0.写在前面
based on CMU 15-445/645 2020fall, Lecture #21 ~ Lecture #24.
1: SYSTEM ARCHITECTURE

1)SHARED Everything:非分布式系统使用。
2)SHARED Memory:多个CPU通过一个通信层去使用同一个内存。
3)SHARED Disk:CPU上运行的worker有自己的本地内存,通过通信层共享磁盘。(可以直接扩充node,cpu之间需要通信来了解当前的状态)(云架构)
4)SHARED Nothing:每个worker都在自己的“孤岛”上自己干自己的事情。每个worker都有自己的内存和磁盘。(性能好,难扩容,难确保一致性)
SHARED DISK EXAMPLE:
SHARED NOTHING EXAMPLE:
2: DESIGN ISSUES
2.1核心问题
1)应用如何找数据?
2)如何查询分布式的数据?
3)DBMS如何确保正确性?
2.2 HORIZONTAL PARTITIONING
HORIZONTAL PARTITIONING:
根据tuple的column(s) 作为依据;可以采用Hash或者Range来分区。比如可以根据地区来进行Hash,浙江省的都在一个区中。
但是这里存在一个问题:如果我们增加一个分区,需要重新进行Hash,这将极大的增加成本。基于此我们提出一个很有趣的方法:CONSISTENT HASHING。(之前在分布式的时候也见过同样的思路)
此时增加一个分区P4,只需要对P3种的进行判断即可。
如果减少一个分区,只需要按时针顺序给到下一个分区。
Relication Factor做副本。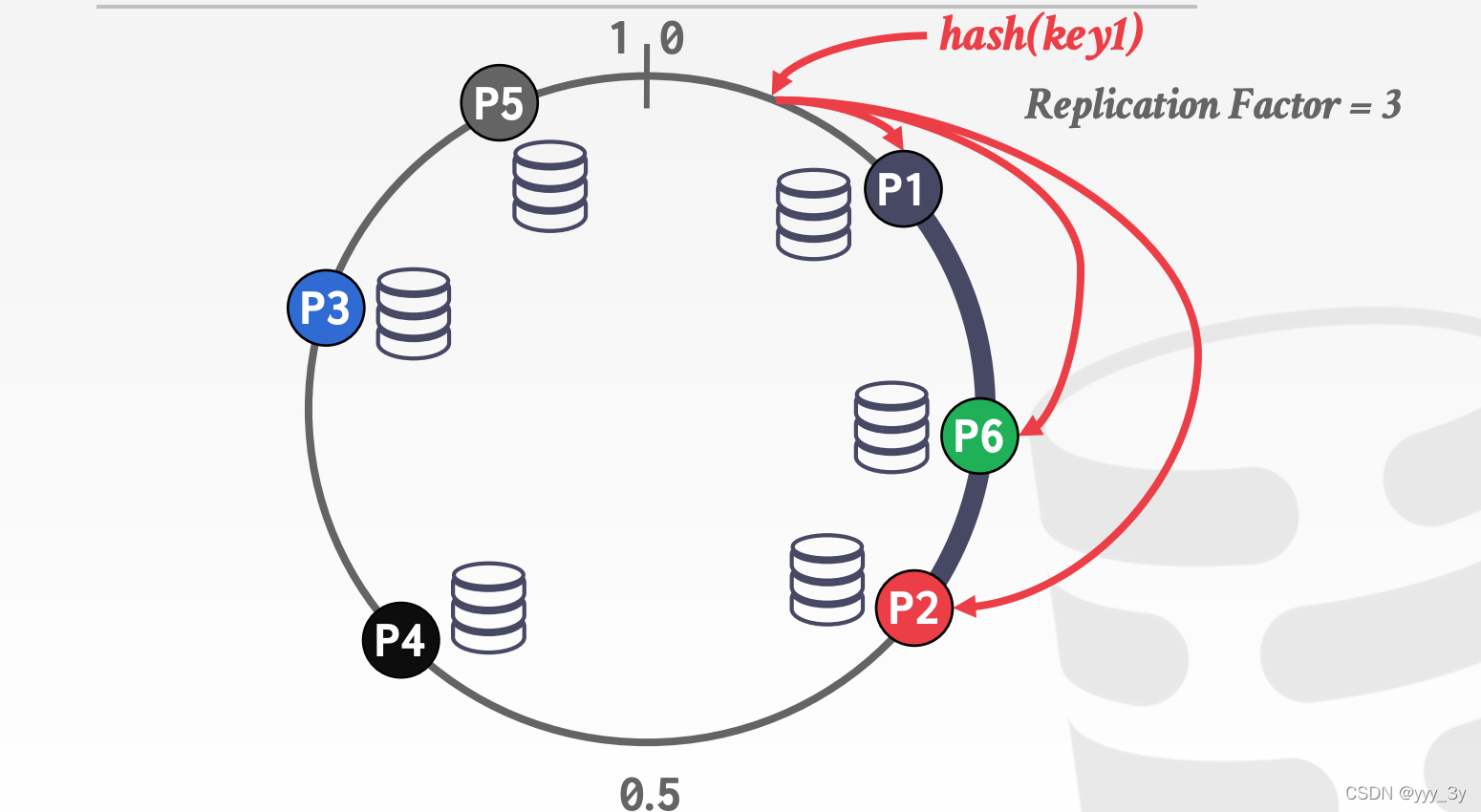
2.2 LOGICAL PARTITIONING(in shared disk)
工作方式:将数据库中的某一部分按(range or hash…)方法分配到不同的计算节点。
2.3 PHYSICAL PARTITIONING(in shared nothing)
工作方式:每个节点会管理自己分区的数据。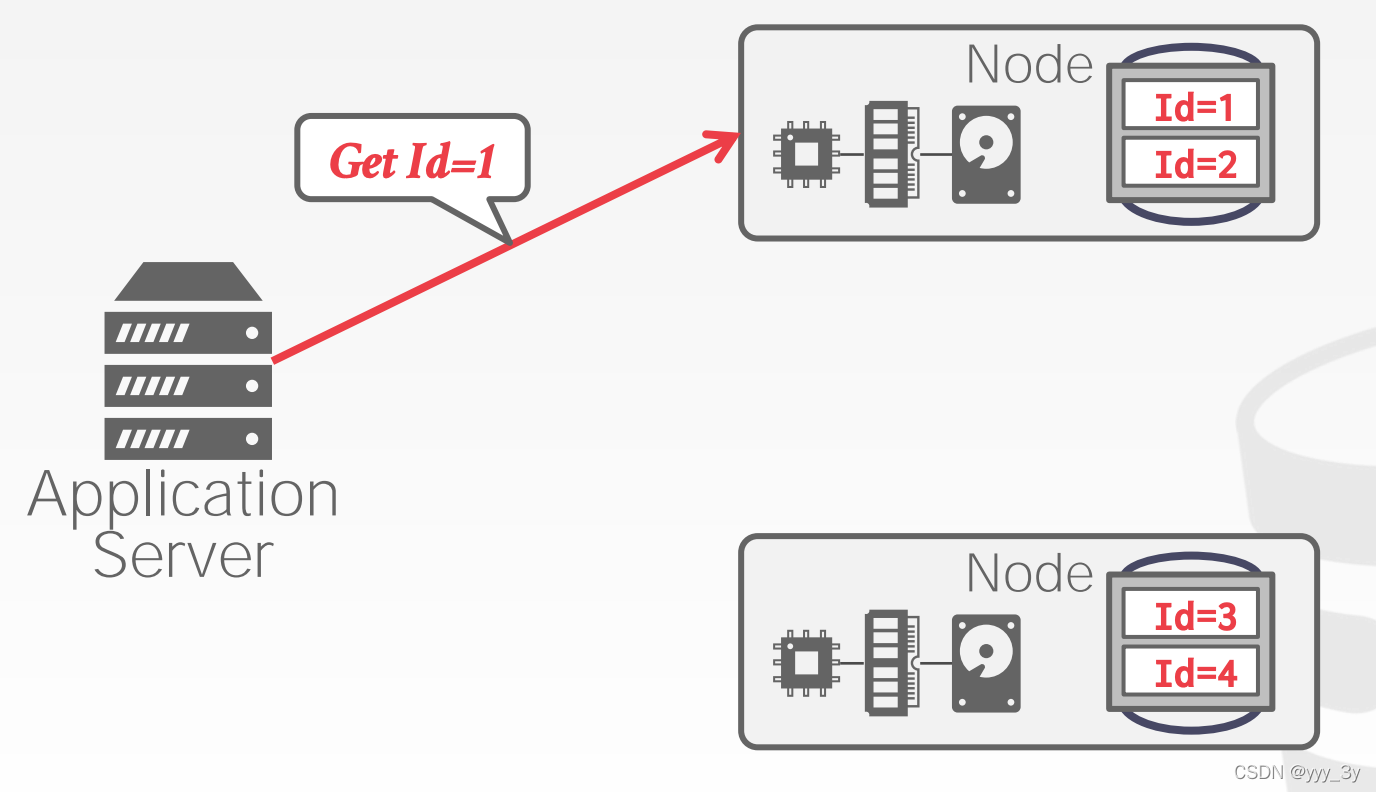
2.4 事务的一致性(在分布式中)
两种方法:
1)Centralized(中心化): Global “traffic cop”.
2)Decentralized(去中心化): Nodes organize themselves.
CENTRALIZED COORDINATOR(TP Monitor):
2.5 DISTRIBUTED CONCURRENCY CONTROL
DISTRIBUTED 2PL:
3: Distributed OLTP Databases与Distributed OLAP Databases
On-line Transaction Processing (OLTP):
→ Short-lived read/write txns.
→ Small footprint.
→ Repetitive operations.
(对事务的处理)
On-line Analytical Processing (OLAP):
→ Long-running, read-only queries.
→ Complex joins.
→ Exploratory queries.
(比如对浙江省地区购物消费的数据分析)
3.1 Distributed OLTP Databases
3.1.1 Atomic Commit Protocols
定义:当多个节点完成事务之后,DBMS需要询问所有参与事务的节点能否提交。
主要介绍2种Two-Phase Commit、Paxos
Two-Phase Commit:
Node1 is Coordinator. Node2 & 3 is Participant.
phase1(准备):Application Server 提出Commit Request请求,Coordinator向Participant发送请求,Participant返回是否ok,ok的话进入第二个阶段。
phase2(提交):Coordinator向Participant发送请求,Participant返回是否ok.(每个节点将每个阶段的结果记录在一个非易失性存储日志。)
如果说某个Participant出现abort的情况,那么就会直接返回(区别于Paxos,在Paxos大多数同意即可)
2个优化:
1)Early Prepare Voting:将最后执行的节点可以顺带一起返回vote结果。
2)Early Acknowledgement After Prepare:如图,如果所有的node都同意的话Coordinator可以先提交信息给client。

PAXOS:
从high-level角度来看,PAXOS和Two-Phase的思想是一致的。图中Node3虽然没有同意,但是依然可以Commit。

3.1.2 Replication
REPLICA CONFIGURATIONS:
2种类型:
Primary-Replica:所有更新都转到每个对象的指定主节点。
Multi-Primary:事务可以在任意node更新;Replicas之间需要通过原子提交协议来进行。
K-SAFETY:确保有K份备份。
PROPAGATION SCHEME:
定义:当一个 txn 在复制的数据库上提交时,DBMS 决定是否必须等待该 txn 的更改传播到其他节点之前,它可以将确认发送给应用程序。
2种方法:
1)Synchronous (Strong Consistency)(同步)
2)Asynchronous (Eventual Consistency)(异步 )
Consistency Issues (CAP):
三选二,不可能同时满足CAP。
CAP-CONSISTENCY: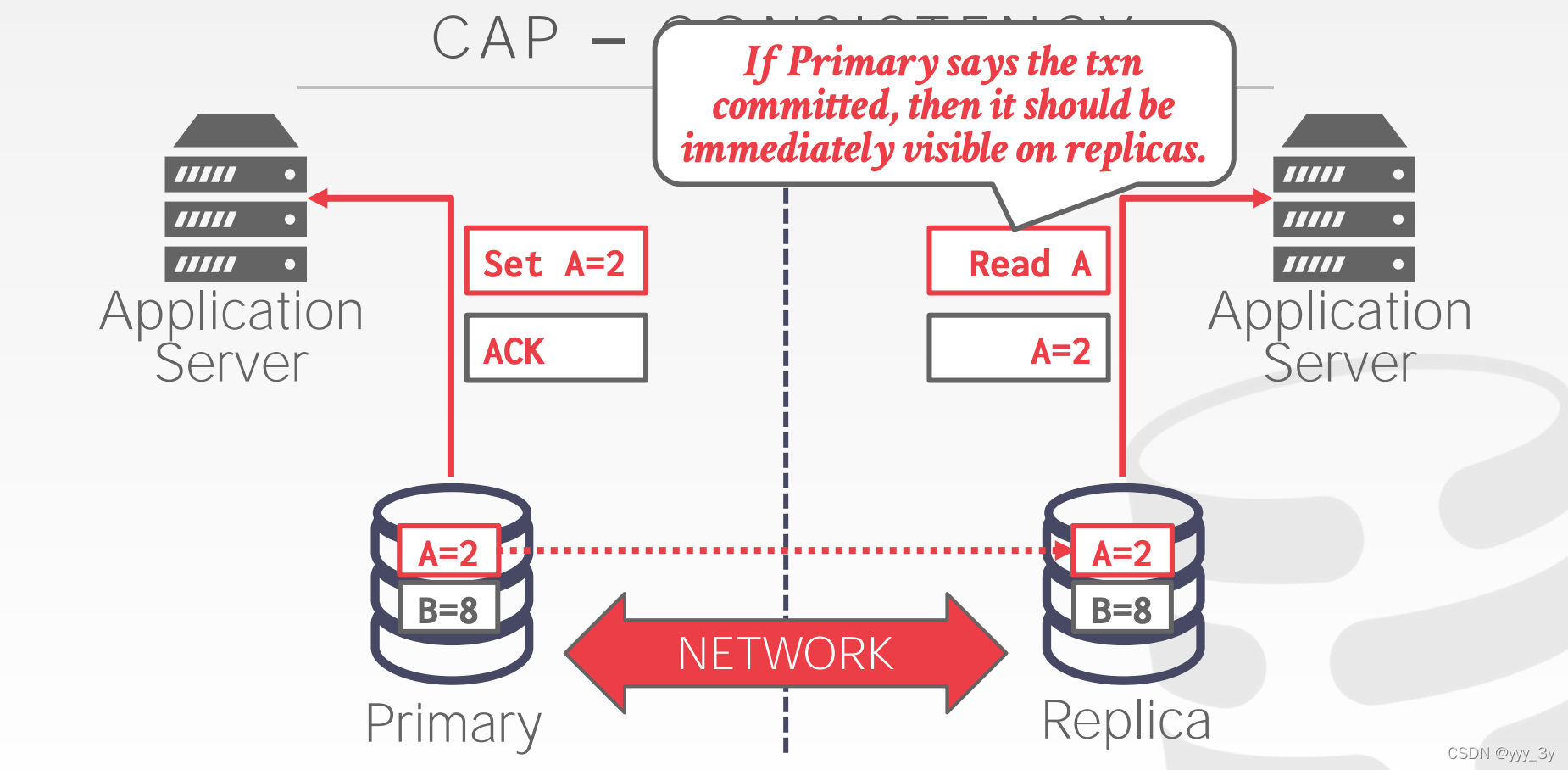
CAP-AVAIL ABILITY: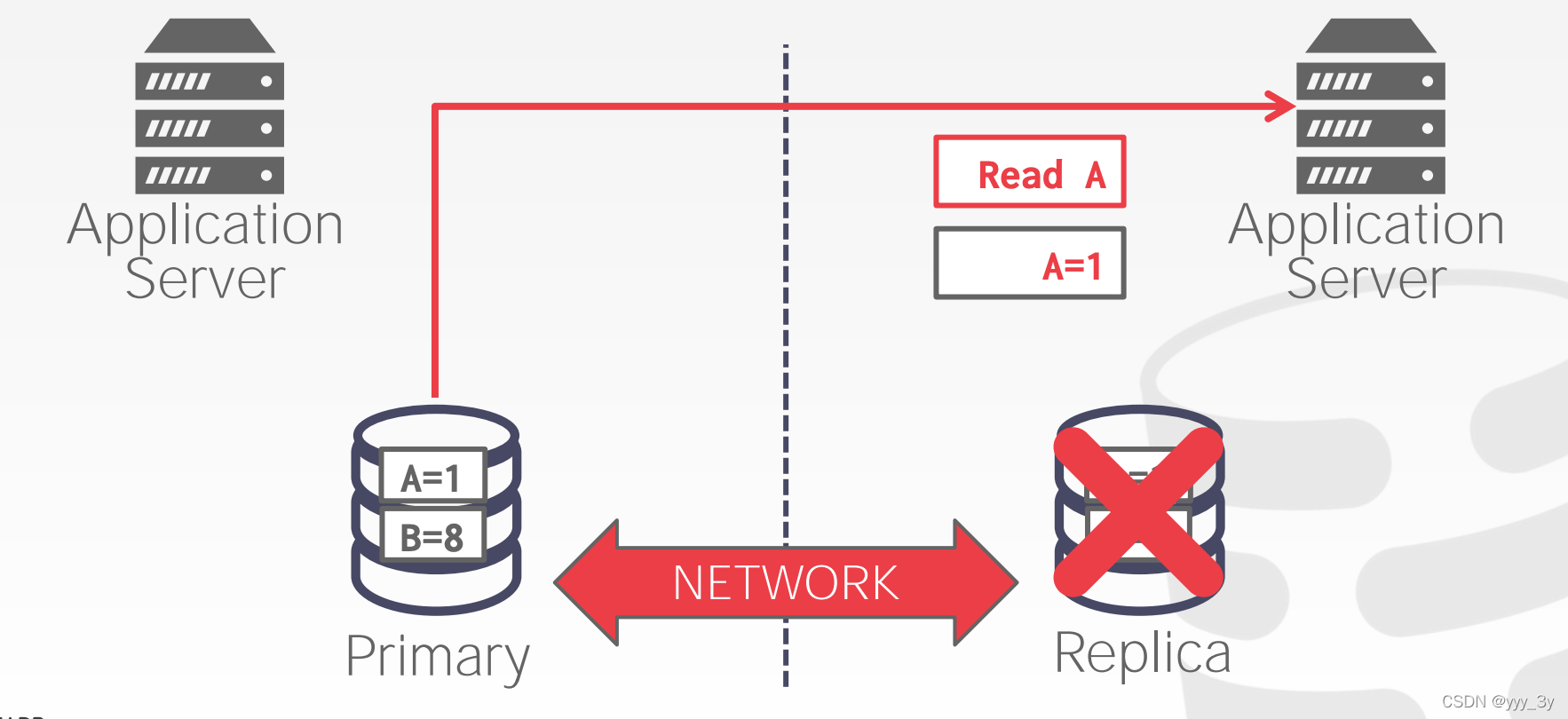
CAP-PARTITION TOLERANCE:
网络连接出现问题,会投票进行选举,选出新的primary,不满足K份复制的会停止工作。网络恢复以后,可能需要人工来修复。

3.2 Distributed OLAP Databases
一般数据库的标准配置:前端 OLTP 数据库,后端 OLAP 大型数据仓库(back-end data warehouse)
这两者有时候被称为 Data Silo,即数据孤岛,数据存储相互独立,彼此之间不会真的交流 然后就可以进行 ETL(Extract Transform Load) 的操作,即将业务系统的数据经过抽取、清洗、转换之后加载到数据仓库的过程。
以 Zynga 这家游戏公司为例,Zynga 收购了很多游戏初创公司,比如 FarmVille,它买下这些公司时,会去运行他们自己的前端 OLTP 数据库,只有他们将这些数据放入他们的后端大型仓库时,他们才能更高地分析出怎么做才能让你们在 FarmVille 上买东西等后端 OLAP 数据仓库拿到分析后的信息数据后,就推到前端 OLTP 数据库中。
3.2.1 PUSH VS. PULL
Approach #1: Push Query to Data
将query送到node中,node中包含数据。
Approach #2: Pull Data to Query
将数据带到正在执行查询的节点,需要它进行处理。
3.2.2 QUERY PLANNING
Approach #1: Physical Operators(大多数系统用的)
生成单个查询计划,然后将其分解为特定于分区的片段。
Approach #2: SQL
将原始查询重写为特定于分区的查询。
3.2.3 DISTRIBUTED JOIN ALGORITHMS
分布式连接的效率取决于目标表的分区模式。
SCENARIO #2:表被连接属性分区,每个节点执行连接在本地数据上,然后发送到节点用于合并。
SCENARIO #3:两个表以不同的key分区。 DBMS将其中一张表(小), “broadcasts”该表到所有节点。
SCENARIO #4:两个表都没有按着key做好的分区。 DBMS 复制表通过跨节点“shuffling”。
3.2.3 SERVERLESS DATABASES
而不是总是维护计算为每个客户提供资源,一个“serverless”DBMS当租户闲置时驱逐他们。

参考:https://www.bilibili.com/read/cv14580880