实验|Vachel 算力支持|幻方AIHPC

长时间序列预测(Long-Term Series Forecasting,以下称为 LTSF)在现实世界中有非常广阔的应用场景,例如电力资源预估、疾病传播与扩散、经济发展预测等实际问题。前不久分享的《Informer 上手实践》介绍了获得AAAI 2021最佳论文奖的Informer模型,以及其在幻方萤火二号上的试跑和优化。该工作改造 Transformer 模型来解决 LTSF 领域下的问题,取得优异的效果,带动起了该方向的研究热情。NeurIPS 2021,来自清华的几位学者结合之前和工作和 Informer 的模型设计,提出了 Autoformer 模型,在相同预测任务上大幅超越了之前的模型,实现了38%的相对效果提升。
幻方AI最近对这项工作进行了整理和优化,在幻方萤火二号上复现了 Autoformer 的实验。通过幻方自研的 3FS、hfreduce、算子等,对模型训练进行提速,整合代码简化接口,融入hfai数据仓库和模型仓库中,帮助研究者和开发者们降低使用门槛。本期文章将为大家详细描述。
模型介绍
我们知道,Transformer 是通过自注意力机制(self-attention)来捕捉时刻间的依赖,在 NLP 领域上取得了显著效果。但是在长期序列预测中,仍存在不足:
长序列中的复杂时间模式使得注意力机制难以发现可靠的时序依赖;
基于 Transformer 的模型不得不使用稀疏形式的注意力机制来应对二次复杂度的问题,但造成了信息利用的瓶颈。
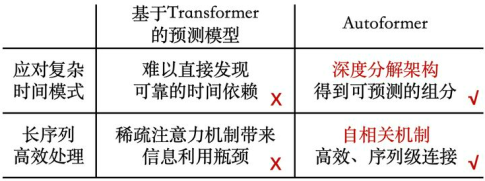
为突破上述问题,Autoformer 主要做了以下创新:
突破将序列分解作为预处理的传统方法,提出深度分解架构(Decomposition Architecture),能够从复杂时间模式中分解出可预测性更强的组分;
基于随机过程理论,提出自相关机制(Auto-Correlation),代替点向连接的注意力机制,实现序列级连接和较低复杂度,打破信息利用瓶颈。
相比与 Informer,他们都提出了要改变注意力机制,提升序列级连接和降低运算复杂度。不同的是,Autoformer 进一步提出,将时序进行分解,从复杂模式中抽取出可预测性更强的成分。具体是如何做的呢?下面的章节会为大家简单介绍。
1►深度分解架构
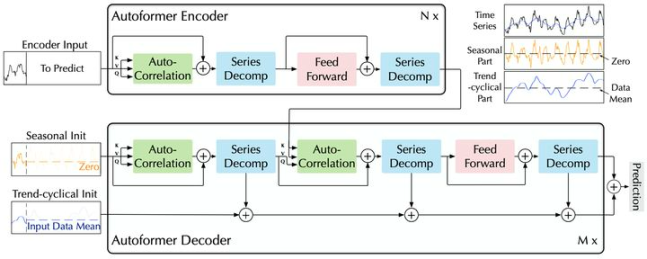
时间序列分解是指将时间序列分解为几个组分,每个组分表示一类潜在的时间模式,如周期项(seasonal),趋势项(trend-cyclical)。由于预测问题中未来的不可知性,通常先对过去序列进行分解,再分别预测。但这会造成预测结果受限于分解效果,并且忽视了未来各个组分之间的相互作用。
Autoformer 是将序列分解作为一个内部单元,嵌入到编码-解码器中。在预测过程中,模型交替进行预测结果优化和序列分解,即从隐变量中逐步分离趋势项与周期项,实现渐进式分解。在编码器中,基于滑动平均思想逐步分解出各成分,在解码器中,对各个部分分别建模。基于这种渐进式分解架构,模型可以在预测过程中逐步分解隐变量,并通过自相关机制、累积的方式分别得到周期、趋势组分的预测结果,实现分解、预测结果优化的交替进行、相互促进。
2►自相关机制
Autoformer 的自相关机制用来实现高效的序列级连接,从而扩展信息效用。一般不同周期的相似相位之间通常表现出相似的子过程,Autoformer 利用这种序列固有的周期性来设计自相关机制,其中,包含基于周期的依赖发现(Period-based dependencies)和时延信息聚合(Time delay aggregation)。
基于周期的依赖发现采用的是随机过程理论,计算相关性作为未归一化的周期估计的置信度。而时延信息聚合是将相似的子序列信息根据计算出的周期长度进行聚合,以实现序列级的连接。

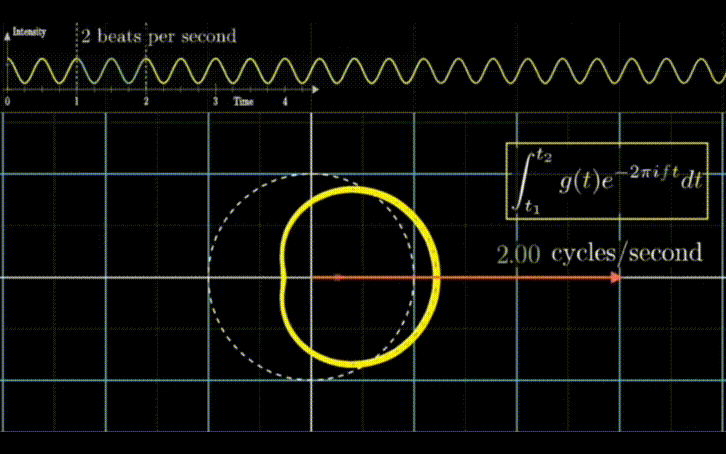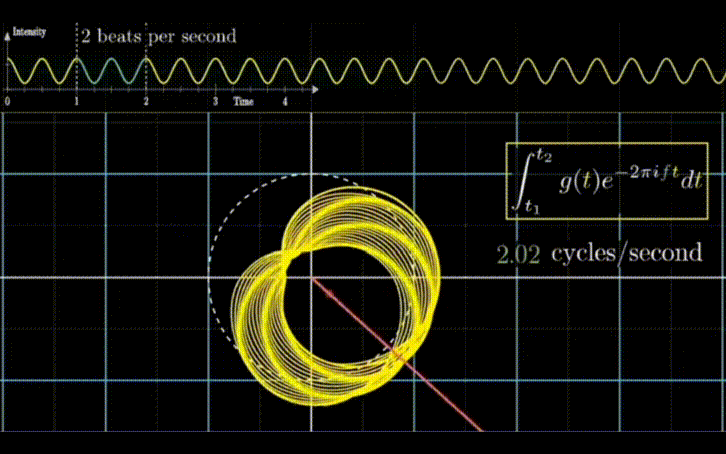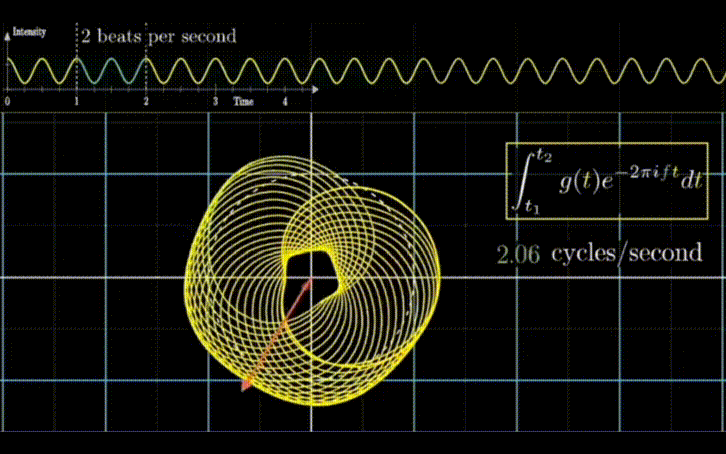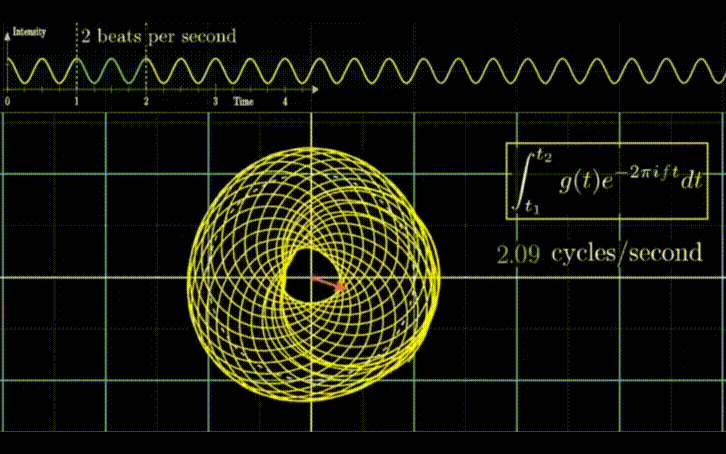
Autoformer 的作者们在文中给出了使用该方法后的效果。如上图所示,相比于之前的注意力机制或者稀疏注意力机制,自注意力机制(Auto-Correlation)实现了序列级的高效连接,从而可以更好的进行信息聚合,打破了信息利用瓶颈。
模型实践
Autoformer 的作者对模型进行了完整的开源,幻方AI的研究者们对其进行了试跑复现和优化。
1►数据集
Informer 和 Autoformer 基于相同的数据集进行试验,包括电力,经济,交通,医疗等若干个长时序数据集。历史分析长度,预测长度,预测范围作为参数可以动态调整。这里,幻方AI将这些能通用的数据集进行整合,将原始数据转化成 ffrecord 格式,用户调用简单的接口便可以加载高性能的 dataloader 进行模型训练。具体的,如下例所示:
from hfai.datasets import LTSF
dataset = LTSF(data_name='ETTh1', split='train', seq_len=96, label_len=48, pred_len=24, features='S', target='OT', timeenc=0, freq='h')
loader = dataset.loader(batch_size=64, num_workers=4)
for x, y, x_mark, y_mark in loader:
# training model ...如上例代码,我们加载 hfai 数据仓库中的 ETTh1.csv 数据,hfai 数据仓库会自动切分好数据集,进行特征工程,并返回高性能的 dataloader。
2►模型训练
幻方AI对作者开源的模型源码进行了优化,以 hfreduce 代替 NCCL,以自研的高性能算子替代模型中的 LayerNorm,Attention 等算子,实现 Autoformer 在幻方萤火二号上的高性能并行训练。用户可以直接在 hfai 模型仓库中直接调用到我们优化后的模型:
from hfai.models import Autoformer
import hfreduce.torch as hfr
model = Autoformer(enc_in=1, dec_in=1, c_out=1, seq_len=96, label_len=48, out_len=24, e_layers=2, d_layers=1, dropout=0.05, embed='timeF').cuda()
loss = Loss(model)
optimizer = Optimizer(model)
reducer = hfr.AsyncReduceFloat(registry_host, port, proc_rank, procs_per_node, node_rank, node_cnt, model)
# each epoch
for x, y, x_mark, y_mark in loader:
reducer.zero_grad()
model(x, y, x_mark, y_mark)
loss.backward()
reducer.synchronize()由于开源数据不算很大,我们试跑时只申请一个节点并行训练。通过优化后训练效果很高,很快便可以完成试验:
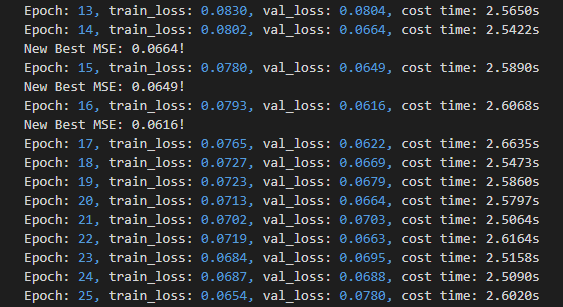
可以看到,每 Epoch 耗时仅 2s 左右,相比单卡性能提升了8倍以上。GPU利用率在95%左右,充分利用其了显卡的计算性能。模型在第16轮基本达到了收敛状态。
体验总结
Autoformer 进行了完整的开源,代码结构清晰,比较容易与幻方的训练优化工具结合,获得效果和性能的双提升。同时,该模型承接 Informer,继续推动了“transformer+时序预测”这个方向的研究走向深入,助力更多真实场景的提效与进步。
综合体验打分如下:
01:研究新颖度 ★★
该模型着眼于长时间序列的预测问题,是一个广泛研究的基础课题。
02:开源指数 ★★★★★
数据和代码都已开源,代码逻辑清晰可读性高。
03:算力门槛 ★★★
数据量小,模型计算、内存和体系结构均已优化,普通高性能PC即可运行。
04:通用指数 ★★★★
模型是对 Transformer 的优化,将时序分解融入,在很多场景下验证了其效果。
05:模型适配度 ★★★★★
依赖简单,很容易与幻方AI的训练优化工具结合,提效明显。
附录
论文标题:
Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting
原文地址:
https://arxiv.org/abs/2106.13008
源码地址:
https://github.com/thuml/Autoformer
点击下方链接,幻方AI技术BLOG,更多干货奉上