1.概述
级联分类器这个坑早该挖的了,由于本人之前使用的是win10系统家庭版的某种关系,并没有成功训练出xml,趁着换了Linux和比赛需要就再次挖挖坑,这里用到的是Opencv自带的两个分类器来训练样本,这里仅讲述linux环境下分类器的使用方法。
Linux版本两个应用程序位于/usr/local/bin文件夹中,分别为opencv_createsamples和opencv_traincascade,前者运用于正样本的训练,后者则是负样本的训练。
第一步:创建一个名为train的新文件夹。
第二步:在新建的文件夹train里面再新建两个文件夹,pos文件放正样本,neg文件放负样本。
第三步:将上述的opencv自带的两个分类器复制过来train里面。
2.样本准备
正样本:

我这里随手拿了一个农夫山泉的水瓶盖子作为检测的对象,所以拍了15张这个盖子的照片作为正样本,正样本一定要统一归一化为相同的尺寸,这里使用的尺寸是50*50,并且尽量在裁剪修改正样本的时候突出正样本的特征,即背景颜色要统一,背景简洁等。
负样本:
负样本图像尽量要选取不同尺寸,不同背景的,但是里面不包含检测对象的图像,这些照片都可以在一些样本库下载,我这里训练的负样本数目是60。
注意:正负样本比例网上普遍认为1:3为佳,各位可以验证一下。
3.生成文本描述文件
在train文件里面打开终端创建pos.dat和neg.txt文本描述文件。
输入命令:
ls ./pos/*.*>pos.dat
ls ./neg/*.*>neg.txt注意:生成结束后,打开生成的文件检查里面是否含有除了样本名称外的东西,有的话就删除,只留下需要的样本名称。
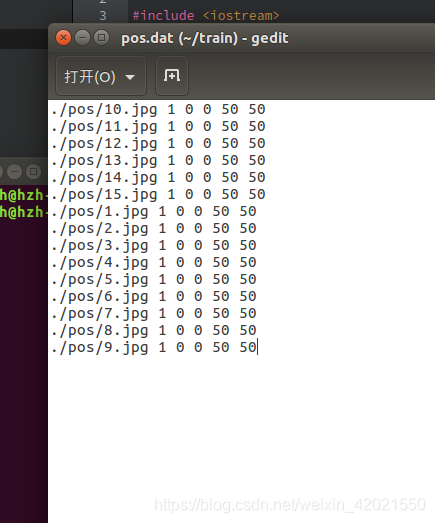
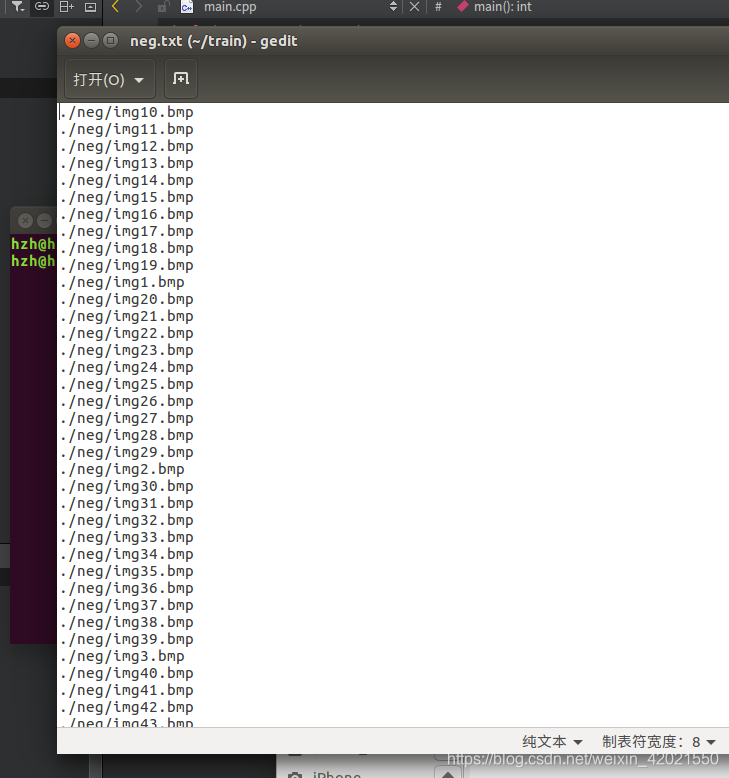
这里还需要将正样本的描述文件作修改,1指这个样本里面的目标数目,后面的数字0 0 50 50对应(x,y,width,height)。
检验完毕之后,我们还需要生成一个pos.vec,继续在终端输入命令行。
opencv_createsamples -vec pos.vec -info pos.dat -bg neg.txt -w 50 -h 504.训练
第一步:在train文件中创建一个data文件,data文件是用来装训练之后输出的xml文本的。
第二步:在train文件中打开终端,输入一下命令即将开始训练。
opencv_traincascade -data data -vec pos.vec -bg neg.txt -numPos 15 -numNeg 60 -numStages 15 -w 50 -h 50 -minHitRate 0.9999 -maxFalseAlarmRate 0.5 -mode ALL最后等待训练成功之后就会出现
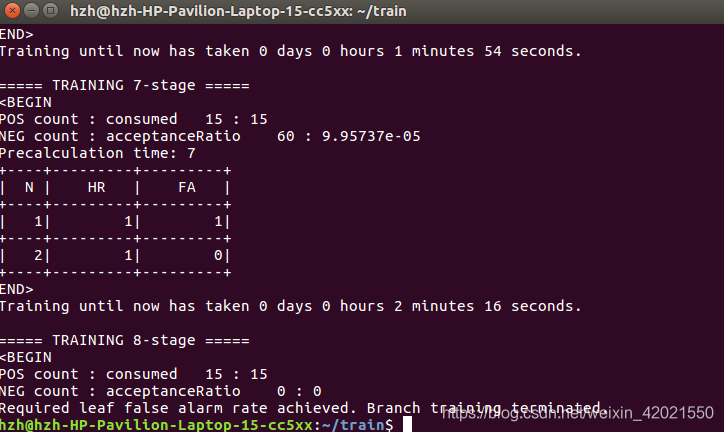
我原本设定了训练层数为15级,可是因为样本数目实在太少了,最终只能训练到8级就停止了。
这里贴出简单的几行调试代码
#include <opencv2/opencv.hpp>
#include <iostream>
using namespace cv;
using namespace std;
String face_cascade_name = "/home/hzh/train/data/cascade.xml";
String window_name = "Capture - Face detection";
CascadeClassifier customFaceDetector;
Mat src;
Mat gray_src;
int main() {
VideoCapture capture(1);
if (!customFaceDetector.load(face_cascade_name))
{
cout<<"could not load face data...\n"<<endl;
return 0;
}
if (!capture.isOpened())
{
cout << "视频不能正常打开" << endl;
return 0;
}
while(true)
{
vector<Rect> faces;
capture>>src;
namedWindow("src",WINDOW_AUTOSIZE);
imshow("src",src);
cvtColor(src, gray_src, COLOR_BGR2GRAY);
equalizeHist(gray_src, gray_src);
customFaceDetector.detectMultiScale(gray_src, faces, 1.1, 2, 0, Size(50, 50));
for (size_t t = 0; t < faces.size(); t++)
{
rectangle(src, faces[t], Scalar(0, 255, 0), 3);
}
namedWindow(window_name, CV_WINDOW_AUTOSIZE);
imshow(window_name, src);
char c=waitKey(1);
if(c==27)
{
break;
}
}
return 0;
}


在不稳定或者复杂的背景状况下,如此少的样本数目肯定是不足够的,大家可以增加样本的数目来进行训练,也可以稍微修改以下训练参数来提高精度。如果觉得速度要提高可以将样本改为灰度图,也可以在所生成的描述文件中将小数修改为整数,具体可以网上搜下方法。

以下我贴出关于上面一些命令解释方便读者了解学习。
-data<cascade_dir_name>
训练的分类器存储文件夹
-vec<vec_file_name>
包含正样本的vec文件(由opencv_cratesamples创建)
-bg<background_file_name>
背景描述文件
-numPos<number_of_positive_samples>
-numNeg<number_of_negative_samples>
用于每个分类器训练层级的正负样本数量
-numStages<number_of_stages>
用于训练分类器的级(stage)数
-precalcValBufSize<precalculated_vals_buffer_size_in_Mb>
缓存大小,用于存储预先计算的特征点值(单位为:Mb)
-precalcIdxBufSize<precalculated_idxs_buffer_size_in_Mb>
缓存大小,用于存储预先计算的特征索引,单位为Mb,分配空间越大,训练就越快
-baseFormatSave
这个参数在使用Haar特征时有效,如果指定这个参数,级联分类器将以老的格式存储训练数据。
-acceptanceRatioBreakValue
这个参数是用来指定你的训练学习的精度和什么时候结束。一个好的指导方针是精度最好不好大于10e-5,以防止会重复训练已经训练过的数据。默认值是-1来忽视这个特征。
-stageType<BOOST(default)>
级别类型,目前只支持BOOST类型
-featureType<{HAAR(default),LBP}>
特征类型:HAAR-类HAAR特征;LBP-局部纹理模式特征
-w<sampleWidth>
-h<sampleHeight>
正样本的尺寸(单位:像素).必须跟训练样本创建时的尺寸一致
-bt<{DAB,RAB,LB,GAB(default)}>
boosted分类器的类型:DAB-Discrete AdaBoost,RAB-Real AdaBoost,LB-LogitBoost,GAB-Gentle AdaBoost
-minHitRate<min_hit_rate>
分类器的每一级希望得到最小检测率(即正样本被判断有效的比例),总的检测率大约为min_hit_rate^number_of_stages
-maxFalseAlarmRate<max_false_alarm_rate>
分类器的每一级希望的最大误检率(负样本判定为正样本的概率)总的误判率为max_false_alarm_rate^number_of_stages
-weightTrimRate<weight_trim_rate>
指定是否使用图像裁剪并指定其裁剪权重,典型值是0.95
-maxDepth<max_depth_of_weak_tree>
弱分类器数的最大深度,典型值是1,代表二叉树
-maxWeakCount<max_weak_tree_count>
每一级中弱分类器的最大数目,强分类器中包含很多弱的树(<maxWeakCount)来实现设定的最大误检率。参考:https://blog.csdn.net/beizhengren/article/details/78211799