1,我们先看一下最简单的代码,消费kafka的数据然后state存储,通过checkpoint保存到hdfs
package application;
import appOperator.stateMap;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.contrib.streaming.state.RocksDBStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.util.Properties;
public class CheckPointState_demo {
private static Logger logger = LoggerFactory.getLogger(CheckPointState_demo.class);
public static void main(String[] args) {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度
env.setParallelism(4);
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
//设置checkpoint 1分钟
env.enableCheckpointing(60000);
// 设置模式为exactly-once (这是默认值)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//重启策略
env.setRestartStrategy(RestartStrategies.noRestart());
// 确保检查点之间有至少500 ms的间隔【checkpoint最小间隔】
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// 检查点必须在一分钟内完成,或者被丢弃【checkpoint的超时时间】
env.getCheckpointConfig().setCheckpointTimeout(10000);
// 同一时间只允许进行一个检查点
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//设置statebackend
try {
env.setStateBackend(new RocksDBStateBackend("hdfs://node1.hadoop:9000/flink/checkpoint", true));
} catch (IOException e) {
e.printStackTrace();
}
// 表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint【详细解释见备注】
//ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint
//ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION: 表示一旦Flink处理程序被cancel后,会删除Checkpoint数据,只有job执行失败的时候才会保存checkpoint
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//todo 获取kafka的配置属性
args = new String[]{"--input-topic", "topn_test", "--bootstrap.servers", "node2.hadoop:9092,node3.hadoop:9092",
"--zookeeper.connect", "node1.hadoop:2181,node2.hadoop:2181,node3.hadoop:2181", "--group.id", "c1"};
ParameterTool parameterTool = ParameterTool.fromArgs(args);
Properties sendPros = parameterTool.getProperties();
Properties pros = parameterTool.getProperties();
//todo 指定输入数据为kafka topic
DataStream<String> kafkaDstream = env.addSource(new FlinkKafkaConsumer010<String>(
pros.getProperty("input-topic"),
new SimpleStringSchema(),
pros).setStartFromGroupOffsets()
);
// kafkaDstream.print();
DataStream<String> mapDstream = kafkaDstream.keyBy(x->x).map(new stateMap());
mapDstream.print();
try {
env.execute("startExecute");
} catch (Exception e) {
e.printStackTrace();
}
}
}
2,我们先启动一个任务:
./bin/flink run -d -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 -ynm stateful-computation -c application.CheckPointState_demo /zywa/tmp_test/flink-1.7.2/flink3.jar
3,这个时候我们查看hdfs在干啥
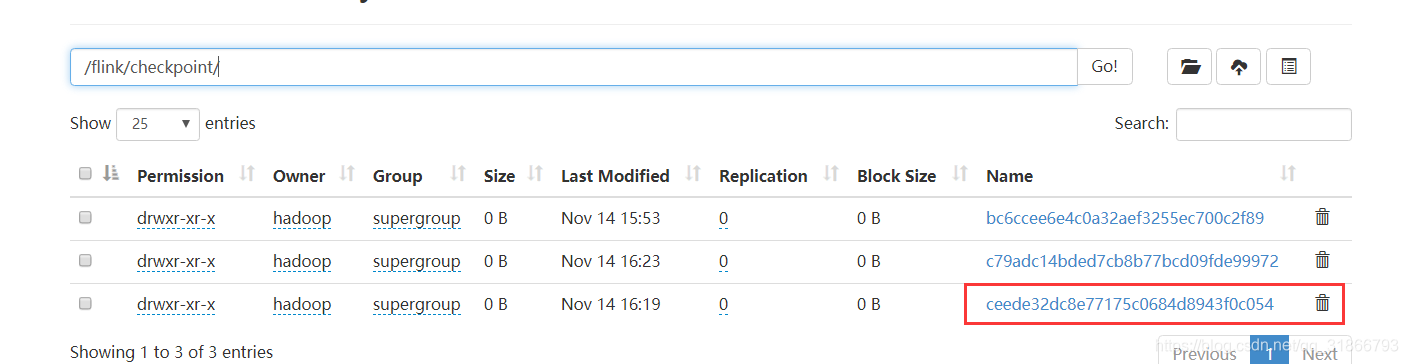
点进去看看,如下图,就是每次生成一个快照文件 :

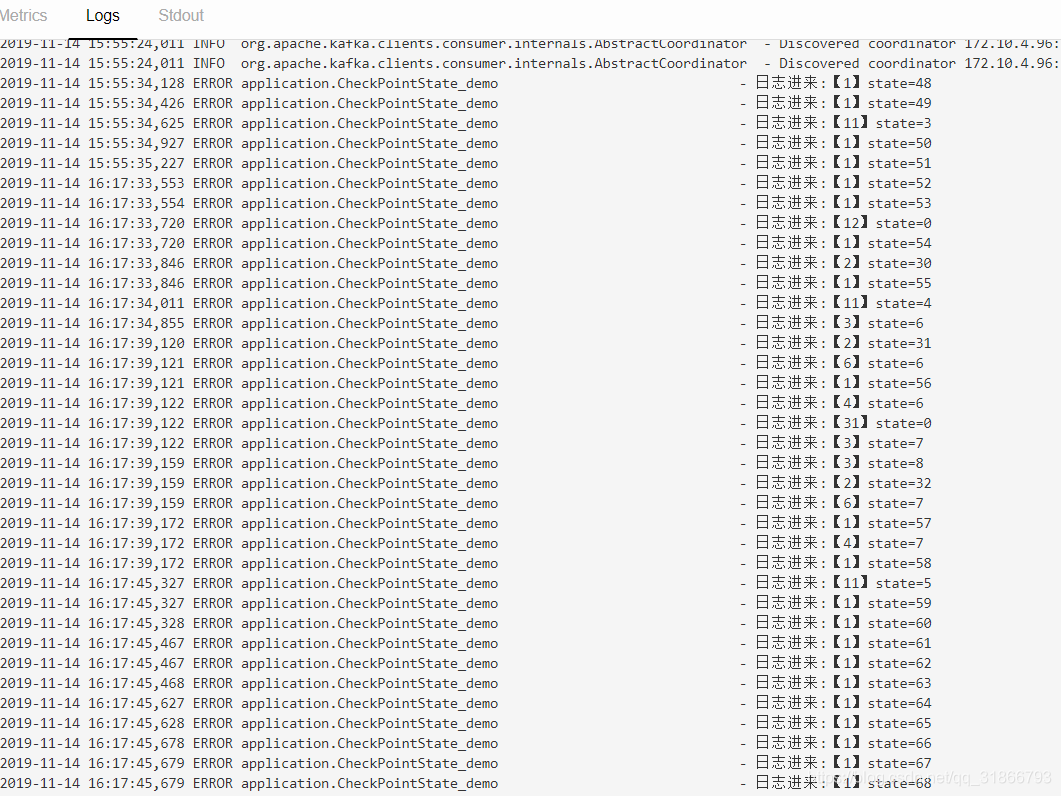
4,往kafka打输入数据,我们在web端可以看到打印日志:
4,杀死任务
yarn application -kill application_1573032804579_0691
5,这个时候我们重启任务,不过我们需要指定我们要恢复到什么快照,启动命令:
./bin/flink run -d -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 -ynm state_test33 -s hdfs://node1.hadoop:9000//flink/checkpoint/bc6ccee6e4c0a32aef3255ec700c2f89/chk-9/_metadata -c application.CheckPointState_demo /zywa/tmp_test/flink-1.7.2/flink3.jar
6, 我们再往kafka输入数据发现web端打印的东西是从上次state的结果开始的
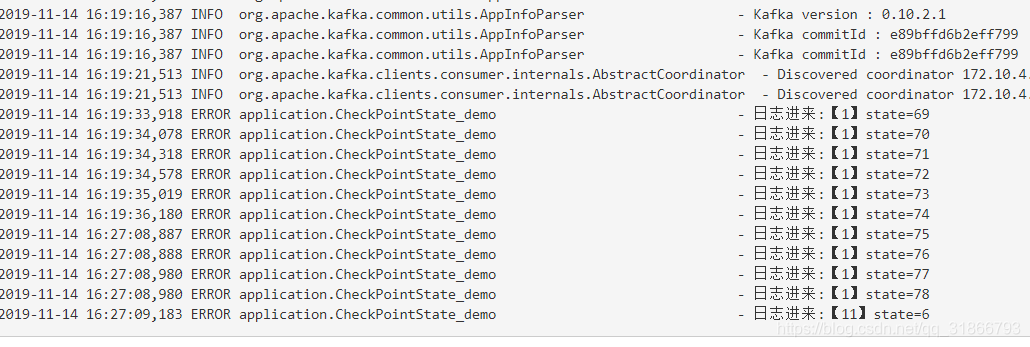
7,多试几次,你会发现就是这么简单
版权声明:本文为qq_31866793原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。