作 者:十方
公众号:炼丹笔记 (1)Why Deep Retrieval?
一个规模较大的推荐系统,需要解决的核心问题就是如何从百万甚至亿级别的候选集中快速找到最相关的top-k个候选。以前的解决方案都是两步:
- 双塔模型,最后做Dot
- 用Annoy Tree或者HNSW给候选集建索引,在线计算向量实时检索top-k
之前方案存在的问题:
- 因为要分两步,而两步的目标是不一样的。
- 双塔限制了模型的表达能力
基于此,又出现了TDM等树结构模型,但是把每个候选分配到唯一一个叶子节点是最好的方案吗?所以end-to-end的Deep Retrieval(DR)就这样诞生了。
(2)Deep Retrieval 长什么样?
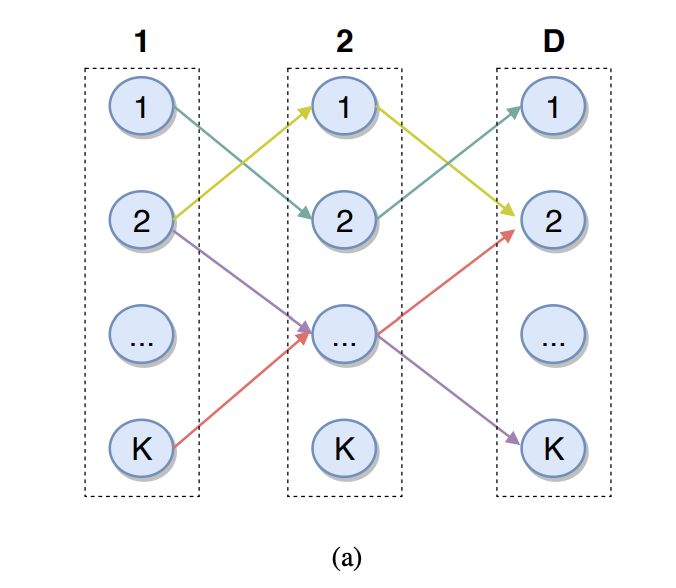
DR并没用用树结构,而是采用了一个矩阵结构(图a所示),现在规定只能从左向右走,因此走D步就可以走完这个矩阵,一共有K的D次方种走法,每一种走走法,都代表一簇候选。所以一个候选,可能存在于多种走法,一种走法也会有多个候选。类比到电商,比如一种类别就对应一种走法,一种类别包含多个商品,一个商品可能也属于多个类别,比如巧克力既可以是食品,也可以是情人节礼物。拿图(a)来说,(1,2,1)和(2,1,2)两条路径分别表示情人节礼物和食品,里面都可以有巧克力。
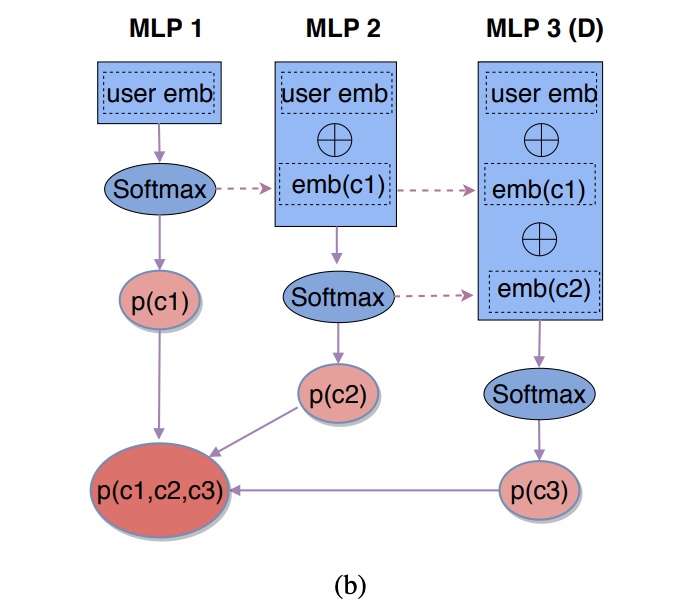
那怎么从从user的特征,找到一天路径,拉出候选商品呢。可以通过user特征,embeding后,user-embedding接softmax层确定先走到哪个节点,走第k步(k∈[1,D]),就可以用历史走过的所有节点的embedding和user-embedding concat在一起,接softmax层判断第k步走到应该走到哪个节点,最终得到的路径就可以拉出很多candidate了。
Deep Retrieval的优势:
- 训练的时候item的露肩可以和神经网络参数用EM算法一起学习
- Deep Retrieval是end-to-end的模型,容易部署
- 多对多的编码方式使得DR能学到user和item更复杂的关系
(三) Deep Retrieval如何定义目标函数?

既然是概率,我们就可以定义类似logloss的目标函数,如下式:
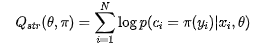
融合上面两个式子:
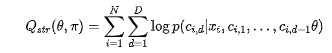
看到这里,大家肯定有疑问,不是一个商品对应多个路径吗,目标函数咋一点没体现?下面才开始介绍多路径的目标函数。
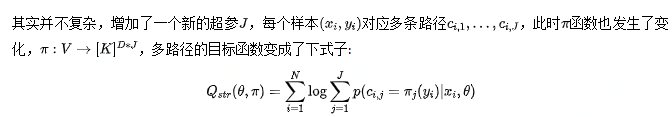
预估的时候,用Beam Search找到J条路径,合并每条路径召回的item即可。
(四)Deep Retrieval如何学习参数?
因为有目标函数有π的存在,所以目标函数不连续,也就不可以做梯度下降,因此论文提出EM算法解决这个问题,并用正则化降低过拟合。
再看下多路径目标函数:
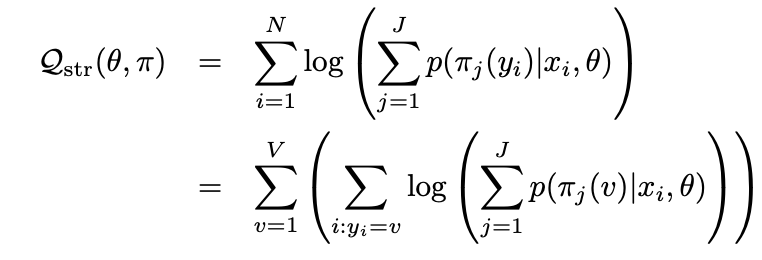
然后论文说上式有出现log(0)的风险,通过融合下面不等式,就可以避免这个情况:

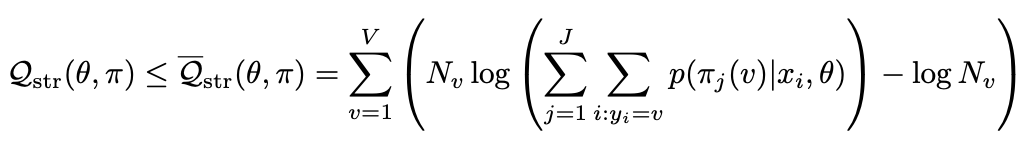
最终,EM训练算法总结如下,关于正则化就不细说了:

(五)Deep Retrieval为何如此优秀?
论文提到,Deep Retrieval能如此优秀,是因为目标函数包含了softmax层,因为一开始每个物品的路径是随机初始化的,增加了优化的困难,因为softmax的输入是共享embeding的,使得模型一直在往正确的方向学习,最后还用了beam search,所以召回如此优秀。