1、scrapy的工作流程
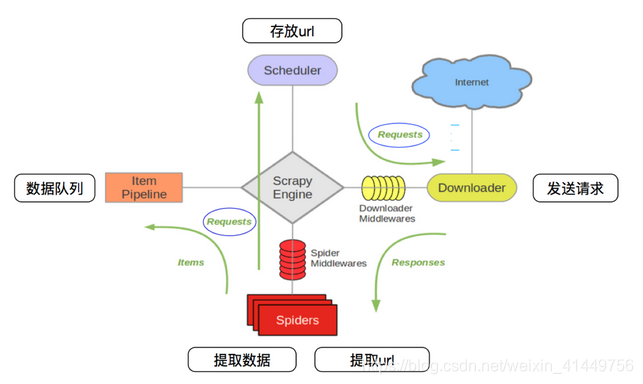
其流程可以描述如下:
- 调度器把requests-->引擎-->下载中间件--->下载器
- 下载器发送请求,获取响应---->下载中间件---->引擎--->爬虫中间件--->爬虫
- 爬虫提取url地址,组装成request对象---->爬虫中间件--->引擎--->调度器
- 爬虫提取数据--->引擎--->管道
- 管道进行数据的处理和保存
注意:
- 图中绿色线条的表示数据的传递
- 注意图中中间件的位置,决定了其作用
- 注意其中引擎的位置,所有的模块之前相互独立,只和引擎进行交互
2、scrapy中每个模块的具体作用

3、创建scrapy项目
创建scrapy项目的命令:scrapy startproject +<项目名字>
示例:scrapy startproject myspider
生成的目录和文件结果如下:

4、创建爬虫
命令:在项目路径下执行:scrapy genspider +<爬虫名字> + <允许爬取的域名>
示例:
cd myspider
scrapy genspider itcast itcast.cn
生成的目录和文件结果如下:

5、总结
- Scrapy的安装:pip install scrapy
- 创建scrapy的项目: scrapy startproject myspider
- 创建scrapy爬虫:在项目目录下执行 scrapy genspider hr tencent.com
- 运行scrapy爬虫:在项目目录下执行 scrapy crawl hr
# 输出JSON格式,默认为Unicode编码 scrapy crawl hr -o teachers.json # 输出JSON Lines格式,默认为Unicode编码 scrapy crawl hr -o teachers.jsonlines # 输出CSV格式,使用逗号表达式,可用Excel打开 scrapy crawl hr -o teachers.csv # 输出XML格式 scrapy crawl hr -o teachers.xml - 解析并获取scrapy爬虫中的数据:
- response.xpath() 方法的返回结果是一个类似list的类型,其中包含的是selector对象,操作和列表一样,但是有一些额外的方法
- extract() 返回一个包含有字符串的列表
- extract_first() 返回列表中的第一个字符串,列表为空没有返回None
scrapy管道的基本使用:
- 完善pipelines.py中的 process_item 函数
- 在settings.py中设置开启pipeline
ITEM_PIPELINES = { 'myspider.pipelines.ItcastPipeline': 400 }
版权声明:本文为weixin_41449756原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。