
"""
计算准确率
:param test_target:
:return:
"""
if len(self.predict) == 0:
raise ValueError('please use classifier() to get classifier target')
else:
count = 0
for i in range(0, test_target.shape[0]):
if test_target[i] == self.predict[i]:
count += 1
score = count/(test_target.shape[0])
print('the Classification accuracy is:', score)
if __name__ == '__main__':
"""
;用sk_learn中的鸢尾花数据集测试
"""
iris = load_iris()
x = iris.data
y = iris.target
x_train, x_test, y_train, y_test = train_test_split(x, y)
print('训练集数据量', x_train.shape)
print('测试集数据量', x_test.shape)
start_time = time.time()
classifier = Beyes()
classifier.fit(x_train, y_train)
classifier.classifier(x_test)
classifier.score(y_test)
end_time = time.time()
time_d = end_time-start_time
print("spend time:", time_d)
程序运行结果如下
版权声明:本文为weixin_42466690原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。