参考链接
CTC算法全称叫:Connectionist temporal classification。从字面上理解它是用来解决时序类数据的分类问题 。
---- 背景提出
OCR识别也可以采用RNN+CTC的模型来做,将包含文字的图片每一列的数据作为一个序列输入给RNN+CTC模型,输出是对应的汉字,因为要好多列才组成一个汉字,所以输入的序列的长度远大于输出序列的长度。而且这种实现方式的OCR识别,也不需要事先准确的检测到文字的位置,只要这个序列中包含这些文字就好了。
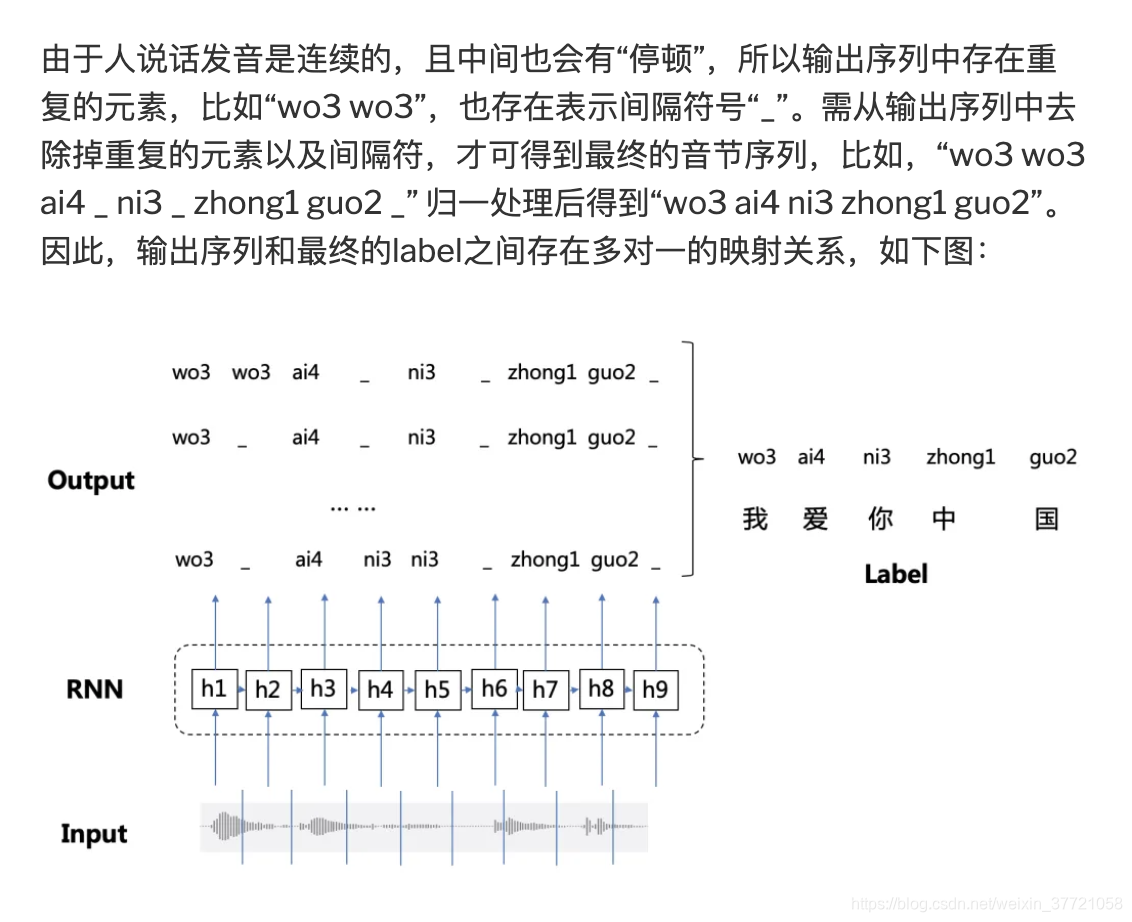
比如输入一个200帧的音频数据,真实的输出是长度为5的结果。 经过神经网络处理之后,出来的还是序列长度是200的数据。比如有两个人都说了一句nihao这句话,他们的真实输出结果都是nihao这5个有序的音素,但是因为每个人的发音特点不一样,比如,有的人说的快有的人说的慢,原始的音频数据在经过神经网络计算之后,第一个人得到的结果可能是:nnnniiiiii…hhhhhaaaaaooo(长度是200),第二个人说的话得到的结果可能是:niiiiii…hhhhhaaaaaooo(长度是200)。这两种结果都是属于正确的计算结果,可以想象,长度为200的数据,最后可以对应上nihao这个发音顺序的结果是非常多的。CTC就是用在这种序列有多种可能性的情况下,计算和最后真实序列值的损失值的方法。同理在OCR中因为文字的各种变形,所以其实同一个字可能大小是不一样的,变形很多,所以我们也是将一个字可能被拆分成多个列。
CTC(Connectionist Temporal Classification)算法,它可以让RNN直接对序列数据进行学习,而无需事先标注好训练数据中输入序列和输出序列的映射关系,打破了RNN应用于语音识别、手写字识别等领域的数据依赖约束,使得RNN模型在序列学习任务中取得更好的应用效果
---- 提出问题:
在语音识别、手写字识别等任务中,由于音频数据和图像数据都是从现实世界中将模拟信号转为数字信号采集得到,这些数据天然就很难进行“分割”,这使得我们很难获取到包含输入序列和输出序列映射关系的大规模训练样本(人工标注成本巨高,且启发式挖掘方法存在很大局限性)。因此,在这种条件下,RNN无法直接进行端到端的训练和预测。
那么,如何让RNN模型实现端到端的训练成为了关键问题。CTC的核心思路主要分为以下几部分:
1.它扩展了RNN的输出层,在输出序列和最终标签之间增加了多对一的空间映射,并在此基础上定义了CTC Loss函数 ----- 多对一的情况
2.它借鉴了HMM(Hidden Markov Model)的Forward-Backward算法思路,利用动态规划算法有效地计算CTC Loss函数及其导数,从而解决了RNN端到端训练的问题 ----- 动态规划的路径计算
3.最后,结合CTC Decoding算法RNN可以有效地对序列数据进行端到端的预测 -----预测问题
---- 本质上是基于最大似然的损失函数
1.路径的最大概率乘积:
传统分割与CTC的区别:我们在OCR中也是这样的,我们将输入的图片最终输出一个H*W的特征图,其中宽度是特征的,而高度是每个的概率,最终通过这些每一列取一个特定的数概率最大的,组合就是我们的输出预测组合了。这就是我们核心。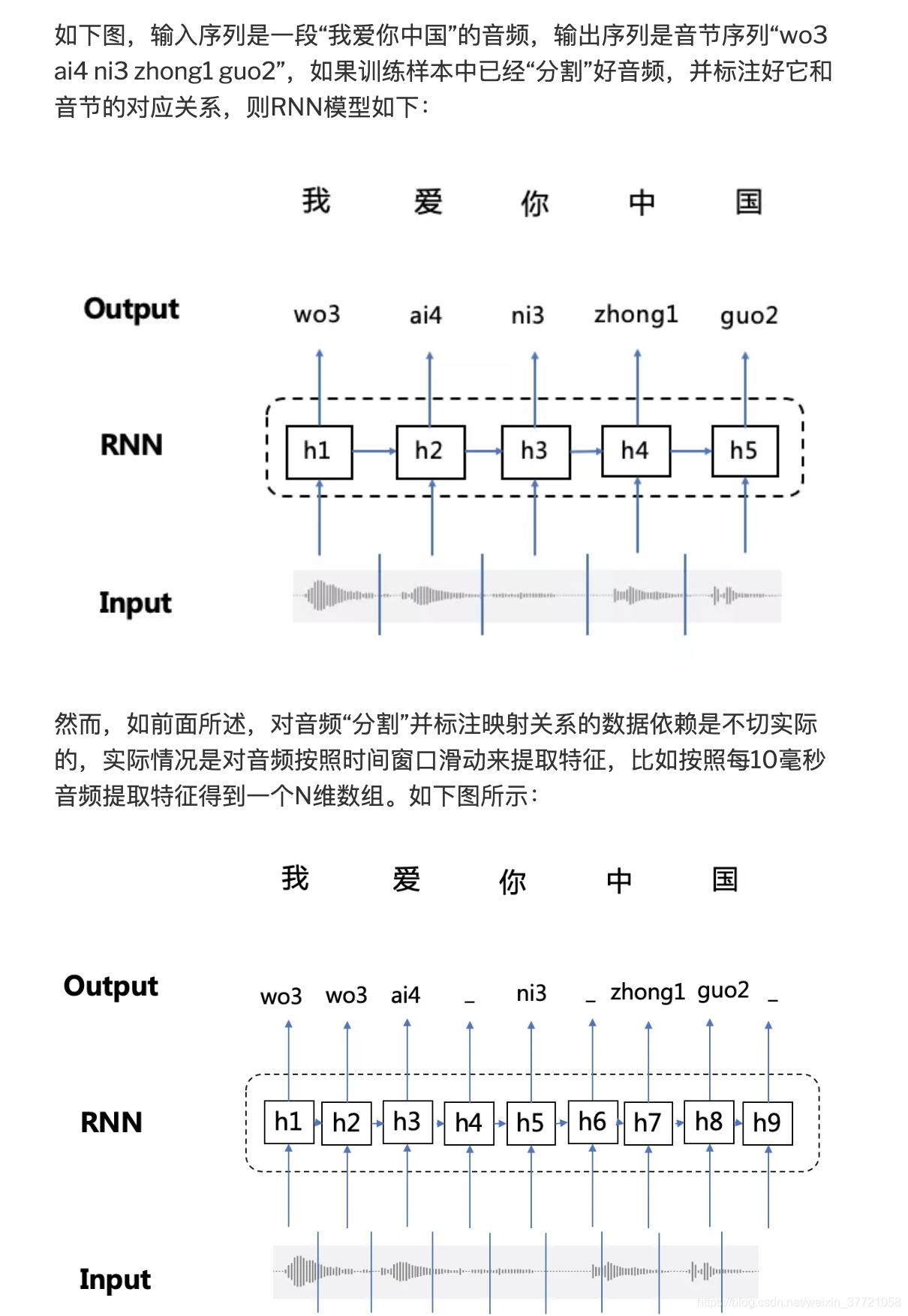

通过上面我们就明确了,解决不对其的方法是通过路径的概率最大的输出路径,训练的过程我们希望这些为目标的路径的概率之和最大。
2.损失函数的定义:
本质上就是最大似然函数的问题,通过概率最大作为我们的目标来解决序列的问题,也就是希望最终的符合目标的全部序列的概率是最大。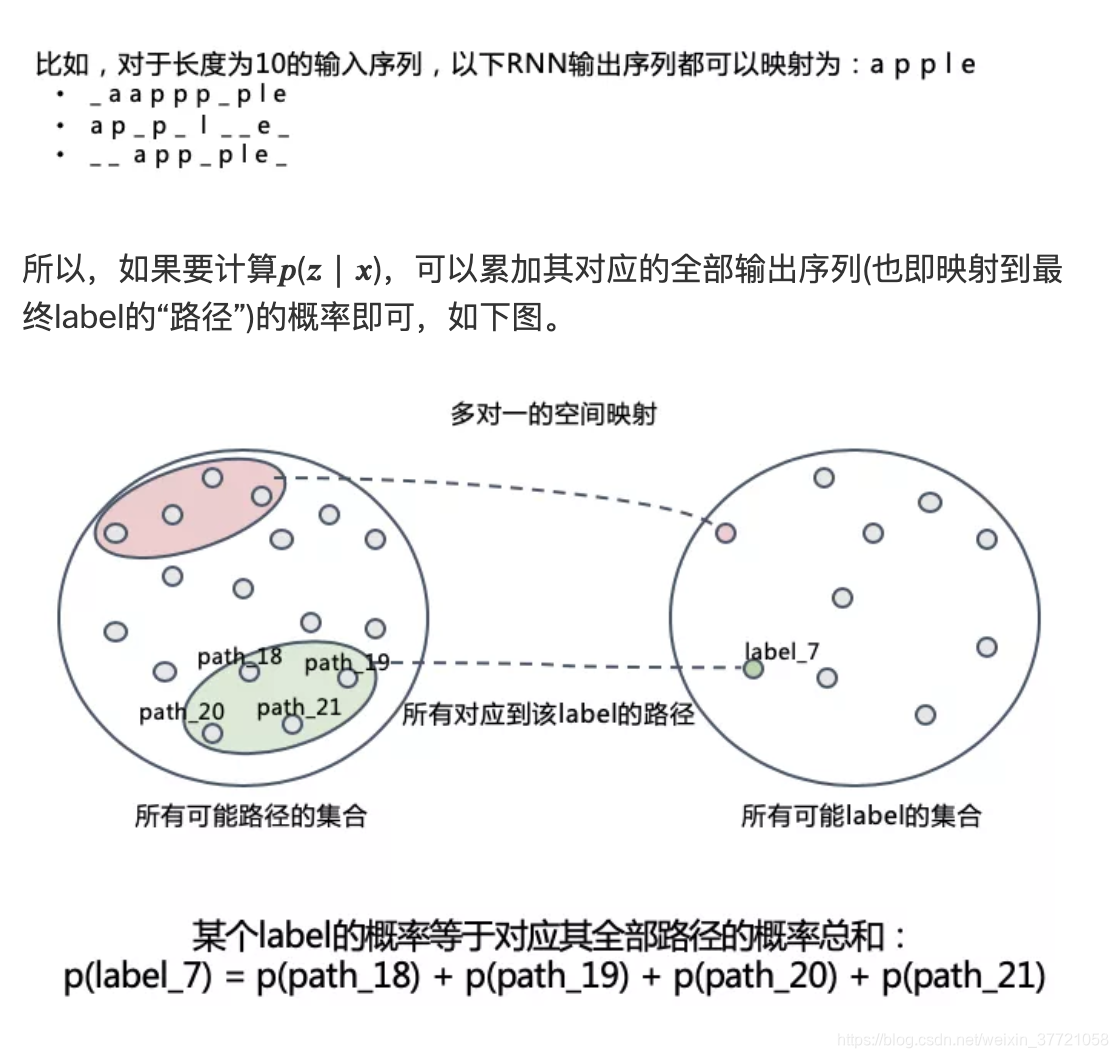
到这里我们的目标函数,或者说我们的损失函数已经非常明确了,全部路径的概率总和最大,即可。这样训练的模型可以让他们的组合概率最大。接下来我们需要做的就是通过有效的方法计算出这些路径,而这一部分我们会用到动态规划。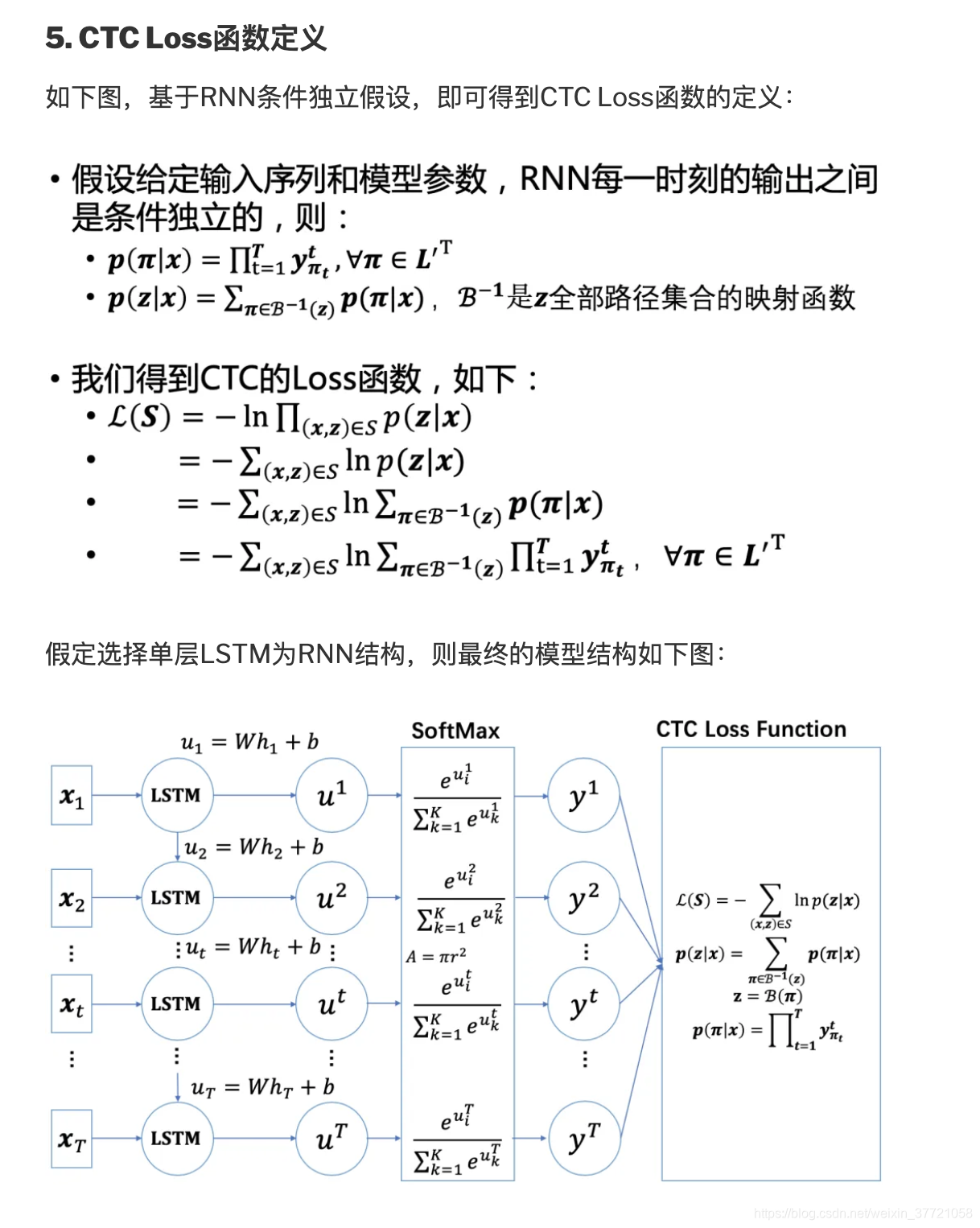
首先我们是求一条路径的概率,但是这里是多对一的问题,所以我们需要把这些路径求和,这就是一个输入样本的损失函数,再进一步,如果是一个batch一个batch来训练的话,那么就需要多多个样本的损失求和。其实本质上还是最大似然的思想。和交叉熵等损失函数的推导没有太大的区别。
知识相互贯通,从本质出发才能更好的定义损失函数,本质上都是最大似然函数思想的交叉熵损失函数还是基于CTC损失函数真的是殊途同归啊!区别可能就是第一步那里需要用动态规划的思想,提高计算的效率。
---- 高效的计算是CTC区别其他损失函数的关键
训练的时候我们输入的标签,如何通过标签找到全部的组合,就是我们接下来讨论的了。首先我们现在输入的标签每个字母之间插入一个空白‘-’,所以我们组合的路径一定大于标签的路径的。通过下面的规则找到的路径就能转化为目标路径了。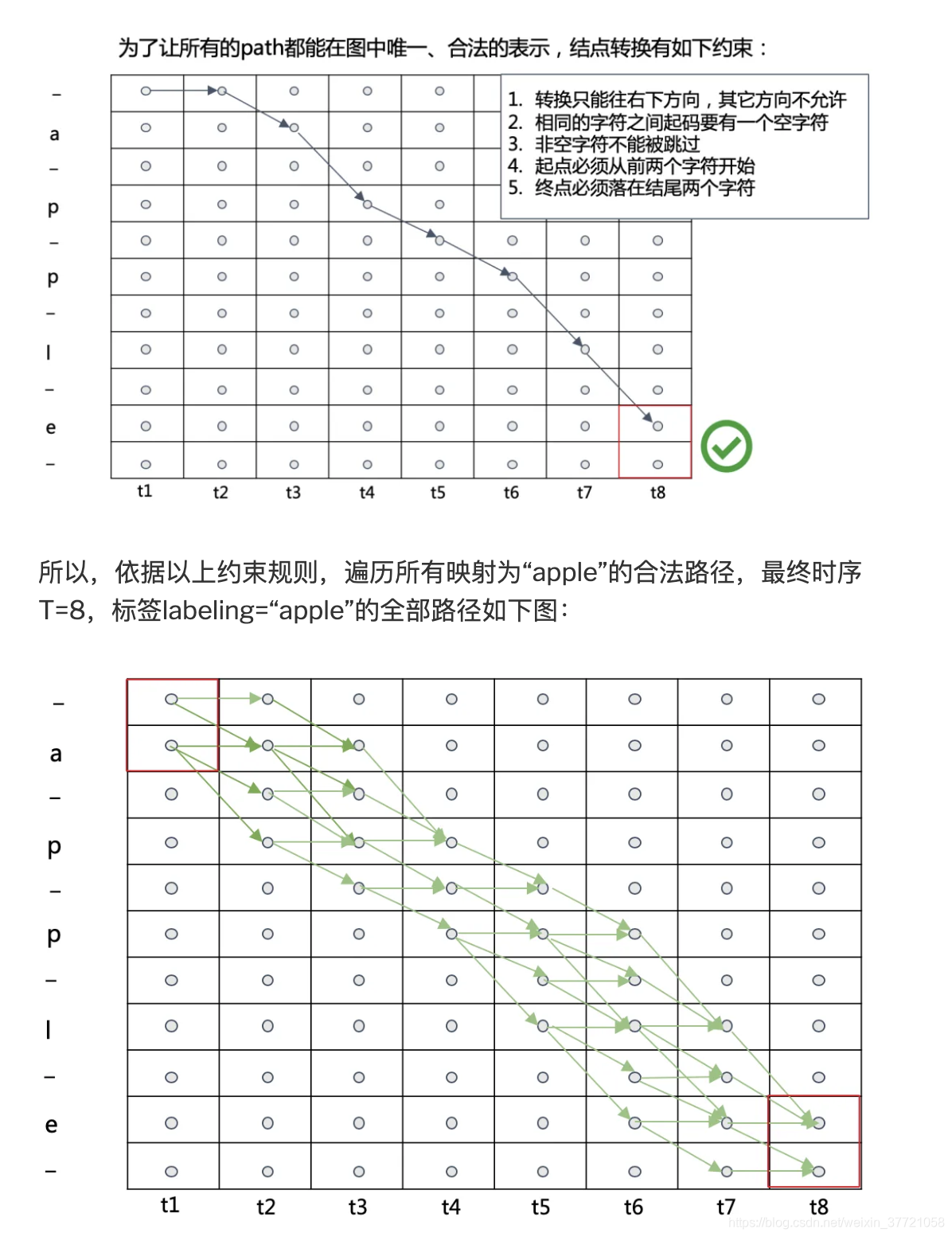


最终前向传播的递归总结为如下:第一个时刻是某两个,第二个时刻是第一个时刻的某两个乘以该时刻的,然后不断的推进这就是动态规划。不熟悉动态规划的话,可以去刷刷leetcode。下面就是动态规划的前向的伪代码: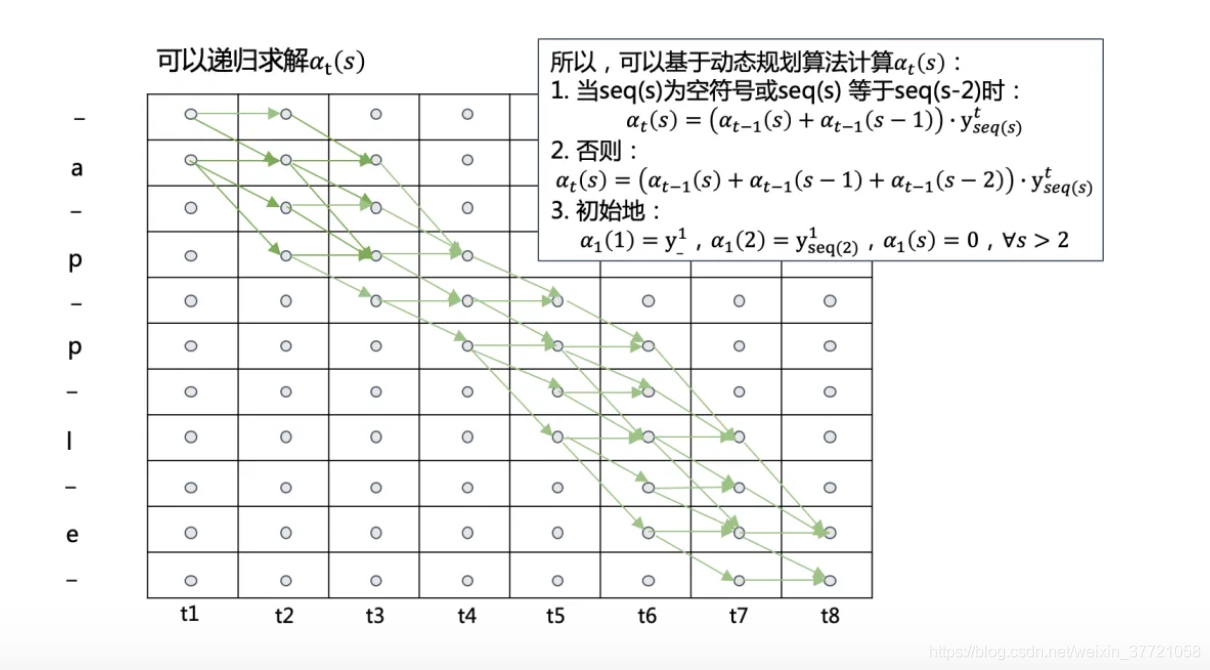
为了更快的速度,我们可以前后同时进行动态规划。下面是后面开始进行动态规划:
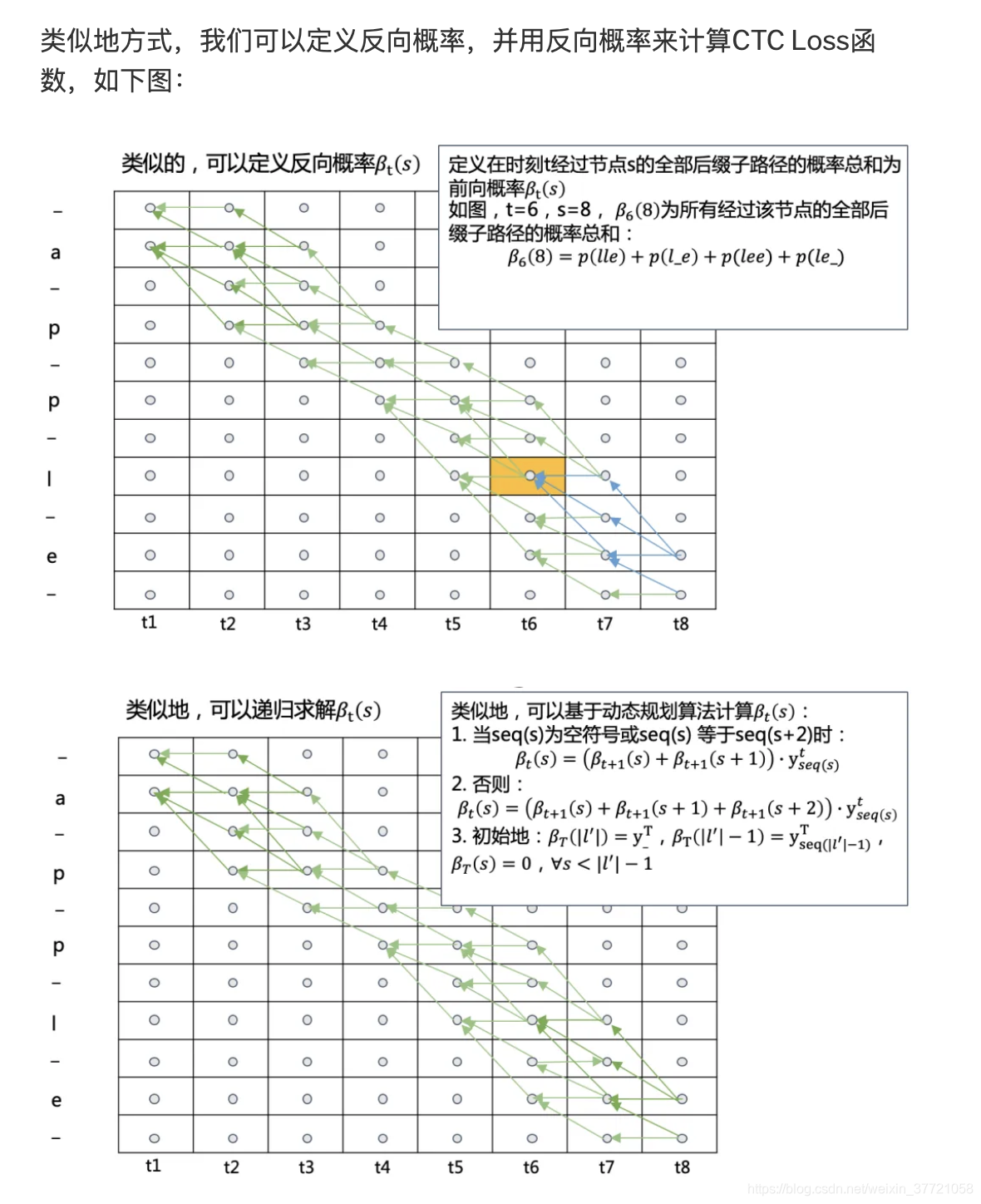
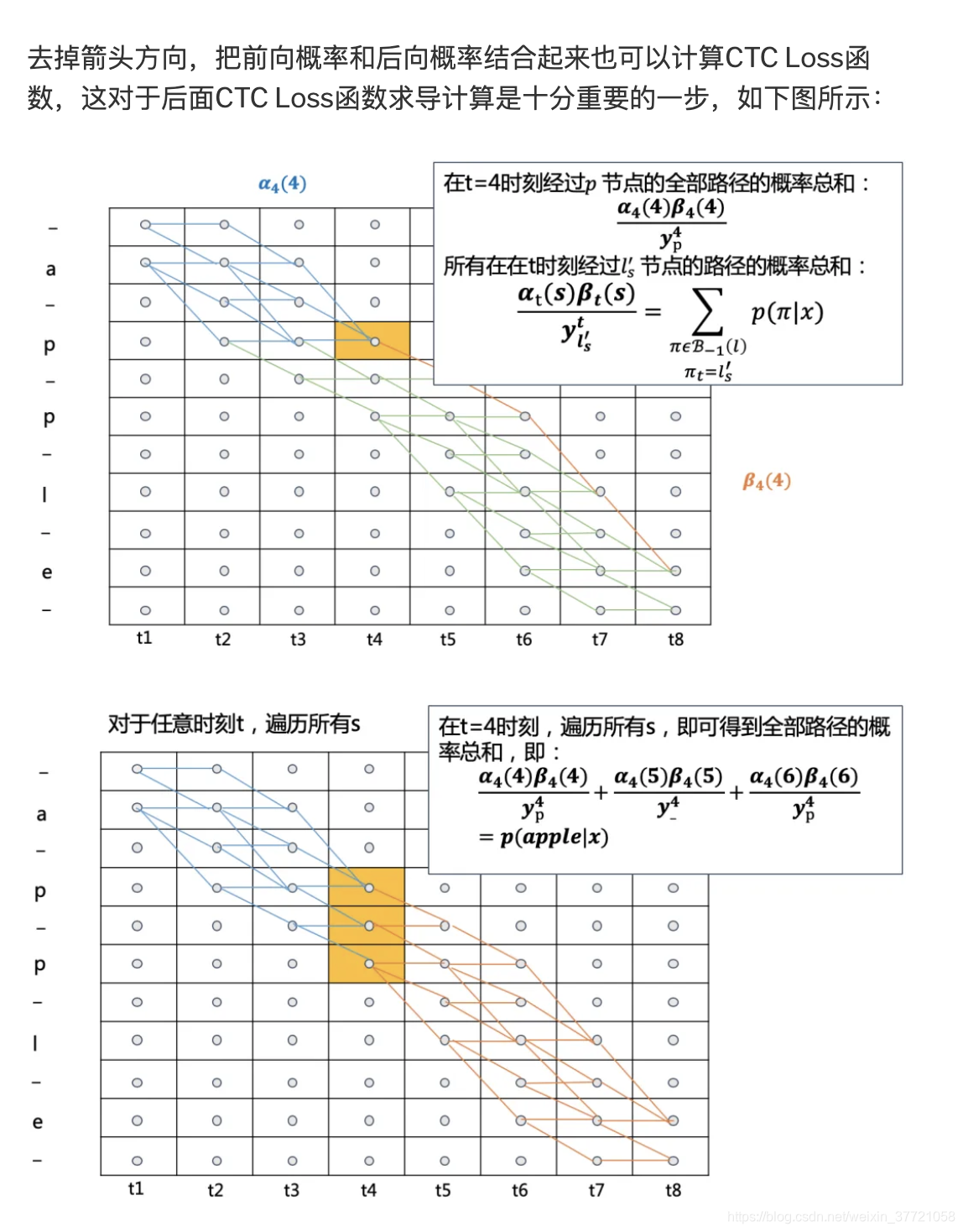
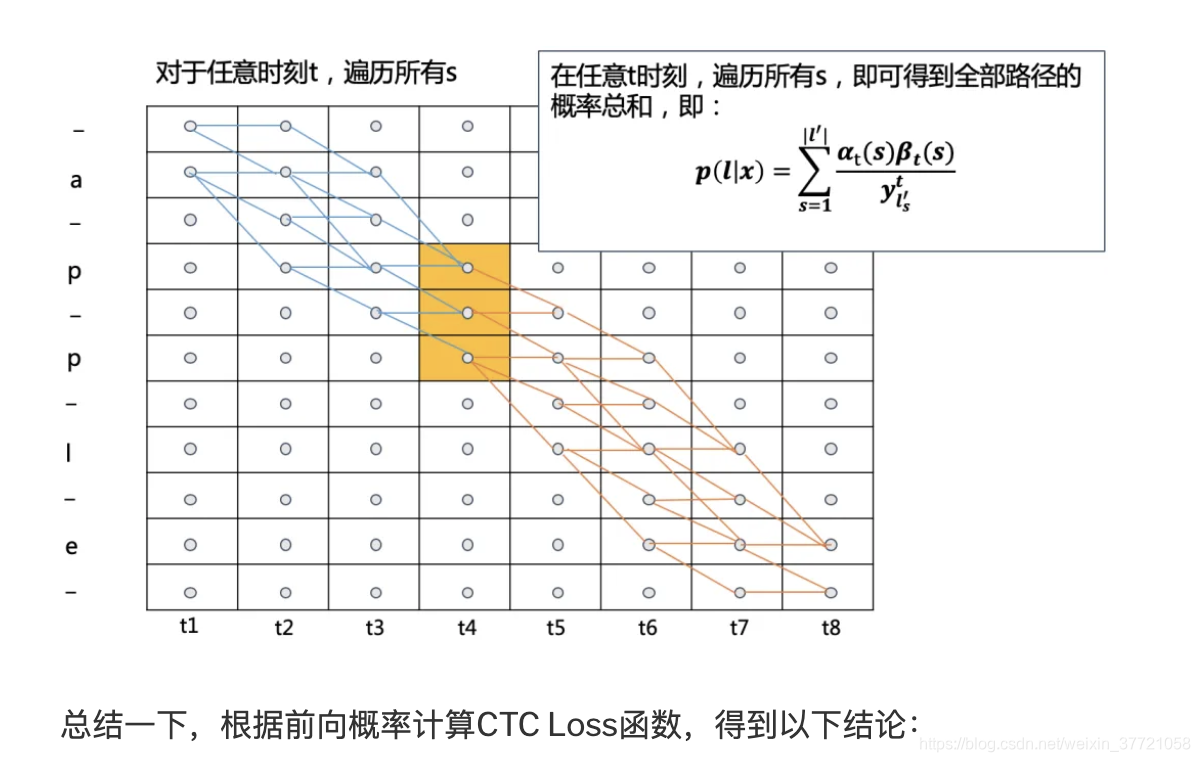
这就是动态规划下的CTC的路径的概率计算:


求出损失函数基本上就可以进行梯度下降和反向传播了。
https://www.cnblogs.com/skyfsm/p/10335717.html
https://blog.csdn.net/monk1992/article/details/89210430
https://xiaodu.io/ctc-explained/
CTC总结:
1.有效处理切割不现实问题
2.引入空白
3.转化为概率最大,其中o是所有映射到z的输出序列。因此,只需要穷举出所有的o,累加一起即可得到?(?│?),从而使得RNN模型对最终的label进行建模
4.HMM前后算法加快了计算
5.损失函数在对指定位置上的softmax值进行反向传播。反向梯度。