MR Image Super-Resolution with Squeeze and Excitation Reasoning Attention Network
paper: CVPR 2021 SERAN
摘要
高分辨率(HR)磁共振(MR)图像为可靠的诊断和定量图像分析提供了更详细的信息。对于低分辨率(LR) MR图像,深度卷积神经网络(CNNs)已经显示出有前景的超分辨率(SR)能力。LR MR图像通常具有一些共同的视觉特征:重复的模式、相对简单的结构和信息量较少的背景。大多数基于CNN的SR方法对空间像素(包括背景)的处理是平等的。他们也无法对输入的整个空间敏感,这是高质量SR的关键所在。为了解决这些问题,我们提出挤压激励(squeeze and excitation)推理注意力网络(SERAN)用于精确的MR图像SR。我们从全局空间信息输入挤压注意力,获取全局描述符。这种全局描述符增强了网络关注MR图像中更多信息区域和结构的能力。我们进一步建立了全局描述符之间的关系,并提出了原始关系推理注意力(primitive relationship reasoning attention)。全局描述符通过学习的注意力进一步细化。为了充分利用聚合信息,我们使用学习的自适应注意力向量自适应地重校准特征响应。这些注意力向量选择一个全局描述子子集来补充每个空间位置,以实现精确的细节和纹理重建。我们提出了具有残差尺度的挤压和激励注意力,不仅使训练稳定,而且能灵活运用于其他基本网络。大量的实验证明了我们提出的SERAN的有效性,它在量化和视觉上明显超过了最先进的方法。
文章目录
1. 引言
高分辨率(HR)磁共振(MR)图像将提供更详细的结构和纹理,这有利于准确的诊断和定量图像分析[5]。然而,在现实世界中,HR MR图像的获得是以更长的扫描时间,更低的信噪比和更小的空间收敛为代价的[32]。图像超分辨率(SR)重建来自给定低分辨率(LR)的HR输出。它正在成为一种有前途的技术来提高MR图像的空间分辨率。
最近,深度卷积神经网络(CNN)已经显示出其对高质量SR图像的强大能力。Dong等人首先在SRCNN[7,8]中引入CNN用于图像SR,其仅具有三个卷积层。Kim等人利用VDSR中的残差学习来增加网络深度[18]。Hui等人提出了信息蒸馏网络(IDN)[15]。Zhang等人利用RDN[48]获得了更好的SR性能,充分利用了层次特征。另一方面,还提出了一些面向MR图像的SR方法。Chen等人对MR图像SR使用3D密集网络和对抗性学习[5]。
然而,那些基于深度CNN的方法要么忽略MR图像的特征,要么遭受固有的缺点。首先,MR图像通常具有重复的结构模式,并且比自然图像相对简单。非常宽和深的网络(例如,EDSR[26])可能会遇到过拟合问题。其次,MR图像通常包含大的背景区域,其信息远不如目标结构区域。然而,大多数先前基于CNN的方法均等地处理图像的所有空间像素,他们无法区分目标区域和背景区域,阻碍了表示能力。第三,大多数以前基于CNN的SR方法依赖于卷积运算,卷积运算侧重于局部邻域,无法捕获输入的整个方面。然而,对于MR图像SR,重建更多信息区域的全局特征是非常重要的。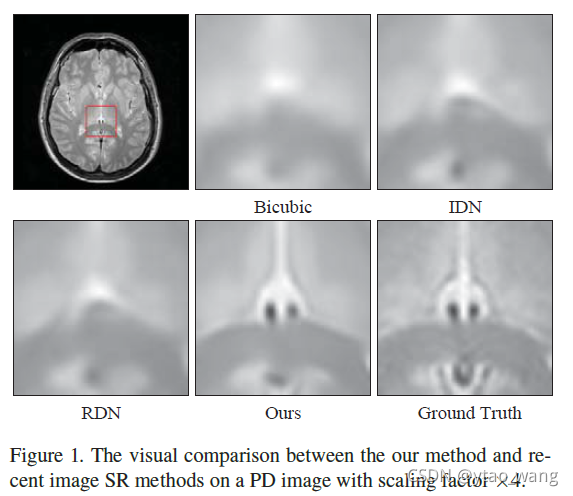
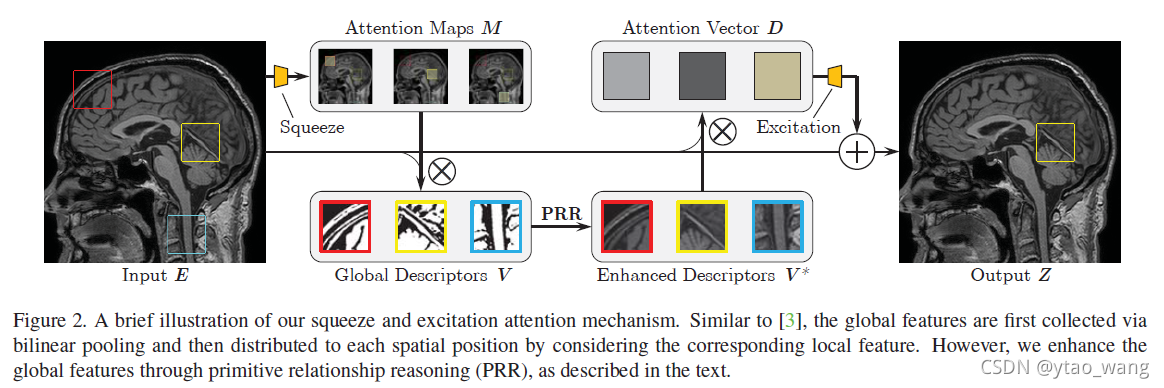
为了解决这些问题和局限性,我们提出了挤压和激励注意力网络(SERAN)来获得准确的MR图像SR(见图1)。如图2所示,我们使用二阶注意力池化操作将全局空间信息压缩为全局描述,它允许模型专注于MR图像中更具信息性的区域和结构。然后,我们建立基元(primitives)之间的关系,并应用图卷积网络(GCN)进行推理并获得基元关系推理注意力。我们用学习到的注意力来改进全局描述符。为了充分利用聚合信息,使用学习到的注意力向量自适应地重新校准特征响应。这些注意向量选择全局描述符的子集以补充每个空间位置以获得准确的细节和纹理重建。与最近的方法相比,实验结果证明了我们的SERAN的有效性
总之,这项工作的主要贡献是:
- 为了实现快速、准确的磁共振图像超分辨率,提出了挤压和激励推理注意网络(SERAN)。据我们所知,这是第一个研究语义推理注意MR图像SR的工作。
- 我们建议从功能中收集全局视觉基元。我们进一步提出原始关系推理注意力进行细化。然后,我们自适应地将全局视觉基元分配给局部特征。
- 我们在基准数据集上进行了大量实验,证明了我们的SERAN的有效性。与其他最先进的图像SR方法相比,我们的SERAN实现了显著的性能增益。
2. 相关工作
2.1 MR图像超分辨率
图像SR作为一种后处理方法,在许多与MR图像分析相关的工作中都得到了研究,如扩散MRI[33,36]、结构MRI[27,34]、光谱MRI[16,17]等。在早期,图像SR到MR图像的任务主要集中在传统的多帧图像SR上,然而,当我们试图从多个退化的LR对应图像中重建一个HR图像时,常常需要对这些LR图像进行校准和融合,这一过程本身就是一项非常具有挑战性的任务。最近,基于深度学习[23]的图像SR方法在自然图像上表现出了优越的性能[8,18,26,47,48],这推动了深度学习技术在MR图像SR任务中的应用[6,31,43,49]。然而,一些基于CNN的图像SR方法由于模型尺寸大,在资源有限的情况下不适合实际的MRI场景,因而获得了理想的效果。在这项工作中,我们的挤励推理注意网络本质上是一个轻量级的模型,更便于实际部署和临床应用。
2.2 注意力机制
注意机制赋予神经网络自适应地为信息输入特征分配资源的能力,这有利于充分利用网络表示能力和提高模型性能[13]。因此,近年来它被广泛嵌入到神经网络中用于各种机器学习任务,包括自然语言处理(NLP)[28,39]、图像识别[1,9,40]和图像捕获[44]等。低级计算机视觉应用,如图像SR,还有一些关于将注意机制引入神经网络的工作[14,48]。然而,通过考虑MR图像的特殊特征:重复模式、相对简单的结构和较少信息的背景,很少有工作来研究注意力对单个MR图像SR任务的作用。如果网络可以自适应地将计算资源分配给MR图像中的信息部分,则有希望通过适度的模型参数来提高性能。
2.3 语义推理
人工智能领域的研究人员最初将关系推理作为符号方法进行研究[29]。通过运用数学和逻辑语言,他们首先定义了抽象符号之间的关系。然后,他们使用反演和演绎进行推理[12]。但是,为了使这些方法实用,这些符号应首先接地气[10]。后来,利用统计学习提取有用的模式,目前的方法(例如,路径排序算法[22])转向在结构化知识基础上进行关系推理。最近,基于图的方法已经显示出关系推理的性能可能性。随着卷积神经网络在计算机视觉领域的巨大成功[11],图卷积网络(GCN)[20]被提出用于半监督分类,其中卷积网络用于处理图形结构中的数据。GCN被用来捕获视频识别应用中对象之间的关系[41]。为了改善新场景和新对象的语义导航,[45]利用GCN将先验知识编码为深度强化学习框架。[4,24]将GCN纳入视觉编码设计,并学习关系增强功能,端到端地完成感兴趣的任务,如图像分类和图像文本匹配。在图像捕获框架下,[46]使用视觉基因组数据集[21]来训练视觉关系检测模型,其中检测到的关系信息用基于GCN的图像编码器编码。在本文中,我们还介绍了图卷积的推理优势,通过考虑视觉基元之间的语义关系来增强视觉表示。我们将推理能力纳入注意学习阶段,以提高图像SR模型的能力。
3. SERAN
3.1 动机
如上所述,与自然图像不同,MR图像具有其特定特征:重复的视觉模式,相对简单的结构和较少信息的背景。需要一种更可区分的机制来处理这些情况。另一方面,通过关注更多信息通道[13]或空间位置[3],已经证明注意力机制对于高级视觉任务是有效的。在这里,我们进一步研究如何关注MR图像中信息量更大的视觉区域和模式。
3.2 挤压注意力:信息集合
我们在图3中说明了全局信息集合。给定一个输入特征E ∈ R C × H × W E \in \mathbb{R}^{C \times H \times W}E∈RC×H×W,我们的目标是获得它相对应的指导注意力Z ∈ R C × H × W Z \in \mathbb{R}^{C \times H \times W}Z∈RC×H×W,这里,C是通道数,H和W分别表示特征的高和宽。为简单起见,我们已将特征reshape到二维空间。
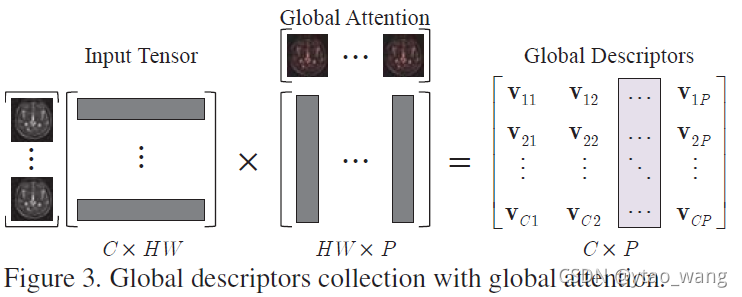
我们将输入特征重写为E = [ e 1 , ⋯ , e H W ] E = [\bold e_1, \cdots, \bold e_{HW}]E=[e1,⋯,eHW]。我们知道主要的视觉基元来自MR特征中信息量更大的视觉区域和模式。为了实现这些主要的视觉基元,我们倾向于考虑所有输入特征点。在数学上,这样的过程可以写成:

这里v i ∈ R C × 1 \bold v_i \in \mathbb{R}^{C \times 1}vi∈RC×1是一个视觉基元,m i ∈ R 1 × H W \bold m_i \in \mathbb{R}^{1 \times HW}mi∈R1×HW是全局注意力向量。我们可以看到通过考虑由全局描述符m i \bold m_imi加权的所有局部特征来计算每个基元v i \bold v_ivi。假设我们的目标是寻找P个视觉基元,我们必须使用P个全局描述符,可以表示为M = [ m 1 , ⋯ , m P ] ∈ R P × H × W M = [\bold m_1, \cdots, \bold m_P] \in \mathbb{R}^{P \times H \times W}M=[m1,⋯,mP]∈RP×H×W。然后,全局信息集合可以表示为:

我们可以看到(2)式不仅学习一组视觉基元V = [ v 1 , ⋯ , v P ] V = [\bold v_1, \cdots, \bold v_P]V=[v1,⋯,vP],而且还获得二阶统计量。这种二阶注意力池化操作可以捕获更复杂的远距离特征相互依赖性[3]。在实现中,我们必须强制∑ j = 1 H W m i j = 1 \sum_{j=1}^{HW} \bold m_{ij}=1∑j=1HWmij=1,这可以通过softmax函数来实现。即,具有矩阵reshape的M = s o f t m a x ( θ ( E ; W θ ) ) M=softmax(\theta(E;W_{\theta}))M=softmax(θ(E;Wθ)),其中W θ W_{\theta}Wθ表示该卷积层的可训练参数。
3.2 基元相关性推理注意力
在获得视觉原始集V之后,我们希望通过考虑每个视觉原始集vi之间的关系来进一步增强它。在深度学习的最新发展中,已经研究了视觉推理[2,25,35,50]来建模和挖掘视觉组件之间的关系。在这里,我们的灵感来自于构建视觉基元之间的关系推理模型。具体而言,我们首先将视觉基元嵌入到具有权重参数Wφ和Wφ的两个嵌入空间中。然后,我们通过计算成对亲和力来建立这种关系:

其中φ ( v i ; W φ ) φ(vi;Wφ)φ(vi;Wφ)和φ ( v j ; W φ ) φ(vj;Wφ)φ(vj;Wφ)是两个嵌入。我们使用等式(3)在每两个v i \bold v_ivi和v j \bold v_jvj获得视觉基元之间的关系,从而得到全连接关系图。
让我们将图表示为G ( V , R ) G(V,R)G(V,R),其中V VV是图节点集合(即视觉基元),R RR是图边集合(即基元关系)。基于等式(3),我们通过测量每个视觉基元的亲和边来获得亲和矩阵R RR。具有较大亲和力得分的图边意味着相应的视觉基元对与强语义关系高度相关。
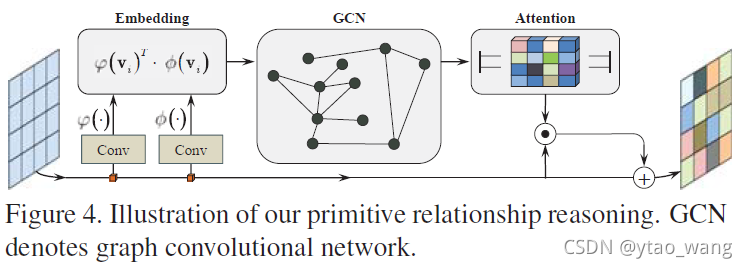
然后,基于上述连通图,利用图卷积网络(GCN)进行推理[20]。对于每个节点,其邻居由图关系定义,并且可以用于计算每个节点的响应。与之前的一些工作[4]不同,后者将推理结果作为输入的增强。在这里,我们通过应用S形激活函数来实现推理注意。然后引入残差学习来连接原始输入,如下所示

其中σ \sigmaσ是S形激活函数。R是P×P亲和矩阵。W g W_gWg是尺寸为C × C C \times CC×C的GCN层的权重矩阵。对于残差结构,其权重矩阵为W r W_rWr。⊙ \odot⊙表示逐元素乘法。我们在图4中说明了这样的推理过程。通过使用基元关系推理注意力,我们获得了增强的视觉基元,称为全局特征描述符。
3.3 激励注意力:特征分配
收集全局特征描述符后,我们希望将它们分发到原始特征的每个位置。这将有助于我们更好地利用与计算的二阶统计量的复杂关系,并补偿丢失的信息以获得更好的MR图像重建。
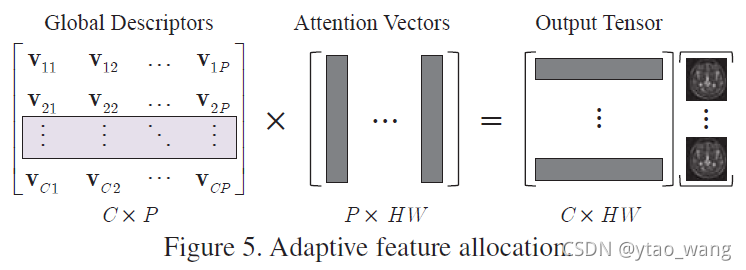
在图5中,我们可以看到原始特征的每个位置都有其对全局描述符的特定需求。我们根据学习的注意向量d i \bold d_idi在每个位置自适应地分配全局描述符V VV。这意味着每个位置都可以自适应地选择互补的视觉原语。这样的程序可以通过下式实现:

哪里z i ∈ R C × 1 \bold z_i \in \mathbb{R}^{C \times 1}zi∈RC×1是第i ii列的Z ZZ和为软注意向量。对于Z ZZ中的每个位置,使用特定的软注意向量来自适应地从V VV中选择互补特征。它将导致软注意矩阵D = [ d 1 , ⋯ , d H W ] D = [\bold d_1, \cdots, \bold d_{HW}]D=[d1,⋯,dHW],其中∑ j = 1 H W d i j = 1 \sum_{j=1}^{HW} \bold d_{ij}=1∑j=1HWdij=1。我们应用softmax函数通过参数Wρ的D = s o f t m a x ( ρ ( E ; ρ ) ) D=softmax(\rho(E;\rho))D=softmax(ρ(E;ρ))实现它。自适应分布最终可以表示为:

作为补充组成部分。我们可以看到注意力指导影响目标特征Z ZZ。具体而言,Z ZZ是通过使用来自主要视觉原语池的自适应互补特征获得的。
3.5 SERAB
在获得注意力引导的补充特征Z之后,我们希望将其编码回输入。广泛使用的做法是剩余学习[11]。在这里,我们进一步采用因子α \alphaα的残差缩放[38]来获得最终的特征输出。这个过程可以写成:

这导致了图6所示的挤压和激发推理注意块(SERAB)。
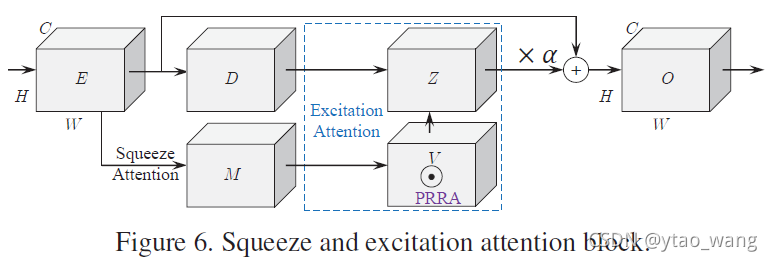
它是基于两个原因制定的。首先,这里直接使用残差学习(例如,α = 1 \alpha =1α=1)将使训练过程在数值上不稳定。其次,残差连接允许我们将SEAB插入任何预训练网络,而不会过多地影响其初始行为(例如,α → 0 \alpha \rightarrow 0α→0). 随着SEAB的使用,即使有限的感受野大小,随后的卷积层也可以感知整个空间。SEAB允许网络专注于更多信息的视觉特征,并实现更好的MR图像SR重建质量。
4. 实验结果
我们首先简要介绍数据集和模型实现的细节。然后我们研究和分析我们的方法SERAN的结构。接下来,将几种最近的SR方法与所提出的模型进行比较。对于定量评估指标,我们采用PSNR和结构相似性指数度量(SSIM)[42]来评估SR质量。我们还提供模型大小和运行时间比较。
4.1 数据集
本文中使用的数据集与[49]相同,最初来自IXI数据集。数据集中包括三种类型的MR图像(即PD,T1和T2)。他们每个分别有500、70和6 MR volumes用于模型训练,测试和快速验证。每个3D体积的大小被切割为240×240×96(高度×宽度×深度),其中96表示MR体积中的切片数量(沿着成像平面方向)。请注意,数据集包含两种图像退化,但由于空间有限,本文仅研究典型的双三次退化。由于所提出的方法的2D性质,我们获得500×96=48000个2D训练样本。
4.2 执行细节
在实施我们提出的SERAN时,我们使用残差网络[26](40个残差块)作为骨干。具体来说,我们在元素加法长跳过连接之前插入SEAB。我们将α \alphaα设置为0.01,使网络能够稳定并逐步学习注意力指导。我们将所有卷积层的大小设置为3×3,除了SEAB中的内核大小为1×1。每个卷积层有64个滤波器,除了输入层和输出层有1个通道。对于核为3×3的卷积层,我们使用零填充策略来保持大小固定。在培训阶段,批量为96。LR patch size的输入大小为32×32。我们的网络使用ADAM optimizer[19]进行训练,β 1 = 0.9 β_1=0.9β1=0.9,β 2 = 0.999 β_2=0.999β2=0.999,和KaTeX parse error: Undefined control sequence: \upepsilon at position 1: \̲u̲p̲e̲p̲s̲i̲l̲o̲n̲ ̲= 10^{-8}. 学习率初始化为1 0 − 4 10^{-4}10−4并每200个时代减少一半。我们使用PyTorch[30]来实现Titan Xp GPU的模型。
4.3 消融实验
在这里,我们调查了我们提出的挤压和激发推理注意网络(SERAN)的每个关键组件的影响。在SERAN中,挤压和激发推理注意力块(SERAB)起着重要作用。所以我们首先调查SERAB的有效性。然后,我们进一步探讨SERAB的插入位置和数量将如何影响性能。我们用比例因子2×报告PD,T1和T2的性能。
4.3.1 SERAB的影响
在SERAB中,我们想展示我们的挤压和激励注意模块的有效性。我们将这种情况表示为SEAB,即不使用原始关系推理(PRR)。然后我们探讨残差缩放(RS)如何影响网络。最后,我们展示了原始关系推理如何进一步提高网络能力。
Effect of SEAB. 通过删除PPR,我们提出的SERAB可以简化为SEAB。我们通过使用残差网络[26](40个残差块)作为基线来研究具有和不具有残差缩放(RS)的SEAB的影响。如Tab1,在基线中引入SEAB(w/o RS)将非常明显地提高网络性能。这样的观察表明,来自MR图像的深度特征中存在一些冗余信息。在收集全局信息(即挤压注意力)之后,我们为MR深度特征提取更紧凑的全局描述符。然后,将全局描述符自适应地分配给每个局部特征,从而产生更强的网络表示能力。此外,如此强大的能力不会受到使用RS的严重影响。
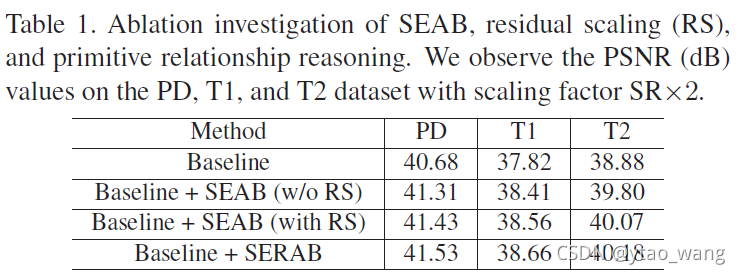
Effect of residual scaling (RS) 在将SEAB引入基线之后,我们还发现RS可以进一步帮助追求更好的性能。我们可以看到残差缩放策略在没有额外模型参数的情况下进一步提高了性能。更重要的是,正如我们在3.5节中所描述的,我们的SERAB可以很容易地集成到具有残差缩放的其他基线中。
Effect of PRR当我们进一步将我们提出的原始关系推理(PRR)引入SEAB时,我们实现了它的增强版本,命名为SERAB。如Tab1所示,PRR将在每个数据集中进一步实现另一个性能改进(约0.1dB)。这种改进表明视觉原语中仍然存在一些冗余信息。基于完全连通图,我们应用GCN进行推理,这将进一步研究视觉原语之间的潜在关系。因此,我们实现了更强的视觉原语和更好的网络性能。
4.3.2 SERAB位置和数量的影响
在证明了上述SERAB的有效性之后,我们进一步研究了SERAB的位置和数量如何影响网络性能。我们仍然使用PD,T1,T2作为缩放因子2×的测试集。我们首先将基线中的第1、20和40个残差块(RB)分别命名为低、中和高。我们将SERAB插入这三个位置,表2显示了不同的组合的结果。
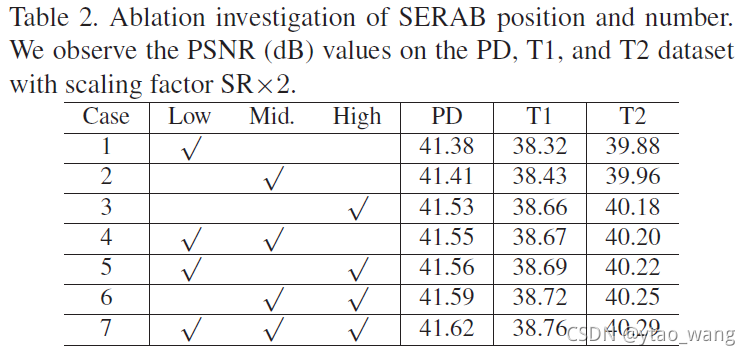
Effect of SERAB position 对于Tab2中的情况1\2和3,我们可以了解到更高层次的血清会表现更好。主要原因可能是较高级别的特征具有较大的感受野尺寸,导致整个特征的感测范围较大。此外,更深的功能可能更紧凑,冗余信息更少,这进一步帮助SERAB学习更有效的视觉启动和实现更高的代表性。
Effect of SERAB number 我们进一步展示了SERAB的数量如何影响网络性能。更多的SERAB会获得更好的表现。更高级别的SERAB比低级别的SERAB表现更好。与单个高级SERAB相比,更多SERAB的性能增益不是很大。但是,使用更多的SERAB也会消耗更多的GPU内存和运行时间。结果,我们通过实验在高RB中来报告结果。
4.4 与其他方法的对比
我们将所提出的SERAN模型与几种最先进的SR技术进行了比较,范围从轻质SRCNN[8],VDSR[18],IDN[15]到大规模RDN[48]和CSN[49],通过定量和定性评估。一些定量结果直接引用[49],其中比较的方法使用相同的评估指标,培训和测试数据集。
4.4.1 定量对比
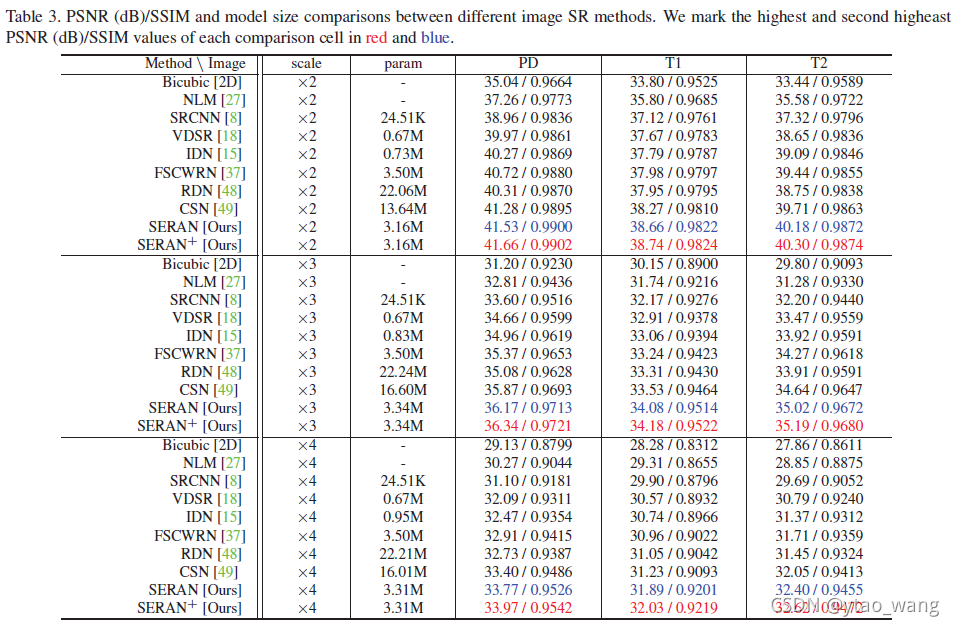
表3显示了比较方法的定量结果。SEARN代表我们的模型直接获得的结果,SERAN+表示应用几何自集成[26]技术。可以看到所提出的SERAN在很大程度上获得了比其他最先进方法明显更高的性能,即使没有几何自集成,也能在所有类型的MR图像和所有SR缩放因子上获得最佳的SR性能。更重要的是,我们的方法利用中等尺度的模型参数并提供更准确的SR结果,这意味着我们的SERAN通过充分考虑MR图像的特殊性在性能和模型大小之间实现了更好的权衡。因此,我们的SERAN模型支持快速模型推理和方便的实际部署,表明它是MR图像的高精度SR方法。而且,我们的方法在现实世界中可能是非常实用的方法。
4.4.2 可视化对比
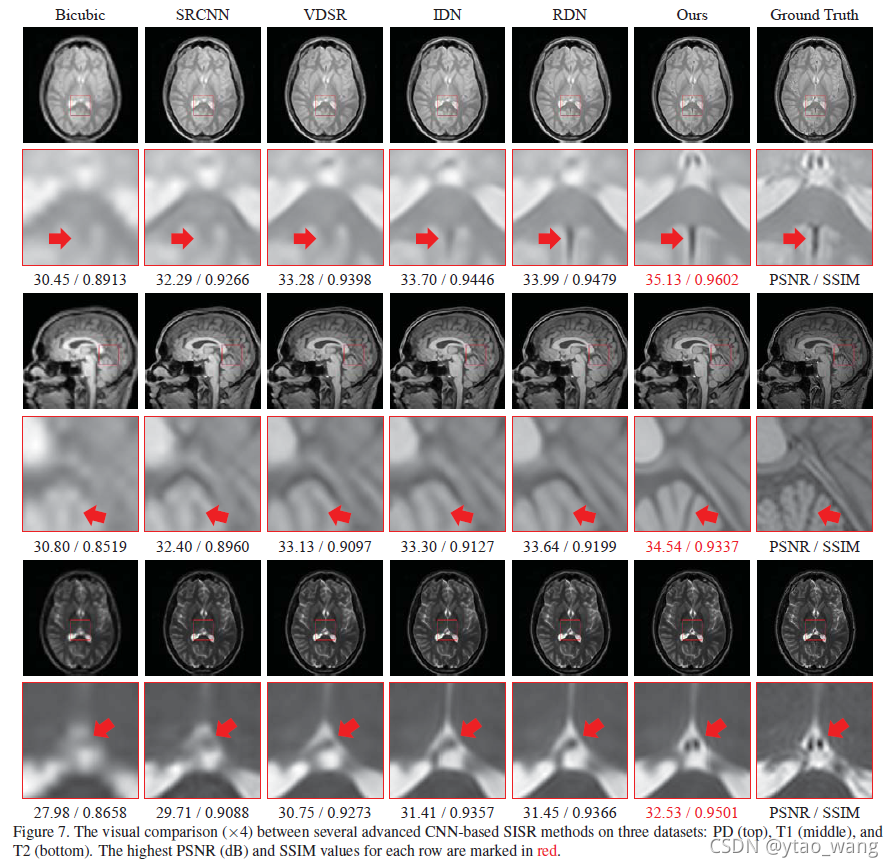
图7显示了Tab中比较方法的视觉效果。如图3所示,在三个数据集上:分别具有比例因子×4的PD(顶部),T1(中间)和T2(底部)图像。可以看出,所提出的SERAN模型在所有图像类型上显示出优于其他方法的显着可见优势。例如,在PD图像中,有一个由红色箭头指示的黑色区域。Bicubic,SRCNN[8],甚至VDSR[18]的结果几乎完全丧失了这种结构。虽然可以在IDN[15]和RDN[48]的结果中观察到,但我们的模型提供了更清晰的指示和更好的地面实况近似。从T1和T2图像的结果也可以观察到类似的比较,这说明了我们提出的模型在MR图像超分辨率任务中的优越性。
4.4.3 in-vivo图像的性能
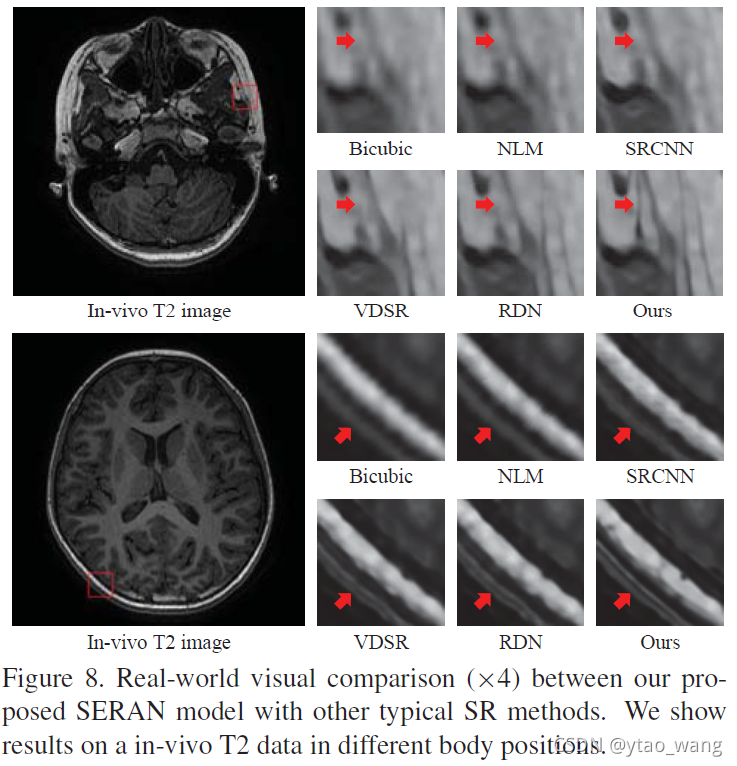
我们还对不同人体位置的体内MR图像进行SR实验,以验证所提出模型的实用性。图8显示了在具有SR×4的真实世界T2图像上的几种SR方法(包括NLM[27],SRCNN[8],VDSR[18]和RDN[48])之间的视觉比较。可以看出,我们的模型呈现出更清晰的结果,其中包含一些在其他方法的结果中找不到的细节,例如由红色箭头指示的深色接缝。该比较证明了所提出的SERAN模型在处理具有特定特征的MR图像中的有效性。
4.4.4 模型大小分析
在Tab3,我们给出了每种基于CNN的SR方法的模型大小。我们来分析模型大小和性能的比较。我们可以看到,一些大型模型(例如RDN)可能不适合MR图像,即使它们对于自然图像SR表现非常好。尽管我们的SERAN不是最小的网络,但它的参数远小于RDN[48]。更重要的是,我们的SERAN和SERAN+为每个数据集和比例因子获得最高性能,在SR性能和模型大小之间显示出更好的折衷。这些比较还表明,具有挤压注意力的全局描述符有助于抵消相对较小网络的有限感受野大小。因此,我们的方法使用更小的模型参数获得更好的结果。
4.4.5 运行时间对比
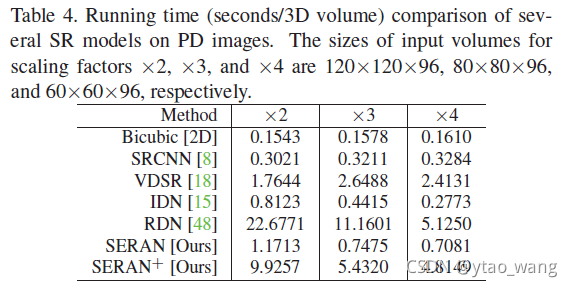
Tab4展示了几种典型方法在不同比例因子方面的执行效率比较。我们可以看到,我们的SERAN获得了与其他领先的基于CNN的轻量级模型相当的运行时间。即使我们使用自集成[26]来进一步改善SERAN并获得SERAN+,运行时间也小于RDN[48]。此外,当我们将在表3中性能与运行时间一起考虑时,我们可以看到我们提出的SERAN在性能和运行时间之间取得了很好的平衡。
总结
注意机制可以提高深度CNN在低级计算机视觉任务中的性能,MR图像共享其特定的视觉特征,在此基础上我们提出了SERAN模型并将其应用于MR图像SR任务。与分离通道或空间注意不同,我们提供了空间位置的注意事项分布,并将其与学习的全局描述符相结合。考虑到MR图像的重复结构和简单分布,我们的模型可以更有效,更准确地处理MR图像SR任务。我们通过使用残差缩放来构建基本的挤压和激励注意力块(SEAB),这有助于稳定训练。为了更好地利用学习的全局描述符(即视觉基元)之间的关系,我们进一步在视觉基元之间建立关系图。基于关系图,我们利用GCN进行推理过程,产生基元关系推理注意力。这种学习的注意力可以用来进一步提高视觉基元的表示能力。我们证明了我们SERAN中每个所提模块的有效性。进行广泛的定量实验(例如,PSNR/SSIM,模型大小和运行时间)和定性实验证明了我们提出的SERAN方法优于其他领先的基于CNN的图像SR方法。
助于稳定训练。为了更好地利用学习的全局描述符(即视觉基元)之间的关系,我们进一步在视觉基元之间建立关系图。基于关系图,我们利用GCN进行推理过程,产生基元关系推理注意力。这种学习的注意力可以用来进一步提高视觉基元的表示能力。我们证明了我们SERAN中每个所提模块的有效性。进行广泛的定量实验(例如,PSNR/SSIM,模型大小和运行时间)和定性实验证明了我们提出的SERAN方法优于其他领先的基于CNN的图像SR方法。