参考博客
沉淀,再出发——在Hadoop集群的基础上搭建Spark - 精心出精品 - 博客园 (cnblogs.com)
博客上说明Hadoop伪分布也行
一、前提
1.java环境,jdk1.8及其以上,或者open角度看8及其以上,以便scala的安装
2.安装ssh(远程登陆服务器)这里我用xshell
3.Hadoop集群(这里在伪分布下实现)
4.安装scala根据博客安装的是2.11.8
https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz
5.安装spark根据博客安装的是2.3.0
https://archive.apache.org/dist/spark/spark-2.3.0/spark-2.3.0-bin-without-hadoop.tgz
二、安装
一、安装scala
通过xftp等文件传送工具将下载的scala与spark传送至虚拟机下,解压、配置环境变量

1.解压与移动(这里需要看你想装在那个路径下等下环境变量的配置要一样)
1.解压
tar -zxf scala-2.11.8.tgz
2.移动
mv scala-2.11.8 ../scala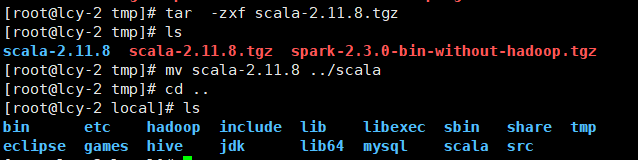
2.添加环境变量(SCALA_HOME对应的是你的安装路径)
1.打开配置环境变量的文件
vim /etc/profile
2.更新使环境变量生效
source /etc/profile

这里环境变量生效后,可以测试一下scala(因为我这里是jdk1.8.0所以没有原博客中提出的细节)

二、安装spark
退出scala(一定要有冒号)
:quit下载的是最新版本对于Hadoop的任何版本都兼容。
1.解压与移动改名
1.解压
tar -zxf spark-2.3.0-bin-without-hadoop.tgz
2.移动
mv spark-2.3.0-bin-without-hadoop ../spark
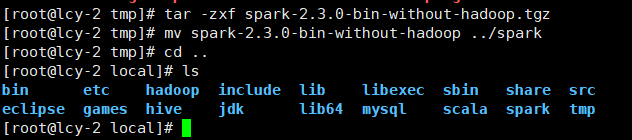
2.添加环境变量(这里不在赘述)

3.在原博客中的吐槽感同身受啊,最重要的配置来了
在spark的安装路径下的环境变量(/usr/local/spark/conf)与Hadoop进行库文件的关联
1.重命名
mv spark-env.sh.template spark-env.sh
2.打开文件spark-env.sh(在最后添加声明,对应的路径为Hadoop安装路径bin/hadoop)
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath) 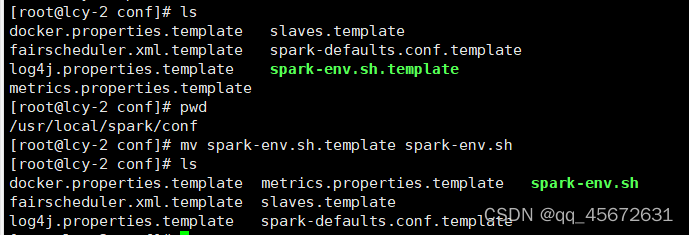
真的慢
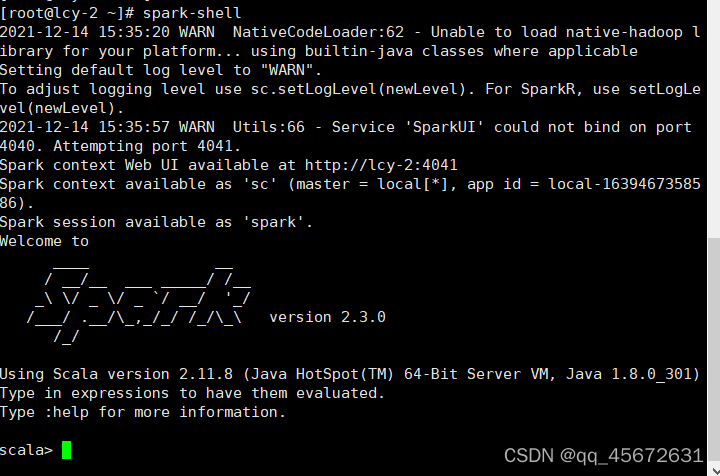
此时,我们的spark才算搭建完成,当然了我们还可以有更多的配置,比如说我们在刚刚的文件spark-env.sh中,我们还可以加入很多的描述信息和控制信息,在conf目录下还有很多的模板,我们都可以重命名之后拿来使用,这样我们的集群就更加有生命力了。在这里我们暂时不讨论spark和hadoop结合来运行程序,先让我们看一下spark在单机上的运行水平。
三、使用spark基本命令(原博主是按照spark官网的)
3.1创建数据集
Datasets can be created from Hadoop InputFormats (such as HDFS files) or by transforming other Datasets.
可以从Hadoop输入格式(如HDFS文件)或通过转换其他数据集来创建数据集
Let’s make a new Dataset from the text of the README file in the Spark source directory。
让我们从Spark源目录中的自述文件文本创建一个新的数据集这里不从hdfs上读取,而是直接从本地文件系统中读取,因此需要使用file协议
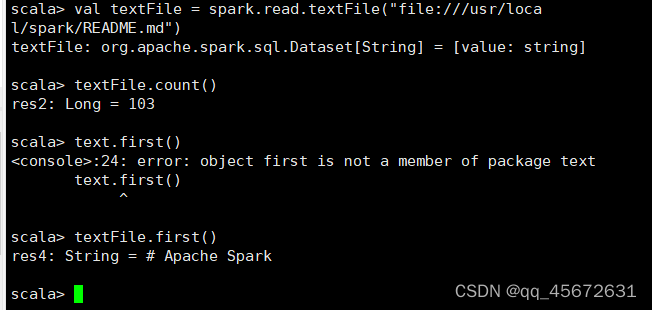
val textFile = spark.read.textFile("file:///usr/local/spark/README.md")
textFile.count()
textFile.first() // First item in this Dataset很慢一个命令差不多半分钟左右才有反应
可以通过http://ip:4040(ip地址或主机名)
我这没反应,有兴趣的可以
就到这里了,集群搭建的可以参考原博客虽然原博客实在unbantu上的