启动流程如下图所示:

一、名词解释
1、CoarseGrainedSchedulerBackend:由Driver启动。是一个阻塞等待coarse-grained executors来连接的SchedulerBackend。CoarseGrainedSchedulerBackend向ExecutorBackend端发送的消息主要如下:
(1)RegisteredExecutor:回复ExecutorBackend注册功能,ExecutorBackend接到后会创建Executor。
(2)LaunchTask:通知Executor启动一个task,消息中包含序列化的task信息,Executor通过该信息启动task。
2、CoarseGrainedExecutorBackend:粗粒度的ExcutorBackend进程,是Executor运行所在的进程名称。CoarseGrainedExecutorBackend在spark运行期是一个单独的进程,在Worker节点可以通过Java的jps命令查看。
3、Executor:是真正在处理Task的对象,Executor内部通过线程池的方式来完成Task的计算
4、RegisterExecutor & RegisteredExecutor:消息类。如下图所示:

二、Spark启动原理源码分析
1.Master启动
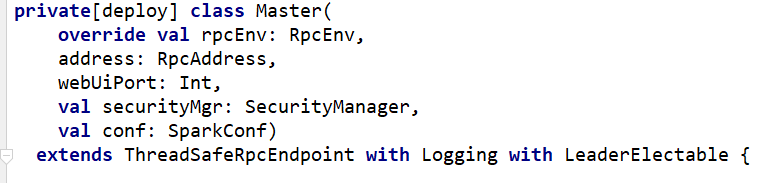
...

2.Worker启动

...

3.Master发指令给Worker启动Executor
schedule()方法在每次APP注册或者可用资源发生变化时被调用。





4.Worker接收到Master发送过来的LaunchExecutor指令通过ExecutorRunner启动另外一个线程来运行Executor
Worker.receive() 
...

ExecutorRunner启动Executor

5.启动Executor
Executor的启动,会调用fetchAndRunExecutor的方法,然后创建ProcessBuilder的命令进行启动CoarseGrainedExecutorBackend。



可以看到:
1.CoarseGrainedExecutorBackend是继承了ThreadSafeRpcEndpoint和ExecutorBackend。所以是RpcEndpoint的子类,能够和其他的Endpoint进行通信,它的生命周期同样是onStart->receive*->stop。
2.维护了两个属性,executor和Driver(是引用), executor负责运行task,driver负责和Driver通信。

请求注册RegisterExecutor向 shcedulerBackend注册。

接收到注册Executor的信息后就会创建Executor。至此CoarseGrainedExecutorBackend的启动流程就结束了。
6.Executor是真正负责Task计算的,其在实例化时会实例化一个线程池准备Task计算。由CoarseGrainedSchedulerBackend发送LanuchTask指令

创建的ThreadPool中以多线程并发执行和线程复用的方式来高效执行Spark发过来的Task
7.CoarseGrainedExecutorBackend接收到Task执行命令后,executor启动Task

会先把Task封装在TaskRunner里面

TaskRunner其实是Java中Runnerable接口的具体实现,在真正工作的时候会交给线程池中的线程去运行,此时会调用run方法来执行Task

TaskRunner在调用run方法的时候会调用Task run方法
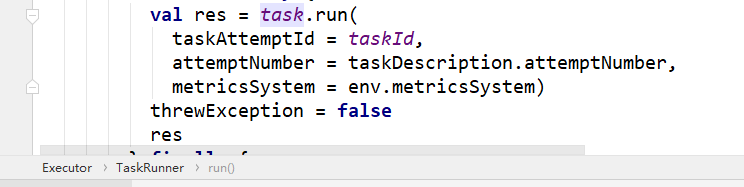
而Task#run方法内会调用runTask,而实际Task有ShuffleMapTask和ResultTask
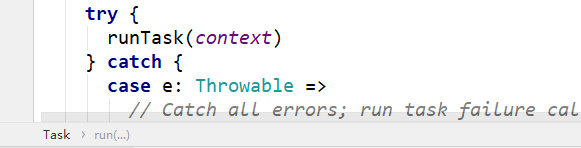



func是在调用sc.runJob()时传递的func参数。