? JS正则表达式完整教程
? 正则可视化工具
正则表达式字符匹配攻略
正则表达式是匹配模式,要么匹配字符,要么匹配位置。
1. 横向模糊匹配和纵向模糊匹配
? 横向模糊 指的是,一个正则可匹配的字符串的长度不是固定的,可以是多种情况的。
其实现的方式是 使用量词。譬如 {m,n},表示连续出现最少 m 次,最多 n 次。
比如 /ab{2,5}c/ 表示匹配这样一个字符串:第一个字符是“a”,接下来是2到5个字符“b”,最后是字符“c”。测试如下:
var regex = /ab{2,5}c/g;
var string = "abc abbc abbbc abbbbc abbbbbc abbbbbbc";
console.log( string.match(regex) ); // => ["abbc", "abbbc", "abbbbc", "abbbbbc"]
注意:案例中用的正则是 /ab{2,5}c/g,后面多了 g (单词 global 的首字母),它是正则的一个修饰符。表示 全局匹配,即在目标字符串中按顺序找到满足匹配模式的 所有 子串,强调的是“所有”,而不只是“第一个”。
? 纵向模糊 指的是,一个正则匹配的字符串,具体到某一位字符时,它可以不是某个确定的字符,可以有多种可能。
其实现的方式是使用 字符组。譬如 [abc],表示该字符是可以字符“a”、“b”、“c”中的任何一个。
比如 /a[123]b/ 可以匹配如下三种字符串:“a1b”、“a2b”、“a3b”。测试如下:
var regex = /a[123]b/g;
var string = "a0b a1b a2b a3b a4b";
console.log( string.match(regex) ); // => ["a1b", "a2b", "a3b"]
2. 字符组
虽叫字符组(字符类),但 只是其中一个字符。
例如 [abc],表示匹配一个字符,它可以是 “a”、“b”、“c” 之一。
? 范围表示法
比如 [123456abcdefGHIJKLM],可以写成 [1-6a-fG-M]。用连字符 - 来省略和简写。
因为连字符有特殊用途,那么要匹配 “a”、“-”、“z” 这三者中任意一个字符。可以写成:
[-az]或[az-]或[a\-z]。即要么放在开头,要么放在结尾,要么转义。总之不会让引擎认为是范围表示法就行了。
? 排除字符组
纵向模糊匹配,还有一种情形就是,某位字符可以是任何东西,但就不能是 “a”、“b”、“c”。
此时就是排除字符组(反义字符组)的概念。例如 [^abc],表示是一个除 “a”、“b”、“c” 之外的任意一个字符。字符组的第一位放 ^(脱字符),表示求反的概念。
? 常见的简写形式
| 正则 | 含义 | 解释 |
|---|---|---|
\d | [0-9] | 表示是一位数字 (d – digit) |
\D | [^0-9] | 表示除数字外的任意字符 |
\w | [0-9a-zA-Z_] | 表示数字、大小写字母和下划线 (w – word) |
\W | [^0-9a-zA-Z_] | 表示非单词字符 |
\s | [\t\v\n\r\f] | 表示空白符,包括空格、水平制表符、垂直制表符、换行符、回车符、换页符 (s – space character) |
\S | [^\t\v\n\r\f] | 表示非空白符 |
. | [^\n\r\u2028\u2029] | 通配符,表示几乎任意字符。换行符、回车符、行分隔符和段分隔符除外 |
如果要 匹配任意字符 可以使用 [\d\D]、[\w\W]、[\s\S] 和 [^] 中任何的一个。
3. 量词
量词也称重复。
? 简写形式
| 正则 | 含义 |
|---|---|
{m,} | 表示至少出现 m 次 |
{m} | 等价于 {m,m},表示出现 m 次 |
? | 等价于 {0,1},表示出现或者不出现 |
+ | 等价于 {1,} ,表示出现至少一次 |
* | 等价于 {0,},表示出现任意次,有可能不出现 |
4. 多选分支
一个模式可以实现横向和纵向模糊匹配。而多选分支可以支持多个子模式任选其一。
具体形式如下:(p1|p2|p3),其中 p1、p2 和 p3 是子模式,用 |(管道符)分隔,表示其中任何之一。
例如要匹配 “good” 和 “nice” 可以使用 /good|nice/。测试如下:
var regex = /good|nice/g;
var string = "good idea, nice try.";
console.log( string.match(regex) ); // => ["good", "nice"]
但,⚠️注意,比如我用 /good|goodbye/,去匹配 “goodbye” 字符串时,结果是 “good”:
var regex = /good|goodbye/g;
var string = "goodbye";
console.log( string.match(regex) ); // => ["good"]
而把正则改成 /goodbye|good/,结果是:
var regex = /goodbye|good/g;
var string = "goodbye";
console.log( string.match(regex) ); // => ["goodbye"]
也就是说,分支结构也是惰性的,即 当前面的匹配上了,后面的就不再尝试了。
正则表达式位置匹配攻略
1. 什么是位置呢 ?
位置 是 相邻字符之间的位置。比如,下图中箭头所指的地方:
2. 如何匹配位置呢 ?
在 ES5 中,共有6个锚字符:^ $ \b \B (?=p) (?!p)
? ^ 和 $
^(脱字符)匹配开头,在多行匹配中匹配行开头。$(美元符号)匹配结尾,在多行匹配中匹配行结尾。
比如我们把字符串的开头和结尾用 “#” 替换:
var result = "hello".replace(/^|$/g, '#');
console.log(result); // => "#hello#"
? \b和\B
\b是单词边界,具体就是\w和\W之间的位置,也包括\w和^之间的位置,也包括\w和$之间的位置。
比如一个文件名是 “[JS] Lesson_01.mp4” 中的 \b,如下:
var result = "[JS] Lesson_01.mp4".replace(/\b/g, '#');
console.log(result); // => "[#JS#] #Lesson_01#.#mp4#"
"[#JS#] #Lesson_01#.#mp4#"中的每一个#是怎么来的?
- 第一个"#",两边是"[“与"J”,是 \W 和 \w 之间的位置。
- 第二个"#",两边是"S"与"]",也就是 \w 和 \W 之间的位置。
- 第三个"#",两边是空格与"L",也就是 \W 和 \w 之间的位置。
- 第四个"#",两边是"1"与".",也就是 \w 和 \W 之间的位置。
- 第五个"#",两边是".“与"m”,也就是 \W 和 \w 之间的位置。
- 第六个"#",其对应的位置是结尾,但其前面的字符"4"是 \w,即 \w 和 $ 之间的位置。
(
\w是字符组[0-9a-zA-Z_]的简写形式,即\w是字母数字或者下划线的中任何一个字符。而\W是排除字符组[^0-9a-zA-Z_]的简写形式,即\W是\w以外的任何一个字符。)
\B就是非单词边界。在字符串中所有位置中,扣掉\b,剩下的都是\B的。具体说来就是\w与\w、\W与\W、^与\W,\W与$之间的位置。
比如上面的例子,把所有 \B 替换成 #:
var result = "[JS] Lesson_01.mp4".replace(/\B/g, '#');
console.log(result); // => "#[J#S]# L#e#s#s#o#n#_#0#1.m#p#4"
? (?=p) 和 (?!p)
(?=p),(学名是positive lookahead,正向先行断言),其中p是一个子模式,即p前面的位置。
比如 (?=l),表示 ‘l’ 字符前面的位置,例如:
var result = "hello".replace(/(?=l)/g, '#');
console.log(result); // => "he#l#lo"
(?!p)就是(?=p)的反面意思(学名是negative lookahead,负向先行断言)。
比如:
var result = "hello".replace(/(?!l)/g, '#');
console.log(result); // => "#h#ell#o#"
ES6 中,还支持 (?<=p) (positive lookbehind )和 (?<!p) (negative lookbehind)。
3. 位置的特性
对于位置的理解,我们可以理解成空字符 ""。比如 “hello” 字符串等价于如下的形式:
"hello" == "" + "h" + "" + "e" + "" + "l" + "" + "l" + "o" + "";
也等价于:
"hello" == "" + "" + "hello"
因此,把 /^hello$/ 写成 /^^hello$$$/,是没有任何问题的。
甚至可以写成更复杂的:
var result = /(?=he)^^he(?=\w)llo$\b\b$/.test("hello");
console.log(result); // => true
也就是说字符之间的位置,可以写成多个。
正则表达式括号的作用
1. 分组和分支结构
? 分组
我们知道 /a+/ 匹配连续出现的 “a”,而要匹配连续出现的 “ab” 时,需要使用 /(ab)+/。
其中括号是提供分组功能,使量词 + 作用于 “ab” 这个整体。
? 分支结构
而在多选分支结构 (p1|p2) 中,括号提供了子表达式的所有可能。
比如,要匹配如下的字符串:I love JavaScriptI love Regular Expression 可以使用正则:
var regex = /^I love (JavaScript|Regular Expression)$/;
console.log( regex.test("I love JavaScript") ); // => true
console.log( regex.test("I love Regular Expression") ); // => true
如果去掉正则中的括号,即 /^I love JavaScript|Regular Expression$/,匹配字符串则是 “I love JavaScript” 和 “Regular Expression”
2. 引用分组
这是括号一个重要的作用,有了它,我们就可以进行 数据提取,以及更强大的 替换操作。
而要使用它带来的好处,必须配合使用实现环境的 API。
以日期为例。假设格式是 yyyy-mm-dd 的,我们可以先写一个简单的正则:
var regex = /\d{4}-\d{2}-\d{2}/;
然后再修改成括号版的:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
为什么要使用括号版的正则呢?
? 提取数据
比如提取出年、月、日,可以这么做:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2020-02-19";
console.log( string.match(regex) ); // => ["2020-02-19", "2020", "02", "19", index: 0, input: "2020-02-19"]
match 返回的一个数组,第一个元素是整体匹配结果,然后是各个分组(括号里)匹配的内容,然后是匹配下标,最后是输入的文本。(如果正则有修饰符 g,match 返回的数组格式是不一样的)。
另外也可以使用正则对象的 exec 方法:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2020-02-19";
console.log( regex.exec(string) ); // ["2020-02-19", "2020", "02", "19", index: 0, input: "2020-02-19"]
同时,也可以使用构造函数的全局属性 $1 至 $9 来获取:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2020-02-19;
regex.test(string); // 正则操作即可,或:
//regex.exec(string);
//string.match(regex);
console.log(RegExp.$1); // "2020"
console.log(RegExp.$2); // "02"
console.log(RegExp.$3); // "19"
? 替换
比如,想把 yyyy-mm-dd 格式,替换成 mm/dd/yyyy 。
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2020-02-19";
var result = string.replace(regex, "$2/$3/$1");
console.log(result); // => "02/19/2020"
其中 replace 中的,第二个参数里用 $1、$2、$3 指代相应的分组。
? 反向引用
除了使用相应 API 来引用分组,也可以在正则本身里引用分组。但只能引用之前出现的分组,即反向引用。
还是以日期为例。比如要写一个正则支持匹配:2020-06-12 2020/06/12 2020.06.12 三种格式。
我们需要要求分割符前后一致。此时需要使用反向引用:
var regex = /\d{4}(-|\/|\.)\d{2}\1\d{2}/;
var string1 = "2020-06-12";
var string2 = "2020/06/12";
var string3 = "2020.06.12";
var string4 = "2020-06/12";
console.log( regex.test(string1) ); // true
console.log( regex.test(string2) ); // true
console.log( regex.test(string3) ); // true
console.log( regex.test(string4) ); // false
\1 表示的引用之前的那个分组 (-|\/|\.)。不管它匹配到什么,\1 都匹配那个同样的具体某个字符。
而 \2 和 \3 分别指代 第二个 和第三个分组。
? 括号嵌套怎么办?
以左括号(开括号)为准。
比如:
var regex = /^((\d)(\d(\d)))\1\2\3\4$/;
var string = "1231231233";
console.log( regex.test(string) ); // true
console.log( RegExp.$1 ); // 123
console.log( RegExp.$2 ); // 1
console.log( RegExp.$3 ); // 23
console.log( RegExp.$4 ); // 3
?上述正则匹配模式:第一个字符是数字,比如说 1,第二个字符是数字,比如说 2,第三个字符是数字,比如说 3,接下来的是 \1,是第一个分组内容,那么看第一个开括号对应的分组是什么,是 123,接下来的是 \2,找到第 2 个开括号,对应的分组,匹配的内容是 1,接下来的是 \3,找到第 3 个开括号,对应的分组,匹配的内容是 23,最后的是 \4,找到第 4 个开括号,对应的分组,匹配的内容是 3。
? \10表示什么呢?
\10 是表示第 10 个分组,还是 \1 和 0 呢?答案是前者。
测试如下:
var regex = /(1)(2)(3)(4)(5)(6)(7)(8)(9)(#) \10+/;
var string = "123456789# ######"
console.log( regex.test(string) ); // => true
? 引用不存在的分组会怎样?
因为反向引用,是引用前面的分组,但我们 在正则里引用了不存在的分组时,此时正则不会报错,只是匹配反向引用的字符本身。
例如 \2,就匹配 “\2” 。( “\2” 表示对 “2” 进行了转义)
var regex = /\1\2\3\4\5\6\7\8\9/;
console.log( regex.test("\1\2\3\4\5\6\7\8\9") ); // true
console.log( "\1\2\3\4\5\6\7\8\9".split("") ); // [ '\u0001', '\u0002', '\u0003', '\u0004', '\u0005', '\u0006', '\u0007', '8', '9' ]
4. 非捕获分组
如果只想要括号最原始的功能,但不会引用它,即既不在 API 里引用,也不在正则里反向引用。此时可以使用 非捕获分组 (?:p),例如:
var regex = /(?:ab)+/g;
var string = "ababa abbb ababab";
console.log( string.match(regex) ); // => ["abab", "ab", "ababab"]
正则表达式回溯法原理
1. 没有回溯的匹配
假设我们的正则是 /ab{1,3}c/,其可视化形式是: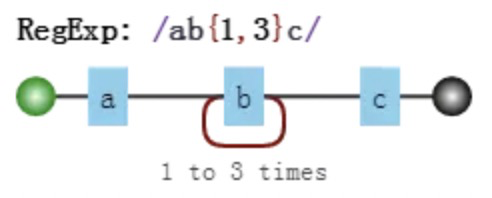
而当目标字符串是 "abbbc" 时,就没有所谓的“回溯”。其匹配过程是:
2. 有回溯的匹配
如果目标字符串是 "abbc",中间就有回溯。
图中第 5 步有红颜色,表示匹配不成功。此时
b{1,3}已经匹配到了 2 个字符 “b”,准备尝试第 3 个时,结果发现接下来的字符是 “c”。那么就认为b{1,3}就已经匹配完毕。然后状态又回到之前的状态(即第6步,与第4步一样),最后再用子表达式c,去匹配字符 “c”。此时整个表达式匹配成功了。
图中的第6步,就是“回溯”。
3. 常见的回溯形式
正则表达式匹配字符串的这种方式,有个学名,叫 回溯法。
回溯法 也称 试探法,它的 基本思想 是:从问题的某一种状态(初始状态)出发,搜索从这种状态出发所能达到的所有“状态”,当一条路走到“尽头”的时候(不能再前进),再后退一步或若干步,从另一种可能“状态”出发,继续搜索,直到所有的“路径”(状态)都试探过。这种不断“前进”、不断“回溯”寻找解的方法,就称作“回溯法”。
本质上就是 深度优先搜索算法。其中退到之前的某一步这一过程,我们称为“回溯”。从上面的描述过程中,可以看出,路走不通时,就会发生“回溯”。即尝试匹配失败时,接下来的一步通常就是回溯。
JS 中正则表达式会产生回溯的地方:
? 贪婪量词
比如 b{1,3},因为其是贪婪的,尝试可能的顺序是从多往少的方向去尝试。首先会尝试 “bbb”,然后再看整个正则是否能匹配。不能匹配时,吐出一个 “b”,即在 “bb” 的基础上,再继续尝试。如果还不行,再吐出一个,再试。如果还不行呢?只能说明匹配失败了。虽然局部匹配是贪婪的,但也要满足整体能正确匹配。
此如果当多个贪婪量词挨着存在,并相互有冲突时,此时会是怎样?答案是,先下手为强!因为深度优先搜索。测试如下:
var string = "12345";
var regex = /(\d{1,3})(\d{1,3})/;
console.log( string.match(regex) ); // => ["12345", "123", "45", index: 0, input: "12345"]
前面的
\d{1,3}匹配的是 “123”,后面的\d{1,3}匹配的是 “45”。
? 惰性量词
惰性量词就是在贪婪量词后面加个问号。表示尽可能少的匹配,比如:
var string = "12345";
var regex = /(\d{1,3}?)(\d{1,3})/;
console.log( string.match(regex) ); // => ["1234", "1", "234", index: 0, input: "12345"]
\d{1,3}?只匹配到一个字符 “1”,而后面的\d{1,3}匹配了"234"。
虽然惰性量词不贪,但也会有回溯的现象。比如正则是:
目标字符串是 "12345",匹配过程是:
知道你不贪、很知足,但是为了整体匹配成,没办法,也只能给你多塞点了。因此最后 \d{1,3}? 匹配的字符是 “12”。
? 分支结构
我们知道分支也是惰性的,比如 /can|candy/,去匹配字符串 “candy”,得到的结果是 “can”,因为分支会一个一个尝试,如果前面的满足了,后面就不会再试验了。
分支结构,可能前面的子模式会形成了局部匹配,如果接下来表达式整体不匹配时,仍会继续尝试剩下的分支。这种尝试也可以看成一种回溯。
比如正则:

目标字符串是 "candy",匹配过程:
上面第 5 步,虽然没有回到之前的状态,但仍然回到了分支结构,尝试下一种可能。所以,可以认为它是一种回溯的。
正则表达式的拆分
1. 结构和操作符
编程语言一般都有操作符。只要有操作符,就会出现一个问题。当一大堆操作在一起时,先操作谁,又后操作谁呢?为了不产生歧义,就需要语言本身定义好操作顺序,即所谓的优先级。
而在正则表达式中,操作符都体现在结构中,即由特殊字符和普通字符所代表的一个个特殊整体。
JS 正则表达式中的结构:字符字面量、字符组、量词、锚字符、分组、选择分支、反向引用。
- 字面量,匹配一个具体字符,包括不用转义的和需要转义的。比如
a匹配字符 “a”、\n匹配换行符、\.匹配小数点。- 字符组,匹配一个字符,可以是多种可能之一,比如
[0-9],表示匹配一个数字。也有\d的简写形式。另外还有反义字符组,表示可以是除了特定字符之外任何一个字符,比如[^0-9],表示一个非数字字符,也有\D的简写形式。- 量词,表示一个字符连续出现,比如
a{1,3}表示 “a” 字符连续出现 3 次。另外还有常见的简写形式,比如a+表示 “a” 字符连续出现至少一次。- 锚点,匹配一个位置,而不是字符。比如
^匹配字符串的开头、\b匹配单词边界,又比如(?=\d)表示数字前面的位置。- 分组,用括号表示一个整体,比如
(ab)+,表示 “ab” 两个字符连续出现多次,也可以使用非捕获分组(?:ab)+。- 分支,多个子表达式多选一,比如
abc|bcd,表达式匹配 “abc” 或者 “bcd” 字符子串。- 反向引用,比如
\2,表示引用第 2 个分组。
其中涉及到的操作符有:
- 1.转义符
\ - 2.括号和方括号
(...)、(?:...)、(?=...)、(?!...)、[...] - 3.量词限定符
{m}、{m,n}、{m,}、?、*、+ - 4.位置和序列
^、$、\元字符、一般字符 - 5.管道符
|
上面操作符的 优先级 从上至下,由高到低。
举例,正则:/ab?(c|de*)+|fg/
- 由于括号的存在,所以,
(c|de*)是一个整体结构。 - 在
(c|de*)中,注意其中的量词*,因此e*是一个整体结构。 - 又因为分支结构
|优先级最低,因此c是一个整体、而de*是另一个整体。 - 同理,整个正则分成了
a、b?、(...)+、f、g。而由于分支的原因,又可以分成ab?(c|de*)+和fg这两部分。

2. 注意要点
? 匹配字符串整体问题
因为是要匹配整个字符串,我们经常会在正则前后中加上锚字符 ^ 和 $。比如要匹配目标字符串 "abc" 或者 "bcd" 时,如果一不小心,就会写成 /^abc|bcd$/。
而位置字符和字符序列优先级要比竖杠高,故其匹配的结构是:
应该修改成:
? 量词连缀问题
假设,要匹配这样的字符串:
- 每个字符为a、b、c任选其一
- 字符串的长度是3的倍数
此时正则不能想当然地写成 /^[abc]{3}+$/,这样会报错,说 + 前面没什么可重复的,要修改成:/([abc]{3})+/
? 元字符转义问题
所谓元字符,就是正则中有特殊含义的字符。
所有结构里,用到的元字符有:^ $ . * + ? | \ / ( ) [ ] { } = ! : - , 。
当匹配上面的字符本身时,可以一律转义:
var string = "^$.*+?|\\/[]{}=!:-,";
var regex = /\^\$\.\*\+\?\|\\\/\[\]\{\}\=\!\:\-\,/;
console.log( regex.test(string) ); // => true
在 string 中,也可以把每个字符转义,当然,转义后的结果仍是本身:
var string = "^$.*+?|\\/[]{}=!:-,";
var string2 = "\^\$\.\*\+\?\|\\\/\[\]\{\}\=\!\:\-\,";
console.log( string == string2 ); // => true
并不是每个字符都需要转义。
? 字符组中的元字符
跟字符组相关的元字符有 []、^、-。因此在会引起歧义的地方进行转义。例如开头的 ^ 必须转义,不然会把整个字符组,看成反义字符组。
var string = "^$.*+?|\\/[]{}=!:-,";
var regex = /[\^$.*+?|\\/\[\]{}=!:\-,]/g;
console.log( string.match(regex) ); // => ["^", "$", ".", "*", "+", "?", "|", "\", "/", "[", "]", "{", "}", "=", "!", ":", "-", ","]
? 匹配“[abc]”和“{3,5}”
我们知道 [abc] 是个字符组。如果要匹配字符串 “[abc]” 时,该怎么办?
可以写成 /\[abc\]/,也可以写成 /\[abc]/。
只需要在第一个方括号转义即可,因为后面的方括号构不成字符组,正则不会引发歧义,自然不需要转义。
同理,要匹配字符串 “{3,5}”,只需要把正则写成 /\{3,5}/ 即可。
另外,我们知道量词有简写形式 {m,},却没有 {,n} 的情况。虽然后者不构成量词的形式,但此时并不会报错。当然,匹配的字符串也是 “{,n}”。
? 其余情况
比如 = ! : - , 等符号,只要不在特殊结构中,也不需要转义。
但是,括号需要前后都转义的,如 /\(123\)/。
至于剩下的 ^ $ . * + ? | \ / 等字符,只要不在字符组内,都需要转义的。
正则表达式的构建
1. 平衡法则
构建正则需要做到下面几点的平衡:
- 匹配预期的字符串
- 不匹配非预期的字符串
- 可读性和可维护性
- 效率
2. 构建正则前提
? 是否能使用正则
正则虽然强大,但不是万能的,很多看似很简单的事情,还是做不到的。
比如匹配这样的字符串:1010010001.... 虽然很有规律,但是只靠正则就是无能为力。
? 是否有必要使用正则
要认识到正则的局限,不要去研究根本无法完成的任务。同时,也不能走入另一个极端:无所不用正则。能用字符串API解决的简单问题,就不该正则出马。
- 比如,从日期
"2017-07-01"中 提取出年月日,虽然可以使用正则。但也可以使用字符串的split方法来做。 - 比如,判断是否有问号,虽然可以使用:
但也可以使用字符串的var string = "?id=xx&act=search"; console.log( string.search(/\?/) ); // => 0indexOf方法:var string = "?id=xx&act=search"; console.log( string.indexOf("?") ); // => 0 - 比如 获取子串,虽然可以使用正则,但也可以直接使用字符串的
substring或substr方法来做。
? 是否有必要构建一个复杂的正则
复杂的正则可以用多个小正则来做。
比如密码匹配问题,要求密码长度 6-12 位,由数字、小写字符和大写字母组成,但必须至少包括 2 种字符。
我们之前写出的正则是:/(?!^[0-9]{6,12}$)(?!^[a-z]{6,12}$)(?!^[A-Z]{6,12}$)^[0-9A-Za-z]{6,12}$/ 。
其实可以使用多个小正则来做:
var regex1 = /^[0-9A-Za-z]{6,12}$/;
var regex2 = /^[0-9]{6,12}$/;
var regex3 = /^[A-Z]{6,12}$/;
var regex4 = /^[a-z]{6,12}$/;
function checkPassword(string) {
if (!regex1.test(string)) return false;
if (regex2.test(string)) return false;
if (regex3.test(string)) return false;
if (regex4.test(string)) return false;
return true;
}
3. 准确性
所谓准确性,就是能匹配预期的目标,并且不匹配非预期的目标。
4. 效率
保证了准确性后,才需要是否要考虑要优化。大多数情形是不需要优化的,除非运行的非常慢。
正则表达式的运行分为如下的阶段:
- 编译
- 设定起始位置
- 尝试匹配
- 匹配失败的话,从下一位开始
- 继续第3步最终结果:匹配成功或失败
优化手法:
? 使用具体型字符组来代替通配符,来消除回溯
例如,匹配双引用号之间的字符。如,匹配字符串 123"abc"456 中的 "abc"。
- 如果正则用的是:
/".*"/,,会在第 3 阶段产生 4 次回溯 - 如果正则用的是:
/".*?"/,会产生 2 次回溯
要使用具体化的字符组,来代替通配符.,以便消除不必要的字符,此时使用正则 /"[^"]*"/,即可。
? 使用非捕获型分组
因为括号的作用之一是,可以捕获分组和分支里的数据。那么就需要内存来保存它们。
当我们不需要使用分组引用和反向引用时,此时可以使用非捕获分组。
例如:/^[+-]?(\d+\.\d+|\d+|\.\d+)$/ 可以修改成:/^[+-]?(?:\d+\.\d+|\d+|\.\d+)$/。
? 独立出确定字符
例如 /a+/,可以修改成 /aa*/。
因为后者能比前者多确定了字符 a。这样会加快判断是否匹配失败,进而加快移位的速度。
? 提取分支公共部分
- 比如
/^abc|^def/,修改成/^(?:abc|def)/。 - 又比如
/this|that/,修改成/th(?:is|at)/。
这样做,可以减少匹配过程中可消除的重复。
? 减少分支的数量,缩小它们的范围
/red|read/,可以修改成 /rea?d/。此时分支和量词产生的回溯的成本是不一样的。但这样优化后,可读性会降低。
正则表达式编程
1. 正则表达式的四种操作
正则表达式是 匹配模式,不管如何使用正则表达式,万变不离其宗,都需要先“匹配”。
有了匹配这一基本操作后,才有其他的操作:验证、切分、提取、替换。
进行任何相关操作,也需要宿主引擎相关 API 的配合使用。
? 验证
验证是正则表达式最直接的应用,比如表单验证。
在说验证之前,先要说清楚匹配是什么概念。
所谓 匹配,就是看目标字符串里是否有满足匹配的子串。因此,“匹配”的本质就是 “查找”。
有没有匹配,是不是匹配上,判断是否的操作,即称为 “验证”。
这里举一个例子,来看看如何使用相关 API 进行验证操作的。
比如,判断一个字符串中是否有数字。
- 使用
searchvar regex = /\d/; var string = "abc123"; console.log( !!~string.search(regex) ); // => true - 使用
testvar regex = /\d/; var string = "abc123"; console.log( regex.test(string) ); // => true - 使用
matchvar regex = /\d/; var string = "abc123"; console.log( !!string.match(regex) ); // => true - 使用
execvar regex = /\d/; var string = "abc123"; console.log( !!regex.exec(string) ); // => true
其中,最常用的是 test。
? 切分
匹配上了,我们就可以进行一些操作,比如切分。
所谓 “切分”,就是把目标字符串,切成一段一段的。在 JS 中使用的是 split。
比如,目标字符串是 "html,css,javascript",按逗号来切分:
var regex = /,/;
var string = "html,css,javascript";
console.log( string.split(regex) ); // => ["html", "css", "javascript"]
又比如,如下的日期格式:
2020/02/21
2020.02.21
2020-02-21
可以使用 split “切出”年月日:
var regex = /\D/;
console.log( "2020/02/21".split(regex) ); // => ["2020", "02", "21"]
console.log( "2020.02.21".split(regex) ); // => ["2020", "02", "21"]
console.log( "2020-02-21".split(regex) ); // => ["2020", "02", "21"]
? 提取
虽然整体匹配上了,但有时需要提取部分匹配的数据。
此时正则通常要使用分组引用(分组捕获)功能,还需要配合使用相关 API。
这里,还是以日期为例,提取出年月日。注意下面正则中的括号:
matchvar regex = /^(\d{4})\D(\d{2})\D(\d{2})$/; var string = "2020-02-21"; console.log( string.match(regex) ); // =>["2020-02-21", "2020", "02", "21", index: 0, input: "2020-02-21"]execvar regex = /^(\d{4})\D(\d{2})\D(\d{2})$/; var string = "2020-02-21"; console.log( regex.exec(string) ); // =>["2020-02-21", "2020", "02", "21", index: 0, input: "2020-02-21"]testvar regex = /^(\d{4})\D(\d{2})\D(\d{2})$/; var string = "2020-02-21"; regex.test(string); console.log( RegExp.$1, RegExp.$2, RegExp.$3 ); // => "2020" "02" "21"searchvar regex = /^(\d{4})\D(\d{2})\D(\d{2})$/; var string = "2020-02-21"; string.search(regex); console.log( RegExp.$1, RegExp.$2, RegExp.$3 ); // => "2020" "02" "21"replacevar regex = /^(\d{4})\D(\d{2})\D(\d{2})$/; var string = "2020-02-21"; var date = []; string.replace(regex, function(match, year, month, day) { date.push(year, month, day); }); console.log(date); // => ["2020", "02", "21"]
其中,最常用的是 match。
? 替换
找,往往不是目的,通常下一步是为了替换。
在 JS 中,使用 replace 进行替换。比如把日期格式,从 yyyy-mm-dd 替换成 yyyy/mm/dd:
var string = "2020-02-21";
var today = new Date( string.replace(/-/g, "/") );
console.log( today ); // => Fri Feb 21 2020 00:00:00 GMT+0800 (中国标准时间)
2. 相关API注意要点
从上面可以看出用于正则操作的方法,共有6个,字符串实例 4 个,正则实例 2 个:
String#search
String#split
String#match
String#replace
RegExp#test
RegExp#exec
? search 和 match 的参数问题
我们知道字符串实例的那 4 个方法参数都支持正则和字符串。但 search 和 match,会把字符串转换为正则的。
? match 返回结果的格式问题
match 返回结果的格式,与正则对象是否有修饰符 g 有关。
var string = "2020.02.21";
var regex1 = /\b(\d+)\b/;
var regex2 = /\b(\d+)\b/g;
console.log( string.match(regex1) ); // => ["2020", "02", "21", index: 0, input: "2020.02.21"]
console.log( string.match(regex2) ); // => ["2020", "02", "21"]
- 没有
g,返回的是 标准匹配格式,即,数组的第一个元素是整体匹配的内容,接下来是分组捕获的内容,然后是整体匹配的第一个下标,最后是输入的目标字符串。 - 有
g,返回的是 所有匹配的内容。 - 当没有匹配时,不管有无
g,都返回null。
? exec 比 match 更强大
当正则没有 g 时,使用 match 返回的信息比较多。但是有 g 后,就没有关键的信息 index 了。而 exec 方法就能解决这个问题,它能接着上一次匹配后继续匹配。
其中正则实例 lastIndex 属性,表示下一次匹配开始的位置。
比如第一次匹配了 “2020”,开始下标是 0,共 4 个字符,因此这次匹配结束的位置是 3,下一次开始匹配的位置是 4。
在使用
exec时,经常需要配合使用while循环。
? test 整体匹配时需要使用 ^ 和 $
test 是看目标字符串中是否有子串匹配正则,即有部分匹配即可。如果,要整体匹配,正则前后需要添加开头和结尾
? split 相关注意事项
- 第一,它可以有第二个参数,表示结果数组的最大长度:
var string = "html,css,javascript";
console.log( string.split(/,/, 2) ); // =>["html", "css"]
- 第二,正则使用分组时,结果数组中是包含分隔符的:
var string = "html,css,javascript";
console.log( string.split(/(,)/) ); // =>["html", ",", "css", ",", "javascript"]
? replace 是很强大的
总体来说 replace 有两种使用形式,这是因为它的第二个参数,可以是字符串,也可以是函数。
当第二个参数是字符串时,如下的字符有特殊的含义:
$1,$2, …,$99匹配第1~99个分组里捕获的文本$&匹配到的子串文本$`匹配到的子串的左边文本$'匹配到的子串的右边文本$$美元符号
? 使用构造函数需要注意的问题
一般不推荐使用构造函数生成正则,而应该优先使用字面量。因为用构造函数会多写很多\。
? 修饰符
ES5中修饰符,共3个:
g全局匹配,即找到所有匹配的,单词是 globali忽略字母大小写,单词 ingoreCasem多行匹配,只影响^和$,二者变成行的概念,即行开头和行结尾。单词是 multiline
? source属性
比如,在构建动态的正则表达式时,可以通过查看该属性,来确认构建出的正则到底是什么:
var className = "high";
var regex = new RegExp("(^|\\s)" + className + "(\\s|$)");
console.log( regex.source ); // => (^|\s)high(\s|$) 即字符串"(^|\\s)high(\\s|$)"
? 构造函数属性
构造函数的静态属性基于所执行的最近一次正则操作而变化。除了是$1,…, $9 之外,还有几个不太常用的属性(有兼容性问题):
RegExp.input最近一次目标字符串,简写成RegExp["$_"]RegExp.lastMatch最近一次匹配的文本,简写成RegExp["$&"]RegExp.lastParen最近一次捕获的文本,简写成RegExp["$+"]RegExp.leftContext目标字符串中lastMatch之前的文本,简写成RegExp["$"]`RegExp.rightContext目标字符串中lastMatch之后的文本,简写成RegExp["$'"]