需求:
1、利用JavaScript+html 提取待处理文件
2、用正则表达式处理文件,得到目标格式
3、输出结果
首先,文件内容为:
想要得到的目标结果:([{900400: “请求参数不正确”},{900401: “用户未登录或登录已失效,请重新登录”}])
整体思路:
1、读取文件,并一行一行存进数组
2、对数组的每一条数据执行正则变换
2.1 将每一行数据存入数组
2.2 对数组中的数据按行进行正则变换
2.3 将变换后的数据进行判断,剔除无效数据
3、将变换后的结果输出
1、读取文件并按行存进数组
在html中,读取文件的方式非常简单
<input type="file" name="file" id="file">

这样就能打开本地文件了
1.1 按行存储
由于在js中,没有readLine方法,因此可以换个思路,用split()方法,按"\n" 分隔开,然后存进数组
var str = this.result.split('\n');
2、正则变换
在这个数据中,有效数据我们可以这样提取:可以看到有效数据分为数字和汉字,因此我们可以利用正则表达式将一个字段中的数字和汉字提取出来,因为我们是需要对一整片文章的每一条数据都进行正则变换的,因此需要一个for循环
for(var line = 0; line < str.length; line++){
var key = str[line].replace(/[^0-9]/ig, "") //提取数字
var value = str[line].replace(/[^\u4e00-\u9fa5]/gi,"") //提取汉字
}
这样就可以初步将数据提取出来了 
但是这样的数据掺杂无效数据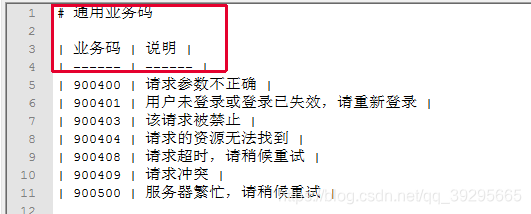
要讲这部分数据剔除掉,我们可以看到,有效数据的key(数字)值和value(汉字)值都不为空,因此就可以想到当key和value有一方为空时,就可以将这条数据删去
在数组中删除数据,主要有几种方法,这边我首先采用了delete str[line] 的方法,虽然数据时删掉了,但是这条数据还是存在的,只是此时的类型为undefined,输出结果为
出现了错误
第二次我采用splice(line,1) ,就是从line 行开始,删除一行,这个方法会将原先数据删去会导致数组的索引值发生变化,因为在遍历后也会出错
最后我换了个思路,当key和value均不为空时,再输出该数据
if(key != "" && value != ""){ //当key和value均不为空时,将变换后的数据输出
result = str[line]; //将有效数据复制给result
document.write(result.replace(/[^0-9]/ig, "") +":" + result.replace(/[^\u4e00-\u9fa5]/gi,"") + "<br />")
}
这样就能完整输出了
完整代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>正则表达式</title>
</head>
<body>
<input type="file" name="file" id="file">
<script charset="utf-8">
// 1、读取文件,并一行一行存进数组
// 2、对数组的每一条数据执行正则变换
// 2.1 将每一行数据存入数组
// 2.2 对数组中的数据按行进行正则变换
// 2.3 将变换后的数据进行判断,剔除无效数据
// 3、将变换后的结果输出
document.getElementById('file').onchange = function(){
var file = this.files[0];
var reader = new FileReader(); //读入文件
reader.onload = function(progressEvent){
var str = this.result.split('\n'); //按行分隔
var result;
for(var line = 0; line < str.length; line++){
// console.log(str[line]);
var key = str[line].replace(/[^0-9]/ig, "")
var value = str[line].replace(/[^\u4e00-\u9fa5]/gi,"")
// console.log(str)
if(key != "" && value != ""){ //当key和value均不为空时,将变换后的数据输出
result = str[line];
document.write(result.replace(/[^0-9]/ig, "") +":" + result.replace(/[^\u4e00-\u9fa5]/gi,"") + "<br />")
}
}
};
reader.readAsText(file);
};
</script>
</body>
</html>
待解决:
1、value中如果包含字母、数字或中文的情况要如何正则
对于这个问题我在想是不是可以用其他的方法剔除这两段数据,直接用splite根据 | 分割,是否可以提取到
欢迎讨论~