摘要
大多数方法着重于从单帧图像检测车道,并且在处理某些极差的情况(例如重影,严重的标记退化,严重的车辆遮挡等)时,通常会导致性能不令人满意。 实际上,车道是道路上的连续线结构。 因此,可以通过合并先前帧的信息来潜在地推断出在一个当前帧中不能准确检测到的车道。
引言
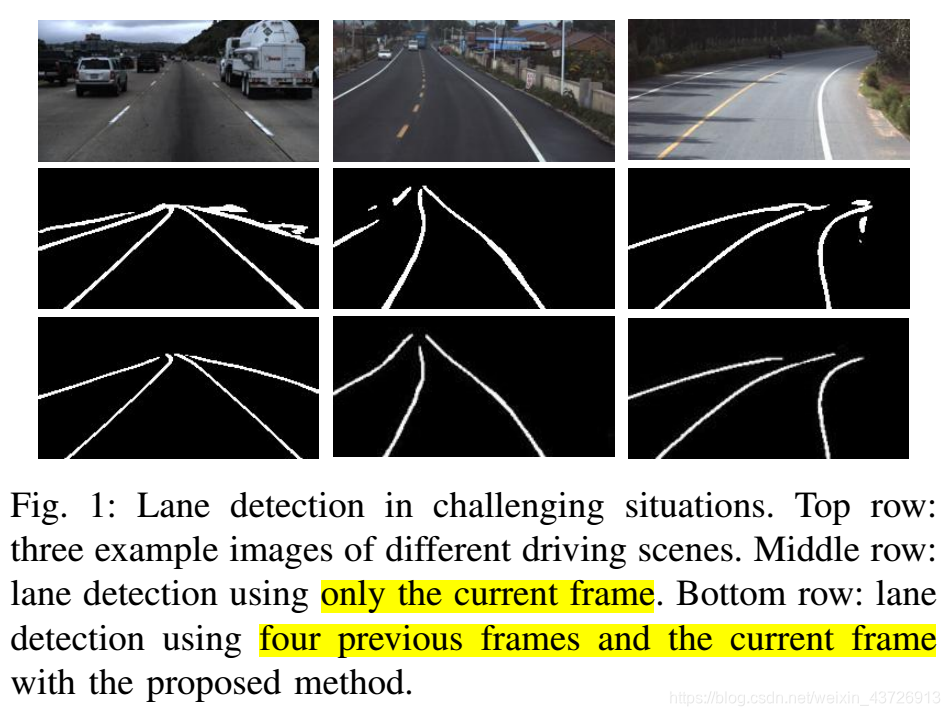
有挑战场景的车道检测效果如图1所示。
更精确地,即使该车道可能遭受由阴影,污点和遮挡所带来的损坏或退化,也可以通过使用多个先前的帧来预测当前车道中的车道。 这促使我们通过使用连续驾驶场景的图像来研究车道检测。
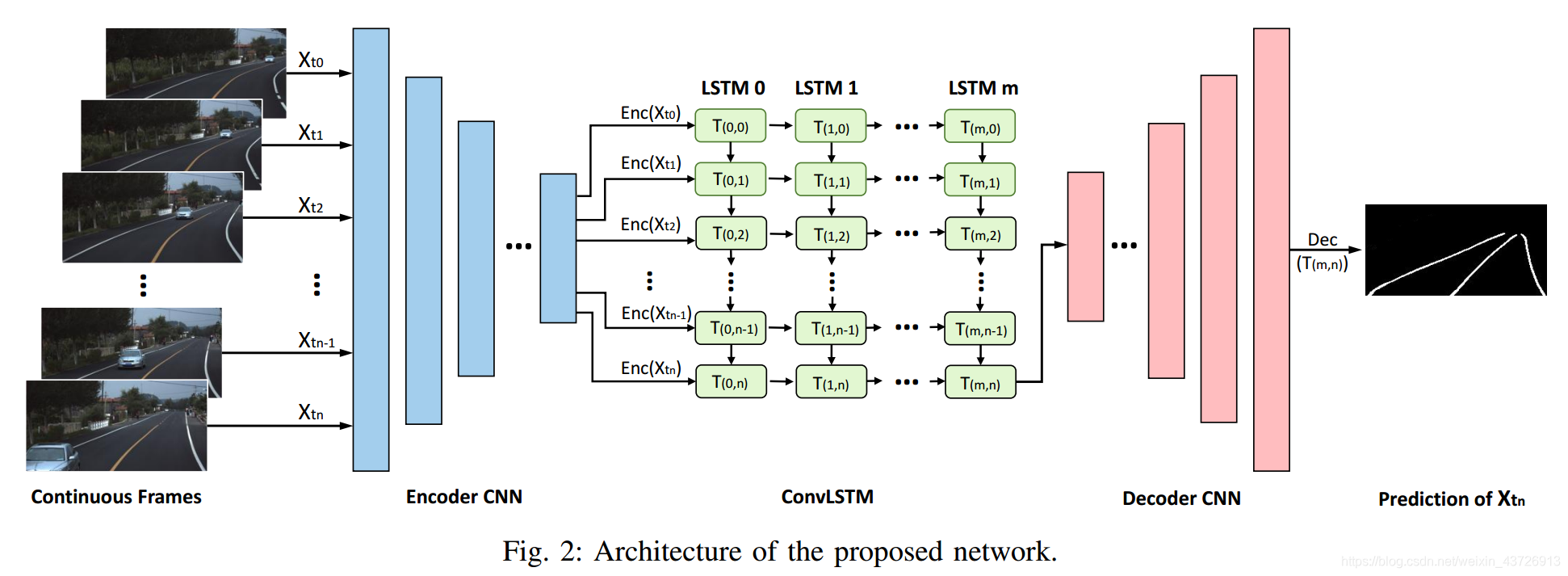
本文提出了一种混合深度神经网络,用于通过使用多个连续驾驶场景图像进行车道检测。 提出的混合深度神经网络将DCNN和DRNN结合在一起。 从全局的角度来看,所提出的网络是DCNN,它以多个帧为输入,并以语义分段的方式预测当前帧的通道。 提出了一种完全卷积的DCNN体系结构以实现分割目标。 它包含一个编码器网络和一个解码器网络,以确保最终的输出图具有与输入图像相同的大小。 从局部角度看,由DCNN的编码器网络抽象的特征将由DRNN进一步处理。 一个长短期记忆(LSTM)网络用于处理编码特征的时间序列。 DRNN的输出应该已经融合了连续输入帧的信息,并被馈送到DCNN的解码器网络以帮助预测通道。
contributions:
- 连续驾驶图片进行车道线检测可有效应用于有挑战性的场景。
- 无缝整合了DRNN和DCNN。
- 对Tusimple数据集进行了扩展,收集了一些有挑战性的驾驶场景。
相关工作
车道检测方法
传统方法
- 几何建模。两步:边缘检测、曲线拟合。
- 能量最小化。卡尔曼滤波、粒子滤波、卡尔曼粒子滤波。
基于深度学习方法
- 编码器-解码器CNN
- 带有优化算法的FCN
- CNN+RNN
- GAN模型
与上述基于深度学习的方法不同,本方法将车道检测建模为一个时间序列问题,并在多个连续帧中检测车道,而不仅仅是在一个当前帧中。 借助更丰富的信息,所提出的方法可以在有挑战的场景下的车道检测中获得强大的性能。 同时,该方法将CNN和RNN无缝集成,为车道检测提供了端到端的可训练网络。
ConvLSTM用于视频分析
所述方法
系统架构
网络架构如图2所示。编码器CNN和解码器CNN是两个完全卷积的网络。 通过将多个连续帧作为输入,编码器CNN对其进行处理并获得时间序列的特征图。 然后将特征图输入到LSTM网络中,以进行车道信息预测。 LSTM的输出被馈送到解码器CNN中,以产生用于车道预测的概率图。 车道概率图具有与输入图像相同的大小。
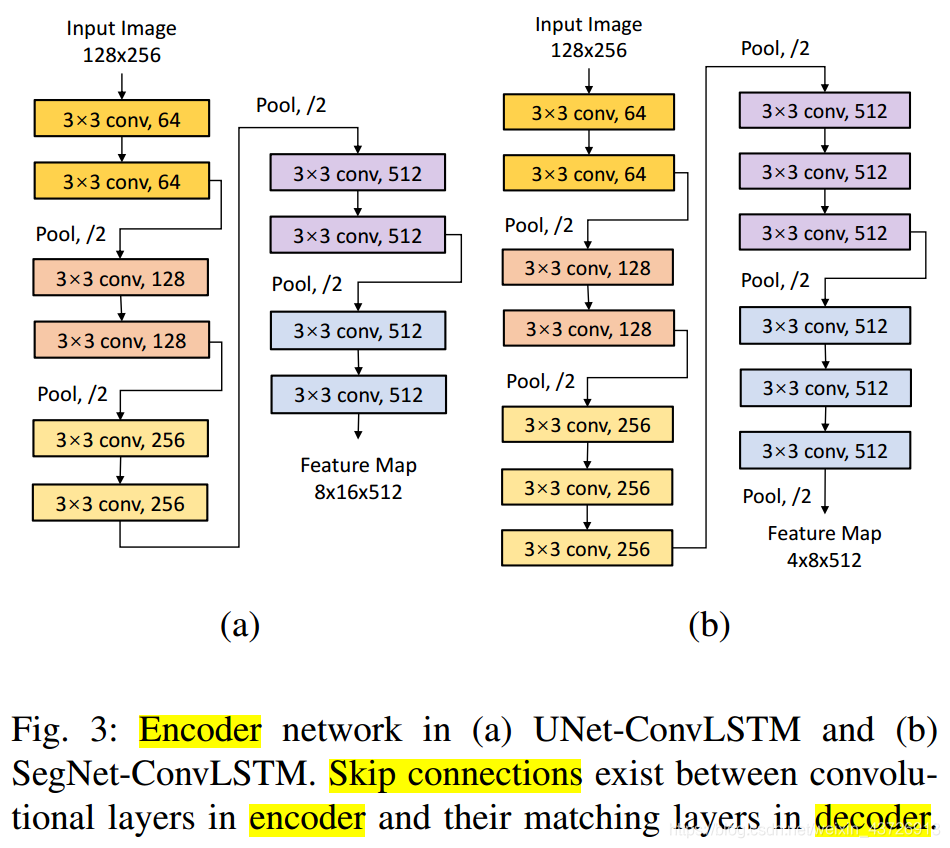
网络设计
LSTM网络
将驾驶场景的多个连续帧建模为时间序列。传统的全连接LSTM既费时又费力。 因此,我们利用卷积LSTM(ConvLSTM)。ConvLSTM用卷积运算代替了LSTM每个门中的矩阵乘法,该运算被广泛用于端对端训练和从时序数据中提取特征。
一般ConvLSTM快在时间t的激活可以表示为 各个符号的含义如下:
各个符号的含义如下:
编码器-解码器网络
训练策略
- SegNet和U-Net用在ImageNet上预训练好的权重。
- 输入连续帧的数量N=5。
- 损失函数。

- 不同阶段用不同的优化器。先是Adam,再是SGD。
实验及结果
数据集
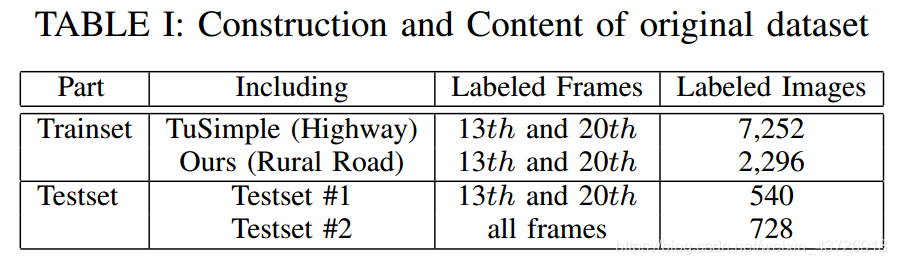
对Tusimple数据集进行了扩充(将每个序列中的第13帧图片进行了标记),同时自己采集了1148个乡村道路的序列。如表1和图5所示。
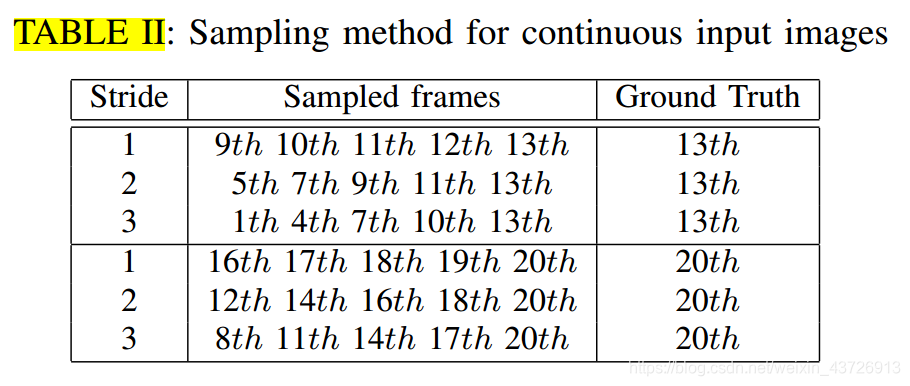
 为了进行训练,我们采样了5张连续图像和最后一帧的ground truth情况作为输入,以训练网络并确定最后一帧的车道。 基于第13帧和第20帧的地面真相标签,我们可以构建训练集。 同时,为了使所提议的网络完全适应不同的行驶速度下的车道检测,我们以三个不同的步幅(即以1、2和3帧的间隔)对输入图像进行采样。 然后,每个地面真相标签有三种采样方式,如表II所示。
为了进行训练,我们采样了5张连续图像和最后一帧的ground truth情况作为输入,以训练网络并确定最后一帧的车道。 基于第13帧和第20帧的地面真相标签,我们可以构建训练集。 同时,为了使所提议的网络完全适应不同的行驶速度下的车道检测,我们以三个不同的步幅(即以1、2和3帧的间隔)对输入图像进行采样。 然后,每个地面真相标签有三种采样方式,如表II所示。
在数据增强中,应用了旋转,翻转和裁剪操作,并生成了19,096个序列,其中包括总共38,192个标记图像以进行训练。 输入将随机更改为不同的照明情况,这有助于获得更全面的数据集。
为了进行测试,我们还对5张连续图像进行了采样,以识别最后一帧中的车道,并将其与最后一帧的地面真相进行比较。 我们构造两个完全不同的测试集-Testset#1和Testset#2。 Testset#1建立在TuSimple测试集上,用于常规测试。 测试集2由在不同情况下收集的复杂样本组成,是用于鲁棒性评估。
由于车道形状的多样性,例如缝线形车道,白色单车道和琥珀色双车道,应建立统一的标准以真实地描述这些车道。我们使用细线注释车道。然而,在语义分割任务中,模型必须从像素方向的标签中学习,这些像素方向的标签具有图像中每个对象的精确边界。因此,使用细线表示车道并不合理,因为对于车道边界而言,它们在语义上没有意义。在近距离下,车道看起来更宽,而在远处,车道看起来更窄。因此,我们将输入和标签的大小调整为较低的分辨率,以弥补不正确的边界。在我们的设计中,考虑到车道检测的目的是识别并警告车辆的车道偏离,因此不必识别车道的边界。在实验中,我们将场景图像采样为较低的分辨率,因为事实是,当图像变小时,车道会变得更细,宽度接近一个像素。图4中显示了一个示例。此外,使用较低的分辨率也可以保护模型不受消失点周围背景中复杂纹理的影响。
(输入图像的分辨率很小,所以FPS会比较快吧,不过思路好像没有问题,确实不需要太大的分辨率、太精细的标记。)

实验细节
batch size=16;epoch=100。
性能和比较
总体性能
视觉直观检查

定量分析
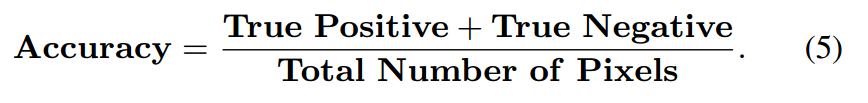
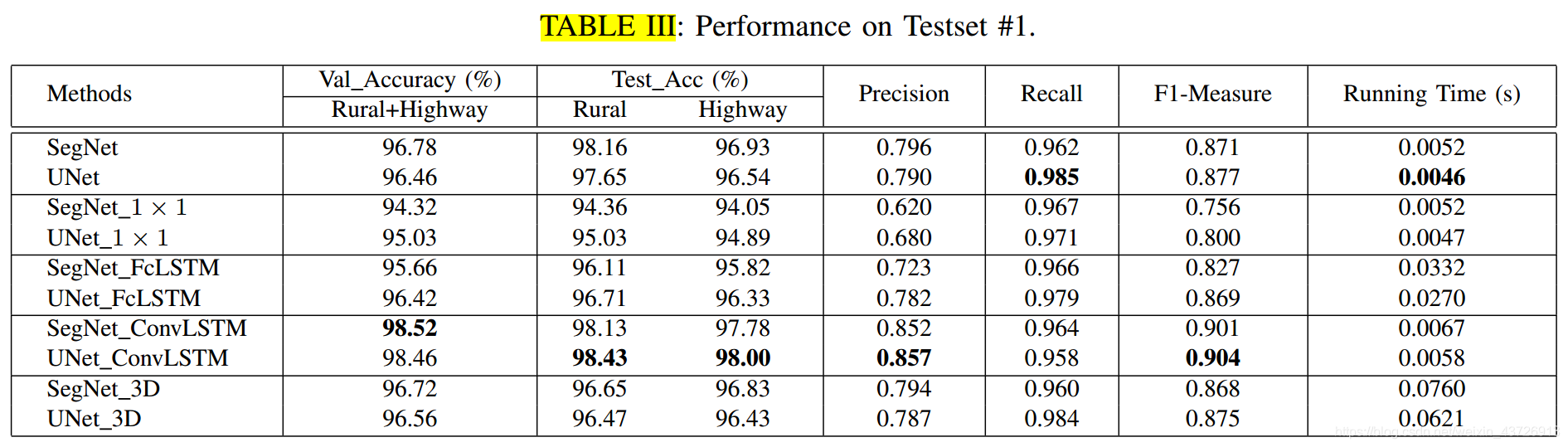
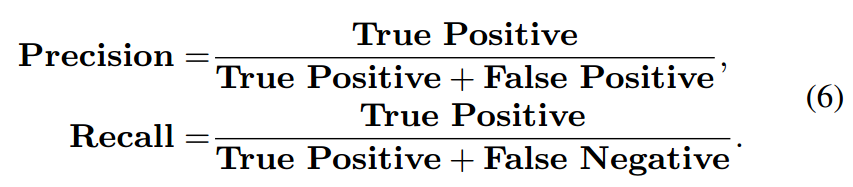
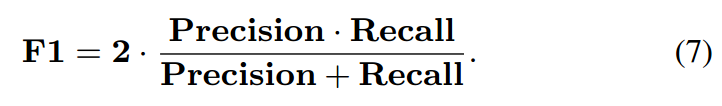
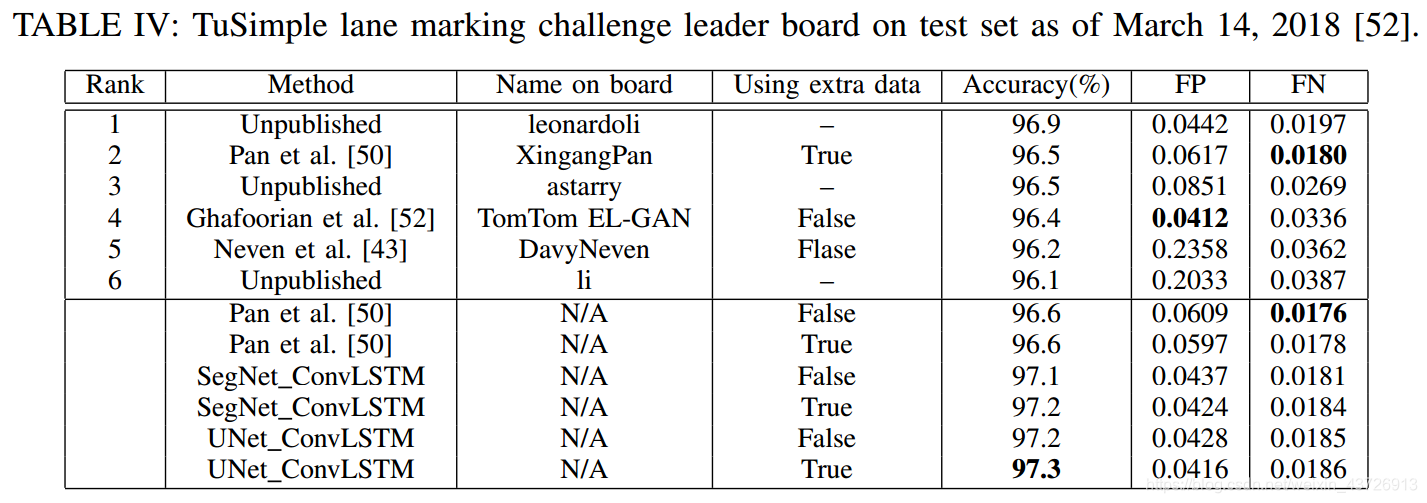
运行时间
鲁棒性能

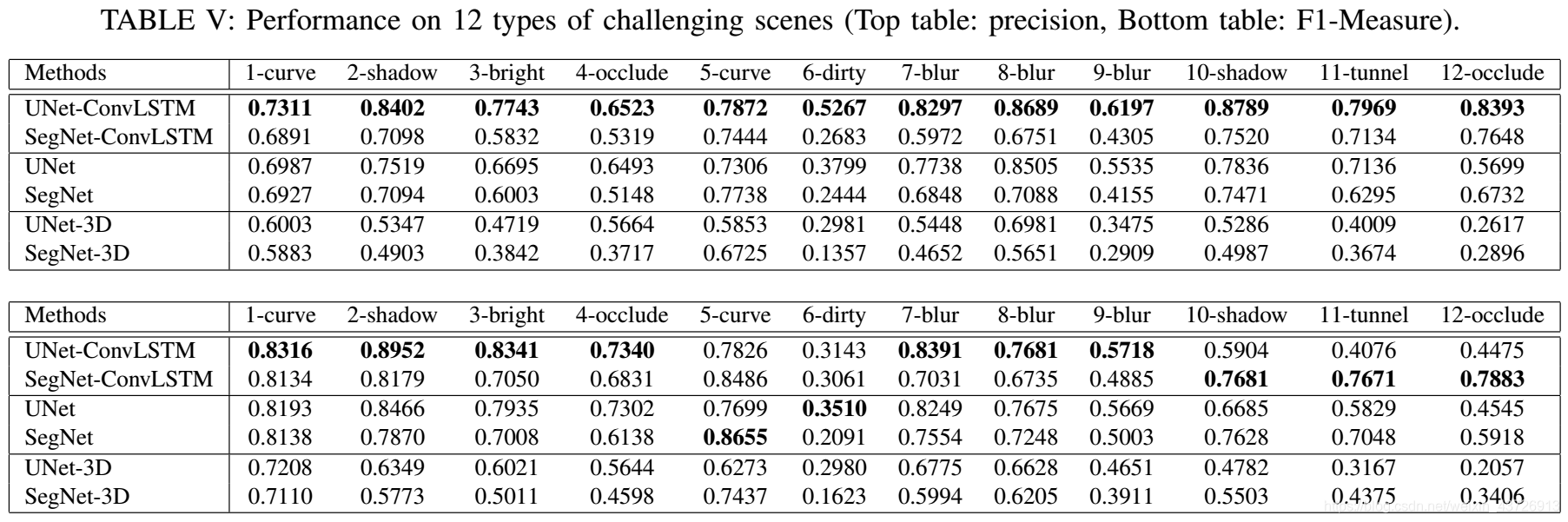

参数分析

引用信息:
Q. Zou, H. Jiang, Q. Dai, Y. Yue, L. Chen, Q. Wang, Robust Lane
Detection from Continuous Driving Scenes Using Deep Neural Networks,
IEEE Transactions on Vehicular Technology, 2019.
Github官方源码:
https://github.com/qinnzou/Robust-Lane-Detection