1.Pandas支持读取的文件类型
| 数据类型 | 说明 | Pandas读取方法 |
|---|---|---|
| csv、tsv、txt | 逗号分隔、tab分割的纯文本文件 | pd.read_csv |
| excel | 微软xls或者xlsx文件 | pd.read_excel |
| mysql | 关系型数据库 | pd.read_sql |
2.文件读取
1.读取纯文本文件
- 读取
csv,使用默认的标题行、逗号分隔符import pandas as pd # 读取文件 fpath = './data/ratings.csv' ratings = pd.read_csv(fpath)fpath:文件路径sep:数据分隔符header:names:某些数据没有表头,可以自定义列名,数组类型
- 查看前几行数据,默认前5行
ratings.head() - 查看数据形状
ratings.shape - 查看列索引
ratings.columns - 查看行索引
ratings.index - 查看每列的数据类型
ratings.dtypes
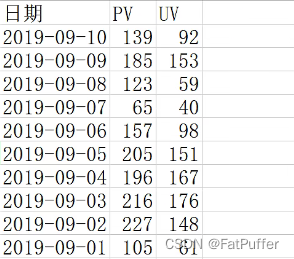
2.读取excel文件
import pandas as pd
fpath = './data/access_pvuv.xlsx'
ratings = pd.read_excel(fpath)
3.读取mysql
import pymysql
import pandas as pd
conn = pymysql.connect(
host="127.0.0.1",
user="admin",
password="password",
database="test",
charset="utf8"
)
mysql_page = pd.read_sql("select * from crazyant_pvuv", conn=conn)
3.Pandas数据结构
1.DataFrame:二维数据,整个表格,多行多列)
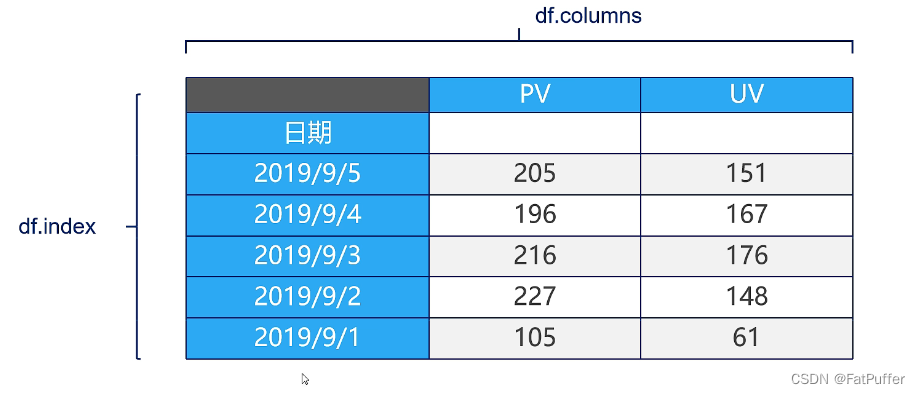
1.定义
DataFrame是一个表格型的数据结构- 每列可以是不同的值类型(数值、字符串、布尔值等)
- 既有行索引
index,也有列索引columns - 可以被看作是由
Series组成的字典
2.创建DataFrame常用方法
1.读取纯文本文件
2.读取
excel文件3.读取
mysql数据库4.从数据源创建
import pandas as pd data = { "state": ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'], "year": [2000, 2001, 2002, 2001, 2002], "pop": [1.5, 1.7, 3.6, 2.4, 2.9] } df = pd.DataFrame(data)state year pop 0 Ohio 2000 1.5 1 Ohio 2001 1.7 2 Ohio 2002 3.6 3 Nevada 2001 2.4 4 Nevada 2002 2.9
2.Series:一维数据,一行或一列
1.定义
Series是一种类似于一维数组的对象,类似于python的字典,它由一组数据(可以是不同数据类型)以及一组与之相关的数据标签(即索引)组成
2.创建Series常用方法
1.使用列表数据生成一个最简单的
Seriesimport pandas as pd s1 = pd.Series([1, 'a', 5, True, [1]])0 1 1 a 2 5 3 True 4 [1] dtype: object- 获取索引
s1.index # RangeIndex(start=0, stop=5, step=1) - 获取数据
s1.values # array([1, 'a', 5, True, list([1])], dtype=object)
- 获取索引
2.创建一个具有标签索引的
Seriesimport pandas as pd s2 = pd.Series([1, 'a', 5, True, [1]], index=['a', 'b', 'c', 'd', 'e'])a 1 b a c 5 d True e [1] dtype: object- 根据索引取单个值
s2['a'] # 1 type(s2['a']) # int - 根据索引取多个值
s2[['a', 'b']] ''' a 1 b a dtype: object ''' type(s2[['a', 'b']]) # pandas.core.series.Series
- 根据索引取单个值
2.使用Python字典创建
Seriesimport pandas as pd sdata = {'Ohio': 35000, 'Texas': 72000, 'Oregon': 16000, 'Utah': 5000} s3 = pd.Series(sdata)Ohio 35000 Texas 72000 Oregon 16000 Utah 5000 dtype: int64
3.从DataFrame中查询出Series
1.概念
- 1.如果只查询一行、一列,返回的是
pd.Series - 2.如果查询多行、多列,返回的是
pd.DataFrame
2.演示
- 获取
state索引列数据import pandas as pd data = { "state": ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'], "year": [2000, 2001, 2002, 2001, 2002], "pop": [1.5, 1.7, 3.6, 2.4, 2.9] } df = pd.DataFrame(data) type(df['state']) # pandas.core.series.Series # 查询第一行 # type(df.loc[0]) # pandas.core.series.Series - 获取
state、year索引列数据import pandas as pd df[['state', 'year']] ''' state year 0 Ohio 2000 1 Ohio 2001 2 Ohio 2002 3 Nevada 2001 4 Nevada 2002 ''' type(df[['state', 'year']]) # pandas.core.frame.DataFrame # 查询前两行 # type(df.loc[0: 1]) # pandas.core.frame.DataFrame # df.loc[0: 1] # 包含尾部索引 ''' state year pop 0 Ohio 2000 1.5 1 Ohio 2001 1.7 '''
4.Pandas数据查询
1.df.loc
1.定义
- 根据行、列的标签查询
2.示例演示(以下方法行列均适应)
1.数据读取
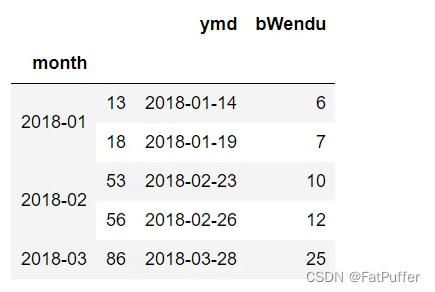
df.read_csv('./data/beijing_tianqi_2018.csv')2.设置索引为日期,方便按日期筛选
df.set_index('year', drop=True, append=False, inplace=False, verify_integrity=False)drop:是否删除作为索引使用的列,默认删除append:将序列添加到索引中,形成多级序列inplace:是否返回在原序列上进行修改,默认否,返回一个新的序列verify_integrity:检查索引是否重复。默认是False
3.数据预处理(将温度的后缀
°C去掉)# 所有行,bWendu列 bWendu列转为字符串,去除°C,然后转换为整形 df.loc[:, "bWendu"] = df["bWendu"].str.replace("°C", "").astype("int32") df.loc[:, "yWendu"] = df["yWendu"].str.replace("°C", "").astype("int32")4.使用单个
label值查询数据# 单元格 数据,得到一个具体的值 df.loc['2018-01-03', 'bWendu']5.使用值列表批量查询
# 一行两列 数据,得到一个Series,即:1月3日的最高温度和最低温度 df.loc['2018-01-03', ['bWendu', 'yWendu']]# 一列两行 数据,得到一个Series,即:1月3日和1月4日的最高温度 df.loc[['2018-01-03', '2018-01-04'], 'bWendu']# 两行两列 数据,得到一个DataFrame df.loc[['2018-01-03', '2018-01-04'], ['bWendu', 'yWendu']]6.使用数值区间进行范围查询(区间包含开始,也包含结束,和列表有所不同)
# 行index区间 # 获取1月3号到1月6号的最高温度 df.loc['2018-01-03':'2018-01-06', 'bWendu']# 列index区间 # 获取1月3号最高温度到风向的所有列 df.loc['2018-01-03', 'bWendu':'fengxiang']# 行列都按区间查询 df.loc['2018-01-03':'2018-01-06', 'bWendu':'fengxiang']7.使用条件表达式查询
# 查询最高温度大于10°C的天气数据 df.loc[df['bWendu'] > 10, :]# 查询最高温度小于30°,并且最低温度大于15°,并且是晴天,并且天气为优的数据 df.loc[(df['bWendu'] < 30) & df['bWendu'] > 15) & df['tianqi'] == '晴') & df['aqiLevel'] == 1), :]8.调用函数查询
def query_data(df): return df.index.str.startswith('2018-09') & df['sqiLevel'] == 1 # 查询9月份,空气质量为优的数据 df.loc[query_data, :]
2.df.ilock
1定义
- 根据行列的数字位置查询
3.df.where
1.定义
- 根据条件替换行或列中的值。如果满足条件,保持原来的值,不满足条件则替换为其他值。默认替换为NaN,也可以指定特殊值。
DataFrame.where(cond, other=nan, inplace=False, axis=None, level=None, errors='raise', try_cast=False, raise_on_error=None)- cond:布尔条件,如果 cond 为真,保持原来的值,否则替换为other
- other:替换的特殊值
- inplace:inplace为真则在原数据上操作,为False则在原数据的copy上操作
- axis:行或列
4.df.query
1.定义
- 根据条件过滤出符合的行或列
5.Pandas新增数据列
1.直接赋值
- 类似于字典新增一个key
# 给所有行,增加一个温差列 值为最高温度减去最低温度 # df["bWendu"]是一个Series,两个Series相减,最终返回还是一个Series df.loc[:, "wencha"] = df["bWendu"] - df["yWendu"]
2.df.apply
沿着
axis轴,将一个Series传递给一个函数,该函数对传递的Series进行处理,返回一个新的Seriesaxis=0代表横轴,即二维坐标系中的x轴,也就是行axis=1代表纵轴,即二维坐标系中的y轴,也就是列# 添加一列温度类型(如果最高温度大于33°就是高温;低于-10°就行就是低温;否则是常温) def get_wendu_type(x): if x["bWendu"] > 30: return "高温" if x["yWendu"] < -10: return "低温" return "常温" df[:, "wendu_type"] = df.apply(get_wendu_type, axis=1) # 对温度类型进行统计 df["wendu_type"].value_counts()
3.df.assign
- 将某一列数据,作为函数参数传入,该函数返回一个新的对象,包含新的列和原来的列
- 可以同时新增多列
# 新增最高温度和最低温度对应的华氏温度列 df.assign( # 新增的列名 x代表df yWendu_huashi = lambda x : x["yWendu"] * 9 / 5 + 32 bWendu_huashi = lambda x : x["bWendu"] * 9 / 5 + 32 )
4.按条件选择分组分别赋值
- 按条件先选择数据,然后对这部分数据进行赋值新列
- 将原数据按照温差进行分组(高温-低温>10,则认为温差大)
# 创建一个新列 df["wencha_type"] = "" # 按条件选择,然后赋值给上面创建的列 df.loc[df["bWendu"] - df["yWendu"] > 10, "wencha_type"] = "温差大" df.loc[df["bWendu"] - df["yWendu"] <= 10, "wencha_type"] = "温差正常"
6.Pandas数据统计函数
1.汇总类统计
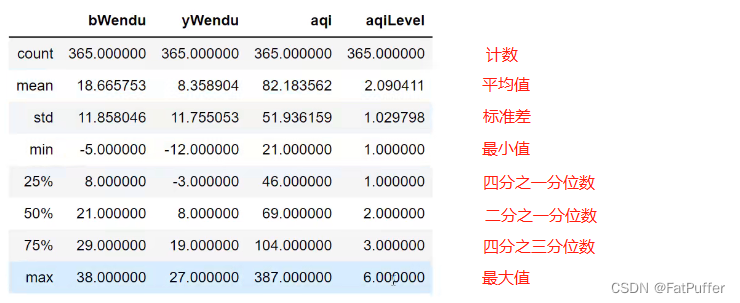
1.一下子提取所有数字列统计结果
df.describe()
2.查看平均值
- 查看高温平均值
df["bWendu"].mean()
3.查看最大值
- 查看最高温
df["bWendu"].max()
4.查看最小值
- 查看最低温
df["yWendu"].min()
2.唯一去重和按值计数
1.唯一性去重(一般用于枚举、分类列)
- 风向去重
df['fengxiang'].unique() - 天气去重
df['tianqi'].unique() - 风力去重
df['fengli'].unique()
2.按值计数
- 统计每个风向出现的次数
df['fengxiang'].value_counts()
3.相关系数和协方差
1.定义
1.协方差
- 1.衡量同向反向程度
- 2.如果协方差为正,说明
X、Y同向变化,协方差越大说明同向程度越高 - 3.如果协方差为负,说明
X、Y反向变化,协方差越小说明反向程度越高
2.相关系数
- 1.衡量相似程度
- 2.当他们相关系数为1时,说明两个变量变化时的正相似度最大
- 3.当他们相关洗漱为-1时,说明两个变量变化时的反相似度最大
2.用途
- 1.两只股票,是不是同涨同跌?程度多大?正常关还是负相关
- 2.产品销量的波动,跟哪些因素正相关、负相关、程度有多大
3.编码
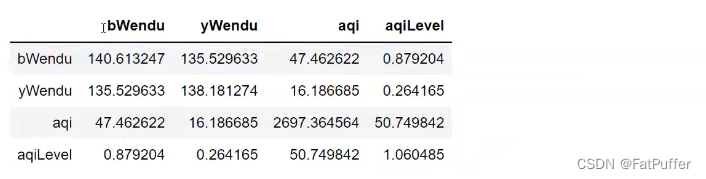
- 协方差矩阵
df.cov()
- 相关系数矩阵
# 可以看出空气质量指数aqi和空气质量等级aqiLevel相关性为0.94,非常的相关 df.corr()
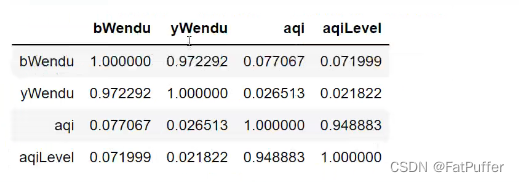
- 单独查看
# 空气质量和最高温度的相关系数 df["aqi"].corr(df["bWendu"]) # 0.077067 # 空气质量和最低温度的相关系数 df["aqi"].corr(df["yWendu"]) # 0.026513 # 空气质量和温差的相关系数 df["aqi"].corr(df["bWendu"] - df["yWendu"]) # 0.216522
7.Pandas缺失值处理
1.isnull和notnull:检测是否是空值,可用于DataFrame和Series
2.dropna:丢弃、删除缺失值
axis:删除行还是列,{0 or ‘index’, 1 or columns},default 0how:如果等于any,则任何值为空都删除,如果等于all则所有值都为空才删除inplace:如果为True则修改当前df,否则返回新的df,默认返回新的
3.fillna:填充空值
value:用于填充的值,可以是单个值,或者字典(key是列名,value是值)method:等于ffill,使用前一个不为空的值填充forward fill,等于bfill,使后一个不为空的值填充backword fillaxis:按行还是列填充,{0 or ‘index’, 1 or columns}inplace:如果为True则修改当前df,否则返回新的df,默认返回新的
4.事例演示
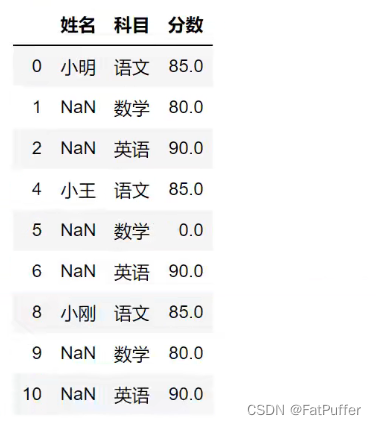
1.数据如下
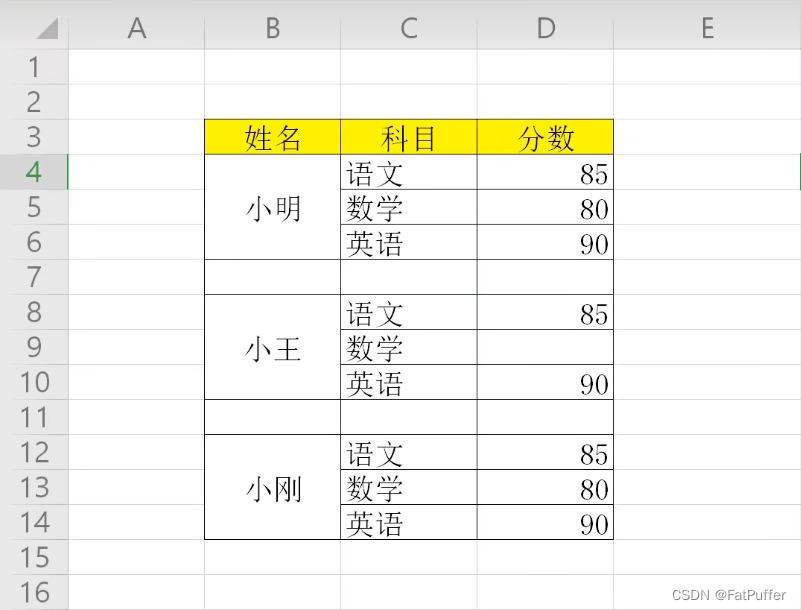
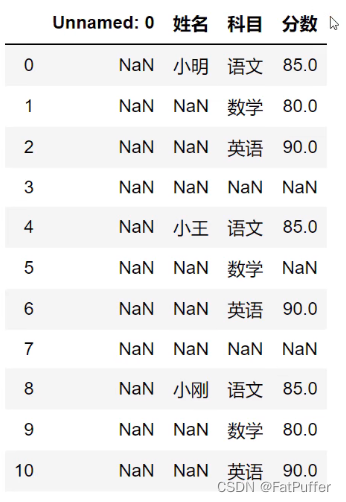
2.读取excel
# 跳过前两行读取
studf = pd.read_excel('./data/study_excel.xlsx', skiprows=2)
3.检测空值
studf.isnull()
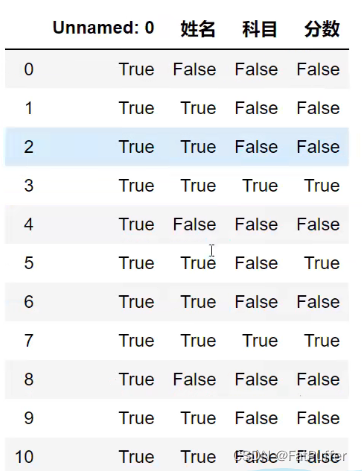
3.1.单列检测空值
studf["分数"].isnull()
3.2.筛选没有空分数的所有行
studf.loc[studf["分数"].notnull(), :]
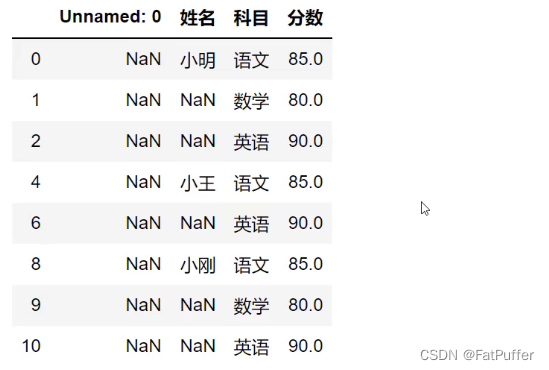
4.删除掉全是空值的列
# 在元数据基础上删除全是空值的列
studf.dropna(axis="columns", how="all", inplace=True)
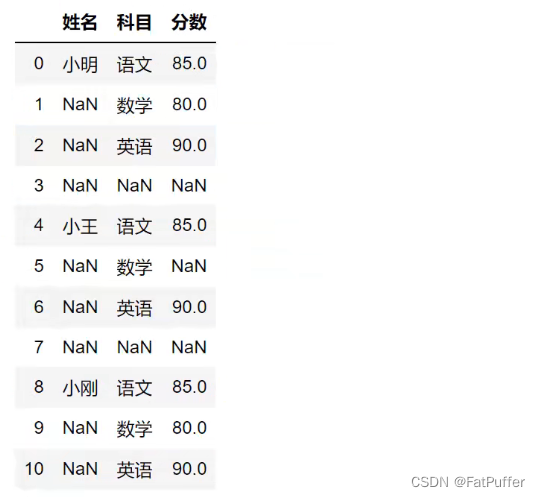
5.删除掉全是空值的行
# 在元数据基础上删除全是空值的行
studf.dropna(axis="index", how="all", inplace=True)
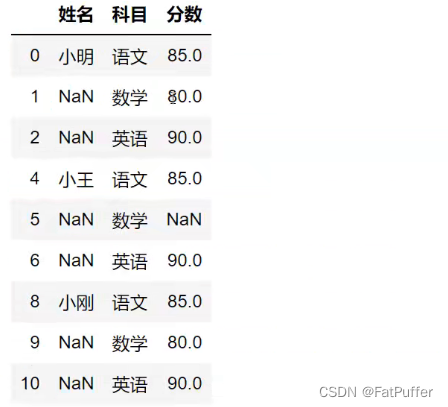
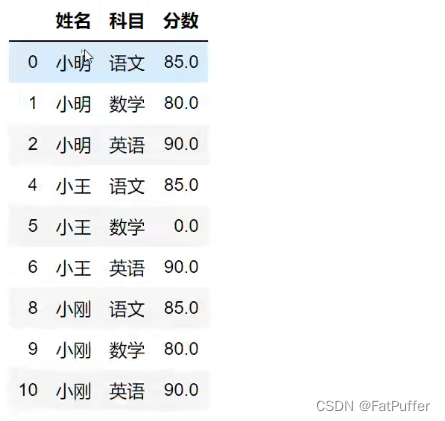
6.将分数列为空的填充为0分
studf.fillna({"分数": 0})
# 等同于
# studf.loc[:, "分数"] = studf['分数'].fillna(0)
7.将姓名的缺失值填充
# 使用前一个不为空的值进行填充
studf.loc[:, "姓名"] = studf["姓名"].fillna(method="ffill")
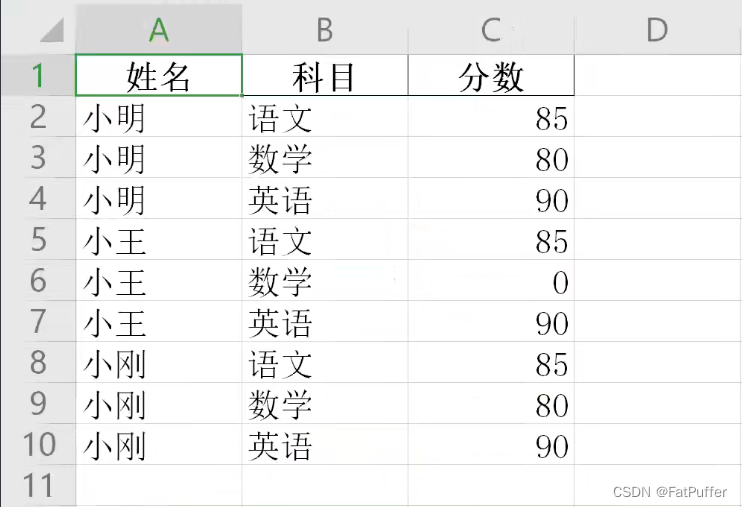
8.将清洗好的excel保存
# index=False:去除索引列
studf.to_excel('./data/result_student.xlsx', index=False)
8.SettingWithCopyWarning告警处理
1.原数据如下
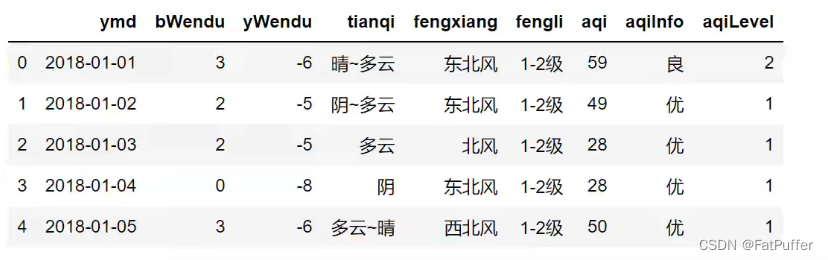
2.复现问题
- 1.只选出3月份的数据,用于分析
condition = df["ymd"].str.startswith("2018-03") # 设置温差列(报错) df[condition]["wencha"] = df["bWendu"] - df["yWendu"] # 查看结果 df[condition].head()
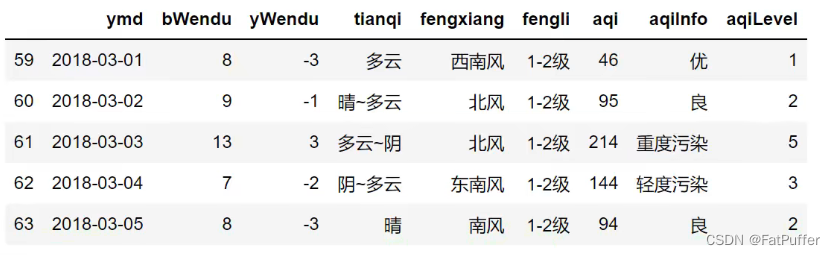
3.原因
- 发出告警的代码:
df[condition]["wencha"] = df["bWendu"] - df["yWendu"] - 相当于:
df.get("condition").set("wencha") - 第一步的
get发出了报警,链式操做其实是两个步骤,先get后set get得到的dataframe可能是view(子df),也可能是copy(新的df),pandas发出警告。- 核心要诀:
pandas的dataframe的修改写操做,只允许在源dataframe上进行
4.解决方法
- 1.将
get+set的两步操做,变成set的一步操做df.loc[condition, 'wen_cha'] = df["bWendu"] - df["yWendu"] df[condition].head()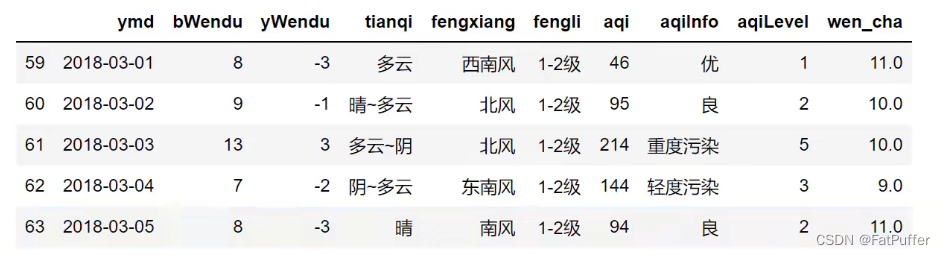
- 2.使用
copy复制dataframedf_month3 = df[condition].copy() df_month3[condition]["wencha"] = df["bWendu"] - df["yWendu"] df_month3.head()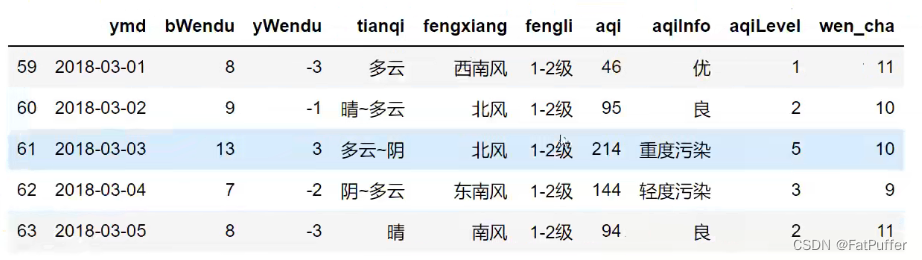
5.提示
Pandas不允许先筛选子dataframe,再进行修改写入- 要么使用
.loc实现一个步骤直接修改源dataframe - 要么先复制一个新的
dataframe,再在该对象上进行修改写入
9.Pandas数据排序
1.对Series排序
1.函数及参数说明
Series.sort_values(ascending=True, inplace=False)
ascending:默认为True升序排序,False为降序排序inplace:修改原始数据还是复制一份新的数据
2.对高温列进行排序
df["bWendu"].sort_values()
2.对DataFrame排序
1.函数及参数说明
DataFrame.sort_values(by, ascending=True, inplace=False)
by:str或List<str>,单列排序或者多列排序ascending:默认为True升序排序,False为降序排序inplace:修改原始数据还是复制一份新的数据
2.单列排序
df.sort_values(by='aqi')
3.多列排序
df.sort_values(by=['bWendu', 'yWendu'], ascending=[True, False])
10.Pandas字符串处理
1.使用方法
- 先获取
Series,再在str属性上调用函数- 只能在字符串列上使用
DataFrame上没有str属性和处理方法Series.str并不是python中的原生字符串,而是一套自己的方法,不过大部分和原生str很像
2.官方地址
3.实例演示
object列都是字符串列,可以直接使用str的方法

1.获取
Series的str属性
df["bWendu"].str
- 2.字符串替换函数
df["bWendu"].str.replace("°C", "")
- 3.判断是不是数字
df["bWendu"].str.isnumeric()
- 4.获取字符串长度
df["bWendu"].str.len()
- 5.判断字符串是否以什么开头
condition = df["ymd"].str.startswith("2018-03")
df[condition].head()
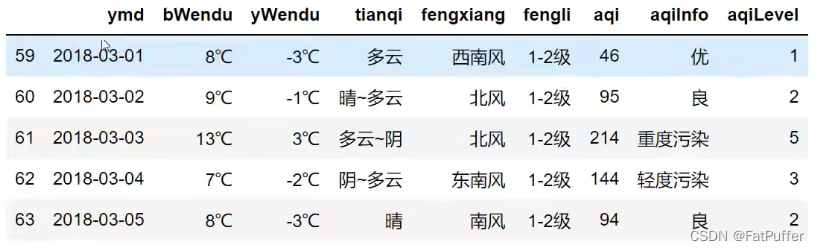
- 6.链式多次处理
df["ymd"].str.replace("-", "").str.slice(0, 6)
# df["ymd"].str.replace("-", "").str[0:6]
- 7.正则表达式
# 1.新增一列中文日期
def get_nianyueri(x):
year,month,day = x["ymd"].split("-)
return f"{year}年{month}月{day}日"
df["中文日期"] = df.apply(get_nianyueri, axis=1)
# 2.去掉中文日期这一列中的年月日中文字样
# 方法一:
df["中文日期"].str.replace("年", "").str.replace("月", "").str.replace("日", "")
# 方法二:
df["中文日期"].str.replace("[年月日]", "")
11.Pandas的axis参数
1.详解
- axis=0 或者 “index”
- 如果是单行操做,就值的是某一行
- 如果是聚合操作,指的是跨行,想象一下
从上往下挤压
- axis=1 或者 ”columns“
- 如果是单列操做,就指的是某一列
- 如果是聚合操做,指的是跨列,想象一下
从左往右挤压
2.示例
1.构造数据
import pandas as pd
import numpy as np
df = pd.DataFrame(
np.arange(12).reshape(3,4),
columns=["A", "B", "C", "D"]
)
'''
A B C D
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
'''
2.单列drop,就是删除某一列
df.drop("A", axis=1)
'''
B C D
0 1 2 3
1 5 6 7
2 9 10 11
'''
3.单行drop,就是删除某一列
df.drop(1, axis=0)
'''
A B C D
0 0 1 2 3
2 8 9 10 11
'''
4.跨行求取平均值
df.mean(axis=0)
'''
A 4.0
B 5.0
C 6.0
D 7.0
dtype: float64
'''
5.跨列求取平均值
df.mean(axis=1)
'''
0 1.5
1 5.5
2 9.5
dtype: float64
'''
6.增加一列sum_value,保存每行的和
def get_sum_value(x):
return x["A"] + x["B"] + x["C"] + x["D"]
df["sum_value"] = df.apply(get_sum_value, axis=1)
'''
A B C D sum_value
0 0 1 2 3 6
1 4 5 6 7 22
2 8 9 10 11 38
'''
12.Pandas的索引index
1.用途
- 1.更方便的数据查询
- 2.使用index可以获得性能提升
- 3.自动的数据对齐功能
- 4.更多更强大的数据结构支持
2.示例
1.使用index查询数据
1.读取数据
import pandas as pd fpath = './data/ratings.csv' df = pd.read_csv(fpath)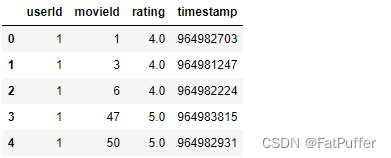
2.设置索引
df.set_index("userId", inplace=True, drop=False)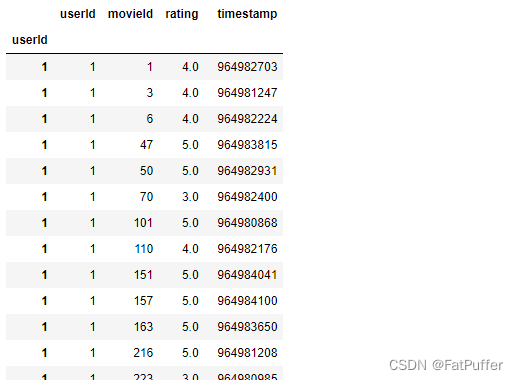
3.使用索引查询
# 使用index查询 df.loc[500].head() # 相当于 df.loc["userId" == 500].head()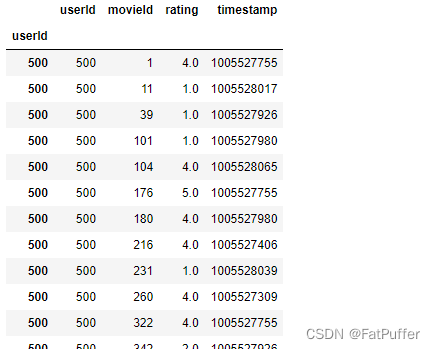
2.使用index提升性能
- 如果index是唯一的,
Pandas会使用哈希表优化,查询性能O(1) - 如果index不是唯一,但是有序,``Pandas会使用二分查找算法,查询性能
O(logN) - 如果index是完全随机的,那么每次查询都要扫描全表,查询性能为
O(N) - 实验一:完全随机的顺序查询
from sklearn.utils import shuffle df_shuffle = shuffle(df) # 检查索引是否是递增的 df_shuffle.index.is_monotonic_increasing # False # 检查索引是否唯一 df_shuffle.index.is_unique # False # 计时,查询 id=500的数据性能 %timeit df_shuffle.loc[500] # 498 µs ± 28.3 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each) - 实验二:将index排序后的查询
df_sorted = df_shuffle.sort_index() # 检查索引是否是递增的 df_sorted .index.is_monotonic_increasing # True # 检查索引是否唯一 df_sorted .index.is_unique # False # 计时,查询 id=500的数据性能 %timeit df_sorted.loc[500] # 231 µs ± 13.7 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
3.使用index能自动对齐数据
- 包括series和dataframe
import pandas as pd s1 = pd.Series([1, 2, 3], index=list("abc")) ''' a 1 b 2 c 3 dtype: int64 '''s1 = pd.Series([2, 3, 4], index=list("bcd")) ''' b 2 c 3 d 4 dtype: int64 '''s1 + s2 ''' a NaN b 4.0 c 6.0 d NaN dtype: float64 '''
4.使用index更多更强大的数据结构支持
CategoricalIndex,基于分类数据的Index,提升性能MultiIndex,多维索引,用于groupby多维聚合后结果等DatetimeIndex,时间类型索引,强大的日期和时间的方法支持
13.Pandas的Merge语法
1.说明
- Pandas的Merge,相当于Sq的Join,将不同的表按key关联到一个表
2.用法
pd.merge(left, right, how="Inner", on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=('_x', '_y'), copy=True, indicator=False, )
left:要merge的dataframe或seriesright:要merge的dataframe或serieshow:join类型,‘left’,‘right’,‘outer’,‘inner’on:join的key,left和right都要有这个keyleft_on:left的df或series的keyright_on:right的df或series的keyleft_index:使用index而不是普通的column做joinright_index:使用index而不是普通的column做joinsort:排序suffixes:合并表时重名字段自定义命名copyindicator
3.电影数据集join实例
1.电影评分数据集
1.用户对电影的评分数据:
ratings.datimport pandas as pd df_ratings = pd.read_csv( "./data/ratings.dat", sep="::", # 分隔符为两个字符时会被识别为正则表达式,指定engine=python来告诉pandas他是一个字符串 engine="python", names=["UserID", "MovieID", "Rating", "Timestamp"] )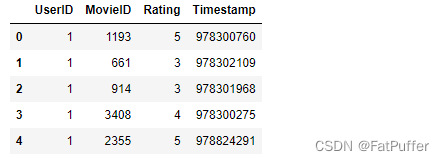
2.用户本身的信息数据:
users.datdf_users = pd.read_csv( "./data/users.dat", sep="::", # engine="python", names="UserID::Gender::Age::Occupation::Zip-code".split("::") )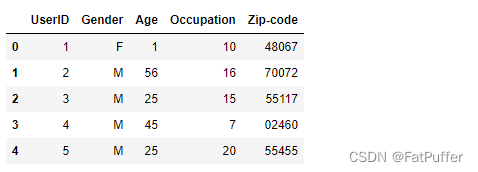
3.电影本身的数据:
movies.datdf_momvies = pd.read_csv( "./data/movies.dat", sep="::", # engine="python", names="MovieID::Title::Geners".split("::") )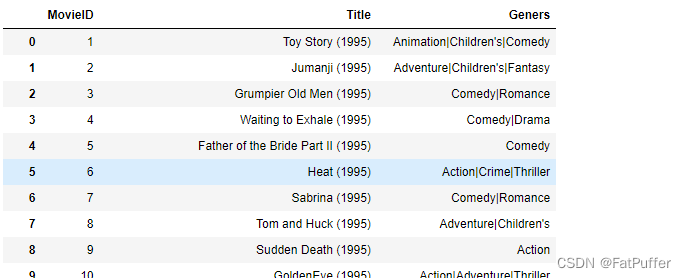
4.用户和评分join
df_ratings_users = pd.merge( df_ratings, df_users, left_on="UserID", right_on="UserID", how="inner" )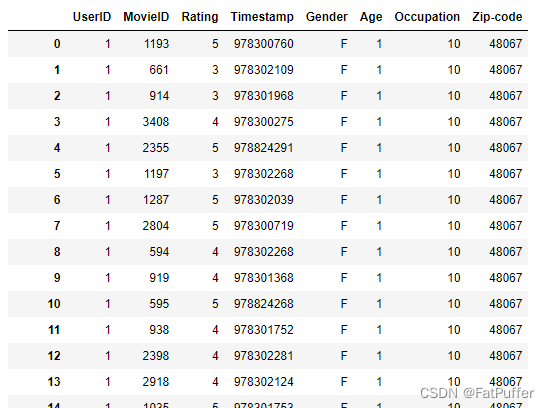
5.用户和评分join的结果再和电影join
df_ratings_movies = pd.merge( df_ratings, df_momvies, left_on="MovieID", right_on="MovieID", how="inner" )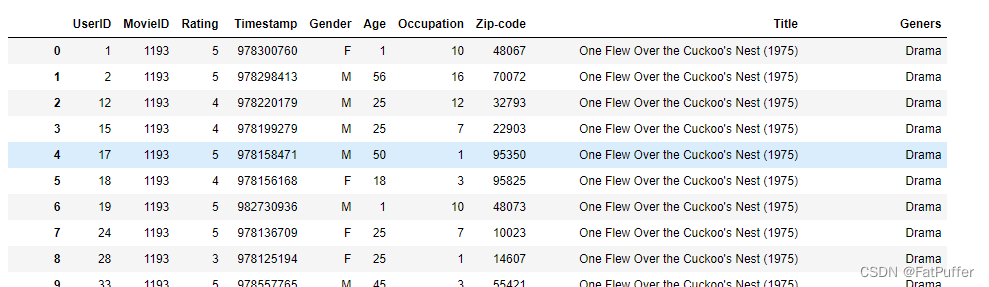
2.理解merge时数量的对齐关系
1.关系理解
one-to-one:关联的key都是唯一的one-to-many:左边key唯一,右边key不唯一many-to-many:左边右边key都不是唯一的
2.一对一关系的merge
1.数据表如下
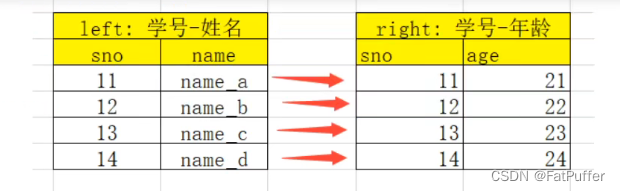
2.合并
left = pd.DataFrame({ "sno": [11, 12, 13, 14], "name": ["name_a", "name_b", "name_c", "name_d"] }) right = pd.DataFrame({ "sno": [11, 12, 13, 14], "age": ["21", "22", "23", "24"] }) pd.merge(left, right, on="sno")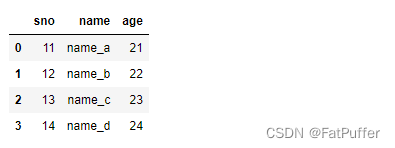
2.一对多关系的merge
- 1.数据表如下
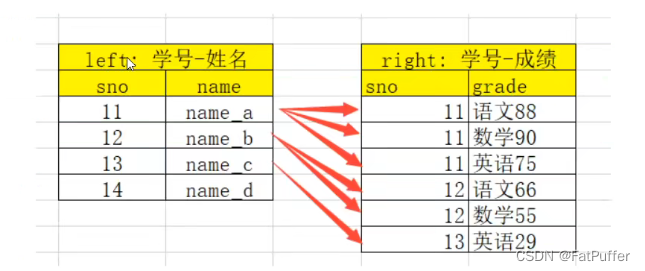
- 2.合并
left = pd.DataFrame({ "sno": [11, 12, 13, 14], "name": ["name_a", "name_b", "name_c", "name_d"] }) right = pd.DataFrame({ "sno": [11, 11, 11, 12, 12, 13], "grade": ["语文88", "数学90", "英语75", "语文66", "数学55", "英语29"] }) pd.merge(left, right, on="sno")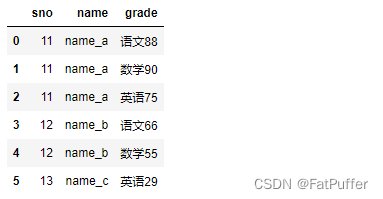
2.多对多关系的merge
- 1.数据表如下
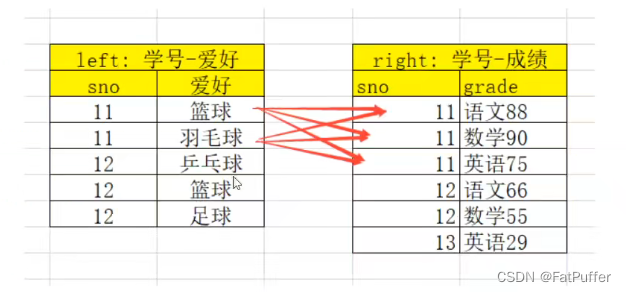
- 2.合并
left = pd.DataFrame({ "sno": [11, 11, 12, 12, 12], "爱好": ["篮球", "羽毛球", "乒乓球", "篮球", "足球"] }) right = pd.DataFrame({ "sno": [11, 11, 11, 12, 12, 13], "grade": ["语文88", "数学90", "英语75", "语文66", "数学55", "英语29"] }) pd.merge(left, right, on="sno")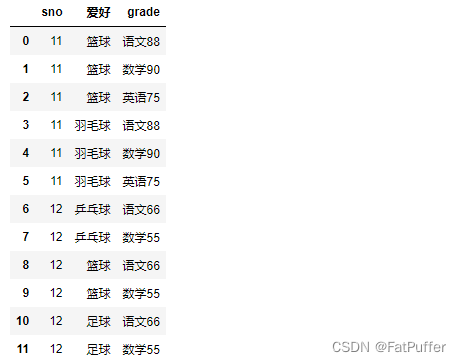
3.理解left join、right join、inner join、outer join时数量的对齐关系
1.图示
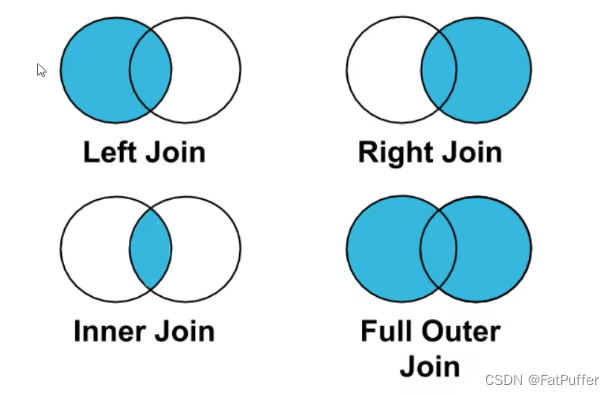
2.实例
1.数据如下


left = pd.DataFrame({ "key": ["K0", "K1", "K2", "K3"], "A": ["A0", "A1", "A2", "A3"], "B": ["B0", "B1", "B2", "B3"] }) right = pd.DataFrame({ "key": ["K0", "K1", "K4", "K5"], "C": ["C0", "C1", "C2", "C3"], "D": ["D0", "D1", "D2", "D3"] })2.
inner join,默认,左右都有的key,才会出现在结果里pd.merge(left, right, how='inner')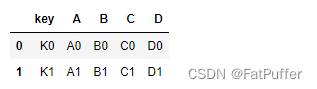
3.
left join,左边的都会出现在结果里,右边匹配不到的以Null填充pd.merge(left, right, how='left')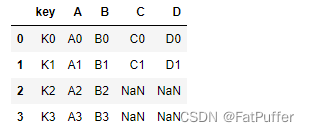
4.
right join,右边的都会出现在结果里,左边匹配不到的以Null填充pd.merge(left, right, how='right')
5.
outer join,左边右边的都会出现在结果里,相互匹配不到的以Null填充pd.merge(left, right, how='outer')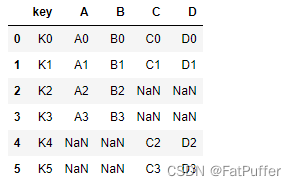
4.重复key
1.图示


2.使用
suffixes默认值pd.merge(left, right, on="key")
3.自定义重名的key
pd.merge(left, right, on="key", suffixes=("_left", "_right"))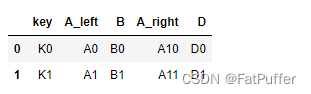
14.Pandas的Concat合并
1.语法
1.说明
- 使用某种合并方式(inner/outer)
- 沿着某个轴向(axis=0/1)
- 把多个Pandas对象(DataFrame/Series)合并成一个
2.concat语法
pd.concat(objs, axis=0, join="outer", ignore_index=False)
objs:一个列表,内容可以是DataFrame或者Series,可以混合axis:默认是0,代表按行合并,如果等于1代表按列合并join:合并的时候索引的对齐方式,默认是outer join,也可以是inner joinignore_index:是否忽略掉原来的数据索引
3.append语法
df.append(other, ignore_index=False)
append只有按行合并,并没有按列合并,相当于concat按行合并的简写other:单个df、series、dict或者列表ignore_index:是否忽略掉原来的数据索引
2.使用场景
- 批量合并想同格式的
Excel - 给
DataFrame添加行 - 给
DataFrame添加列
3.使用pandas.concat合并数据
1.数据准备
df1 = pd.DataFrame({
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
"E": ["E0", "E1", "E2", "E3"]
})
df2 = pd.DataFrame({
"A": ["A4", "A5", "A6", "A7"],
"B": ["B4", "B5", "B6", "B7"],
"C": ["C4", "C5", "C6", "C7"],
"D": ["D4", "D5", "D6", "D7"],
"F": ["F4", "F5", "F6", "F7"]
})


2.默认concat,参数为axis=0、join=outer、ignore_index=False
pd.concat([df1, df2])

3.使用ignore_index=True忽略原来的索引
pd.concat([df1, df2], ignore_index=True)
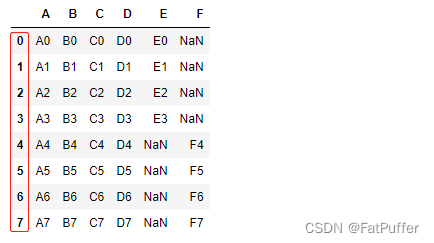
4.使用join=inner过滤掉不匹配的列
pd.concat([df1, df2], ignore_index=True, join="inner")

5.使用axis=1进行列合并
pd.concat([df1, df2], axis=1)

6.DdataFrame和Series混合关联
- 增加一列
s1 = pd.Series(list(range(4)), name='F')
pd.concat([df1, s1], axis=1)
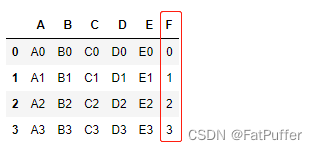
- 增加一行
# 添加行
s2 = pd.Series({i: i+str(4) for i in "ABCDE"}, name=4)
df1.append(s2)

4.使用DataFrame.append按行合并数据
1.数据准备


df1 = pd.DataFrame(
[
[1, 2],
[3, 4]
],
columns=list("AB")
)
df2 = pd.DataFrame(
[
[5, 6],
[7, 8]
],
columns=list("AB")
)
2.给df1添加一个名为df2的dataframe
df1.append(df2)

3.忽略原索引
df1.append(df2, ignore_index=True)

4.可以一行一行的给DataFrame添加数据
- 低性能版本
df = pd.DataFrame(
columns=["A"]
)

for i in range(5):
df = df.append({"A": i}, ignore_index=True)
df

- 高性能版本
pd.concat(
# 数据量过大时,需要分批
[pd.DataFrame([i], columns=["A"]) for i in range(5)],
ignore_index=True
)

15.Pandas批量拆分与合并Excel文件
1.实例演示
1.将一个大的Excel等份拆成多个小的Excel
- 1.数据读取
import pandas as pd
df_source = pd.read_excel('./data/crazyant_blog_articles.xlsx')
df_source.head()
df_source.shape # (258, 3)
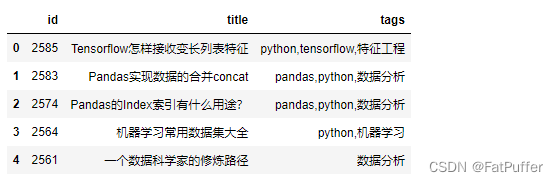
- 2.计算拆分后的每个excel的行数
# 拆分列表
user_names = ['zs', 'ls', 'ww', 'zl', 'sq', 'qb']
# 获取总行数
total = df_source.shape[0]
# 计算每个人的任务条目
split_size = total // len(user_names)
if split_size % len(user_names) != 0:
split_size += 1
- 3.拆分成多个dataframe
df_subs = []
for idx, user_name in enumerate(user_names):
# iloc的开始索引
begin = idx * split_size
# iloc的结束索引
end = begin + split_size
# 实现df按照iloc拆分
df_sub = df_source.iloc[begin:end]
# 将每个子df存入列表
df_subs.append((idx, user_name, df_sub))
- 4.将每个dataframe存入excel
for idx, user_name, df_sub in df_subs:
file_name = f"./split_dir/{idx}_{user_name}.xlsx"
df_sub.to_excel(file_name, index=False)
2.将多个小的Excel合并成一个大的Excel,并且标记来源
- 1.遍历文件夹,得到要合并的Excel名称列表
import os
excel_names = []
for excel_name in os.listdir('./split_dir'):
excel_names.append(excel_name)
- 2.分别读取到dataframe
df_list = []
for index, excel_name in enumerate(excel_names):
# 读取每个excel到df
excel_path = f"./split_dir/{excel_name}"
df_split = pd.read_excel(excel_path)
# 得到username
username = excel_name.replace(f"{index}_", "").split(".")[0]
# 每个df添加1列,用户名
df_split["username"] = username
print(df_split)
df_list.append(df_split)
- 3.使用
pd.concat进行合并
df_merge = pd.concat(df_list)
df_merge.shape # (258, 4)
df_merge.head()
df_mergr["username"].value_counts()
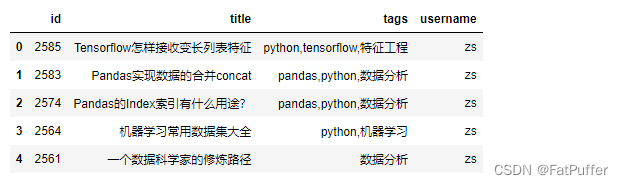

- 4.将合并后的dataframe输出到excel中
# index=False:忽略每个表中自己的索引
df_merge.to_excel(f"./split_dir/new_articles.xlsx", index=False)
16.Pandas实现group by分组
1.分组使用聚合函数做数据统计
1.准备数据
import pandas as pd
import numpy as np
%matplotlib inline # 加这一句,能在jupyter notebook展示matplot图表
df = pd.DataFrame({
"A": ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],
"B": ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],
"C": np.random.randn(8),
"D": np.random.randn(8),
})
2.单个group by查询所有数据列的统计
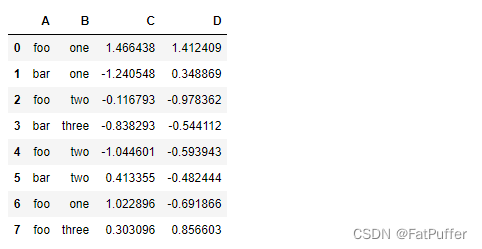
df.groupby('A').sum()

- 1.groupby中的
A变成了数据的索引列 - 2.因为要统计
sum,但B列不是数字,所以被自动忽略掉 - 3.按照A列分组,分为两组
foo和bar,然后计算foo和bar在C和D列对应的值加和后的结果
2.多个列groupby,查询所有数据列的统计
df.groupby(['A', 'B']).mean()
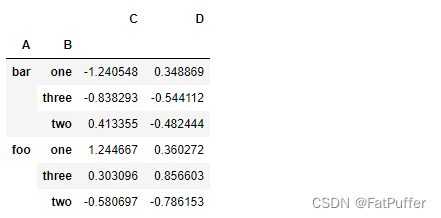
('A', 'B')成对变成了二级索引
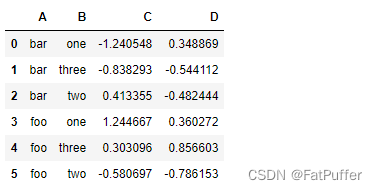
df.groupby(['A', 'B'], as_index=False).mean()
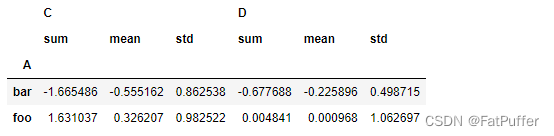
3.同时查看多种数据统计
df.groupby('A').agg([np.sum, np.mean, np.std])
4.查看单列的结果数据统计
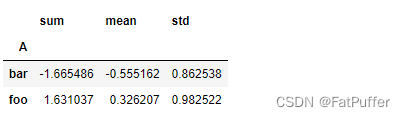
df.groupby('A')['C'].agg([np.sum, np.mean, np.std])
# df.groupby('A').agg([np.sum, np.mean, np.std])['C']
5.不同列使用不同的聚合函数
df.groupby('A').agg({"C": np.sum, "D":np.mean})
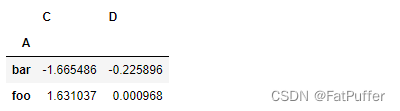
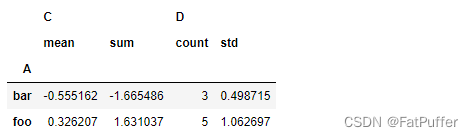
df.groupby('A').agg({'C':[np.mean,'sum'],'D':['count',np.std]})
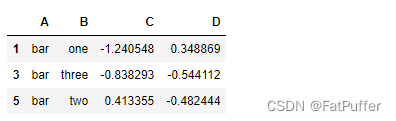
2.遍历groupby的结果理解执行流程
1.遍历单个列聚合的分组
g = df.groupby("A")
for name, group in g:
print(name)
print(group)

- 获取单个分组的数据
g.get_group("bar")
2.遍历多个列聚合的分组
g = df.groupby(["A", "B"])
for name, group in g:
print(name)
print(group)

- 获取单个分组的数据
g.get_group(('foo', 'two'))
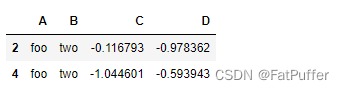
- 查看groupby后的C列,生成一个Series
for name, group in g['C']:
print(name)
print(group)
print(type(group))

3.实例分组探索天气数据
1.准备数据
import pandas as pd
fpath = "./data/beijing_tianqi_2018.csv"
df = pd.read_csv(fpath)
# 替换温度后面的 °C
df.loc[:, "bWendu"] = df["bWendu"].str.repace("°C", "").astype("int32")
df.loc[:, "yWendu"] = df["yWendu"].str.repace("°C", "").astype("int32")
df.head()
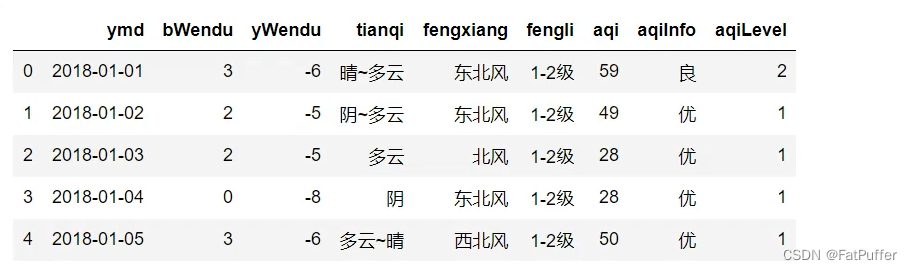
2.查看每个月的最高温度
- 新增一列月份
df["month"] = df["ymd"].str[:7]
df.head()
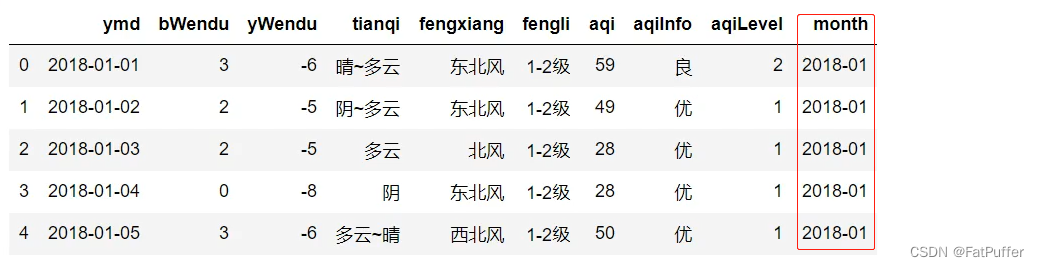
- 按照月份分组统计
data = df.groupby("month")["bWendu"].max()

type(data) # pandas.core.series.Series
data.plot()
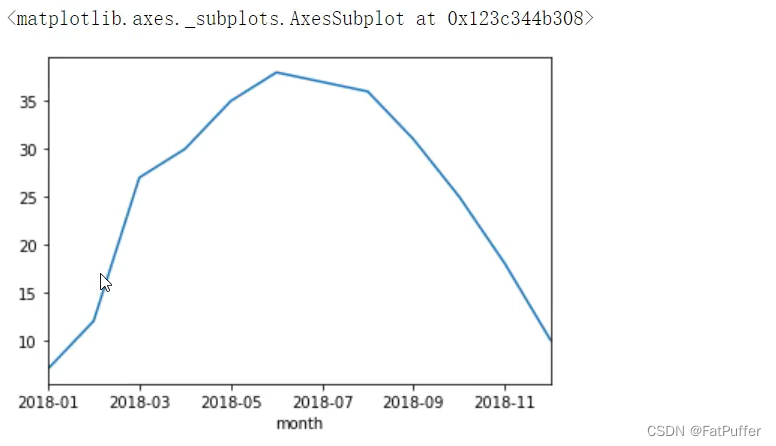
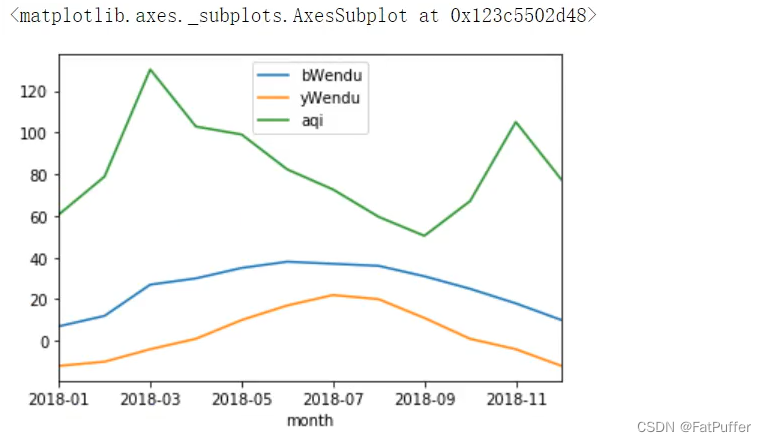
2.查看每个月的最高温度、最低温度、平均空气质量指数
group_data = df.groupby("month").agg({"bWendu": np.max, "yWendu": np.min, "aqi": np.mean})
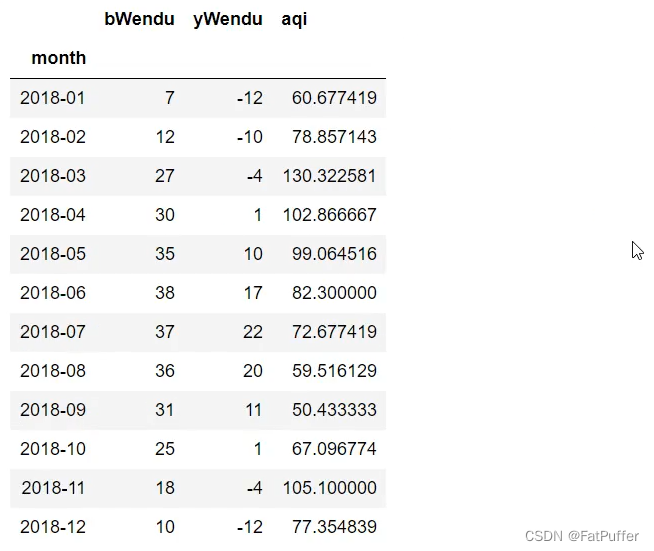
group_data.plot()
17.Pandas的分层索引MultiIndex
1.分层索引作用
- 1.分层索引:在一个轴上向上拥有多个索引层级,可以表达更高维度的数据形式
- 2.可以方便的进行数据筛选,如果有序则性能更好
- 3.groupby等操作的结果,如果是多KEY,结果是封层索引
- 4.一般不需要自己创建分层索引(MultiIndex有构造函数,但一般不用)
2.实例演示
1.数据展示
- 以下为:百度、阿里巴巴、爱奇艺、京东四家公司的10天股票数据
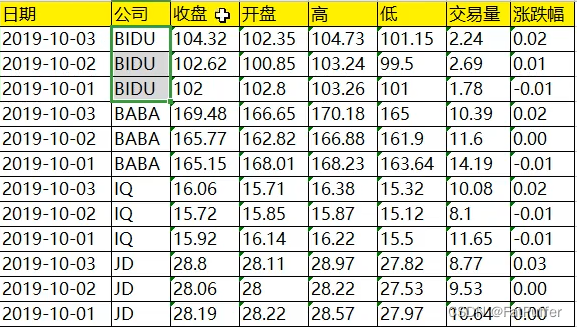
2.Series的分层索引MultiIndex
- 1.数据准备
import pandas as pd
%matplotlib inline
stocks = pd.read_excel('./data/internet.xlsx')
stocks.shape # (12, 8)
stocks.head(3)
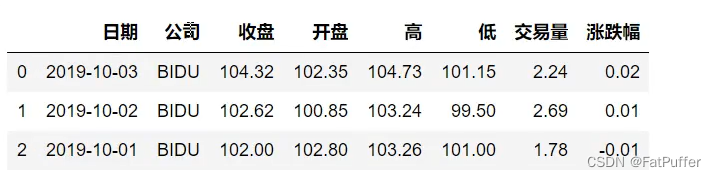
stocks['公司'].unique()
# array(["BIDU", "BABA", "IQ", "JD"], dtype=object)
stocks.index
# RangeIndex(start=0, stop=12, setp=1)
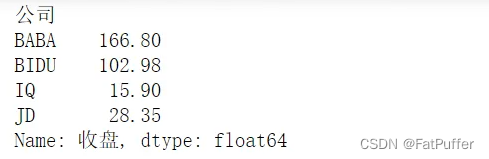
stocks.groupby("公司")["收盘"].mean()
- 2.分层索引MultiIndex
ser = stocks.groupby(['公司', '日期'])["收盘"].mean()
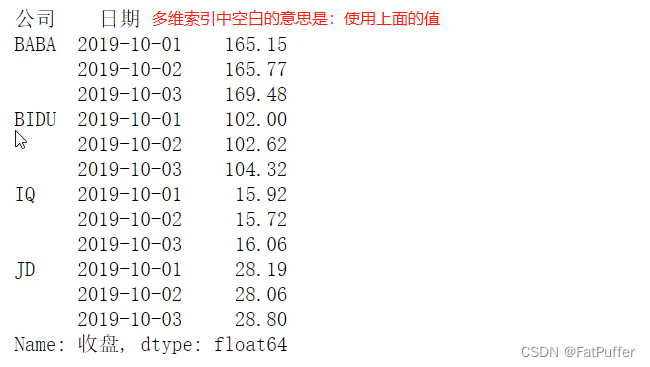
ser.index

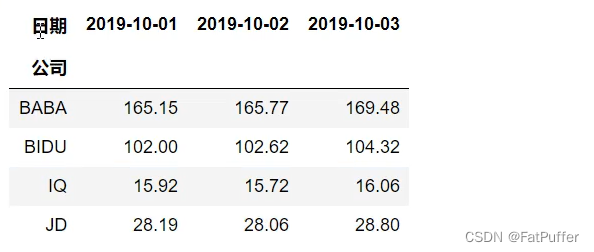
# 把二级索引变成列
ser.unstack()
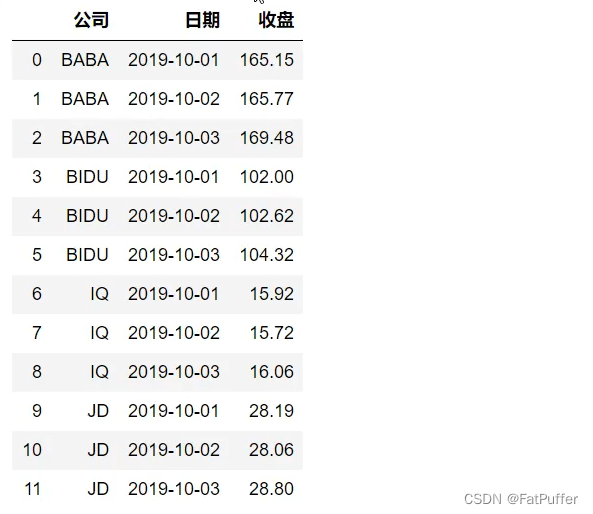
ser.reset_index()
3.Series有多层索引怎样刷选数据
- 1.指定个索引晒筛选
ser = stocks.groupby(['公司', '日期'])["收盘"].mean()
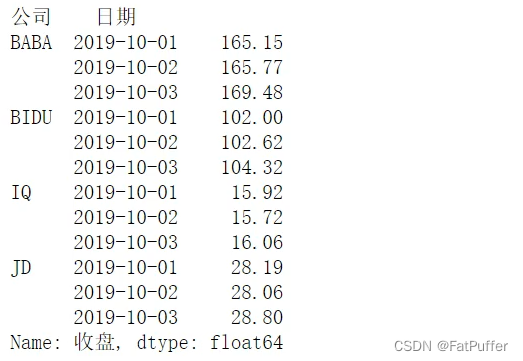
ser.loc["BIDU"]
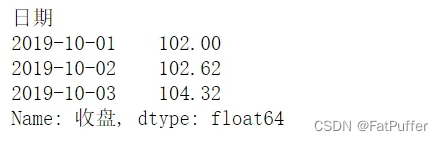
- 2.多层索引使用元组形式筛选
#
ser.loc[("BIDU", "2019-10-02")]

- 3.多层索引使用切片形式筛选
#
ser.loc[:, "2019-10-02"]

4.DataFrame的多层索引MultiIndex
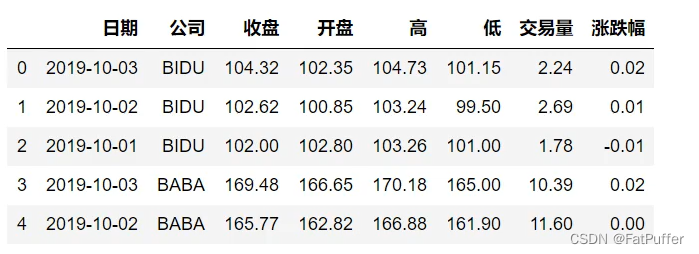
- 1.数据准备
stocks.head()
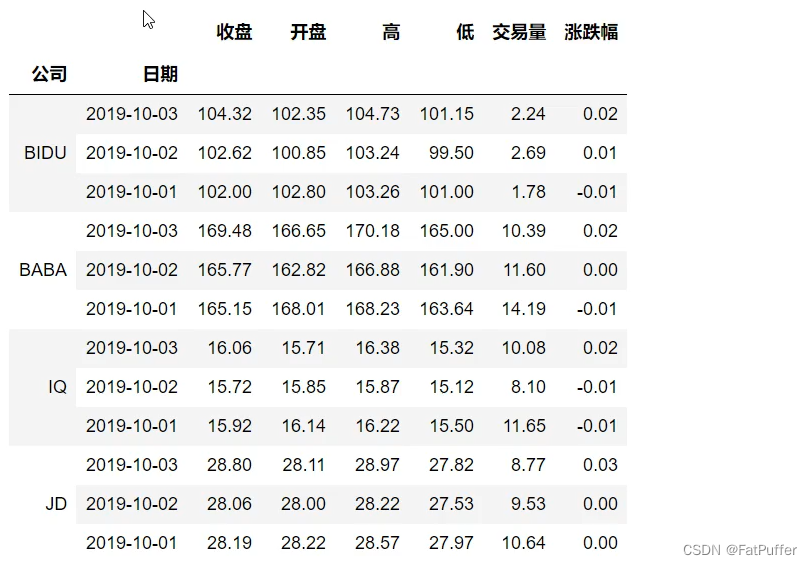
- 2.设置分层索引
stocks..set_index(["公司", "日期"], inplace=True)
- 3.查看分层索引
stocks.index

- 4.对分层索引进行排序
stocks.sort_index(inplace=True)
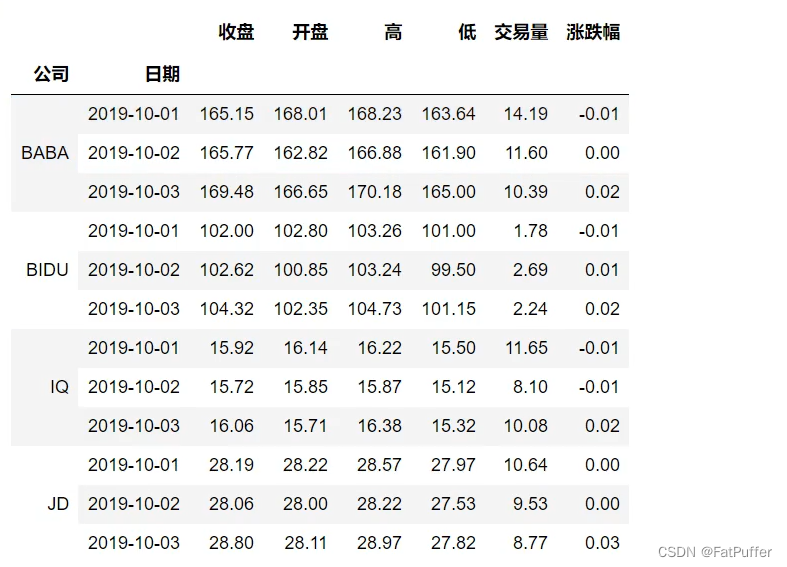
5.DataFrame有多层索引怎样刷选数据
- 【重要知识】在选择数据时
- 元组(key1, key2)代表筛选多层索引,其中
key1是索引的第一级,key2是索引的第二级,比如:key1=JD, key2=2019-10-02 - 列表 [key1, key2] 代表同一层级的多个KEY,其中
key1和key2是并列的同级索引,比如:key1=JD, key2=BABA
- 元组(key1, key2)代表筛选多层索引,其中
stocks.loc["BIDU"]
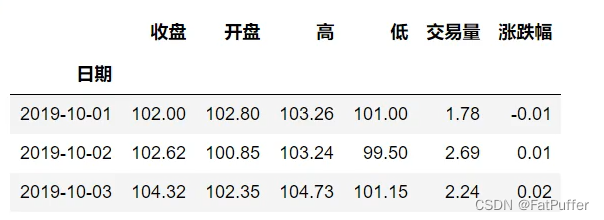
stocks.loc[("BIDU", "2019-10-02"), :]

stocks.loc[("BIDU", "2019-10-02"), "开盘"]

stocks.loc[["BIDU", "JD"], :]
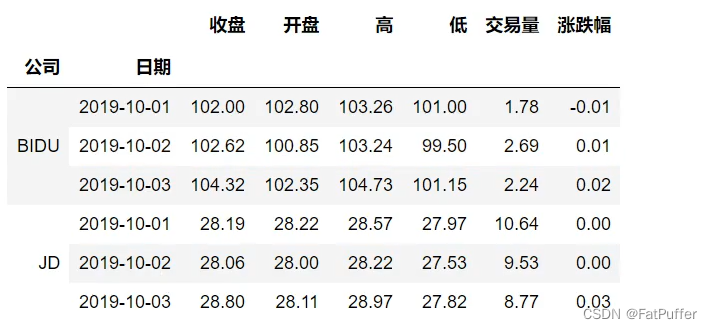
stocks.loc[(["BIDU", "JD"], "2019-10-03"), :]
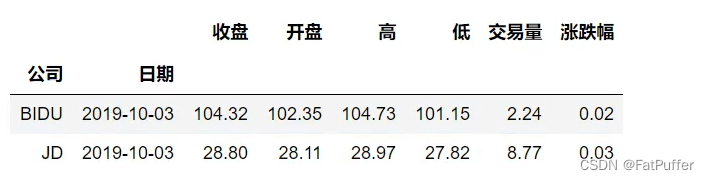
stocks.loc[(["BIDU", "JD"], "2019-10-03"), "收盘"]

stocks.loc[("BIDU", ["2019-10-02", "2019-10-03"]), "收盘"]

# slice(None)代表筛选这一索引所有的内容
stocks.loc[(slice(None), ["2019-10-02", "2019-10-03"]), "收盘"]
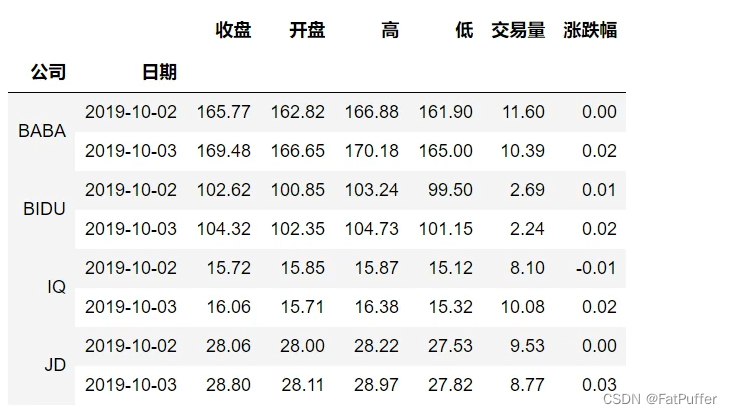
stocks.reset_index()
18.Pandas的数据转换函数map、apply、applymap
1.数据转换函数对比
- 1.
map:只用于Series,实现每个值—>值的映射 - 2.
apply:用于Series实现每个值的处理,用于DataFrame实现某个轴的Series的处理 - 3.
applymap:只能用于DataFrame,用于处理该DataFrame的每个元素
2.map用于Series值的转换
1.将股票代码英文转换成中文名字
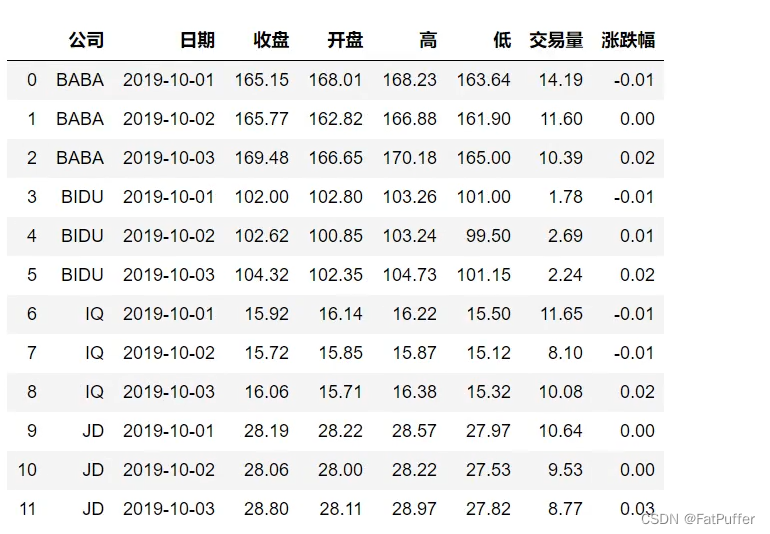
import pandas as pd
stocks = pd.read_excel("./data/internet.xlsx")
stocks.head()
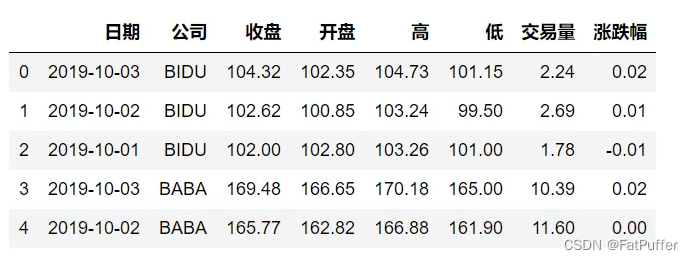
stocks["公司"].unique()
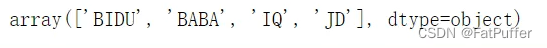
2.使用Series.map(dict)进行转换
- function的参数是Series的每个元素的值
dict_company_names = {
"bidu": "百度",
"baba": "阿里巴巴",
"iq": "爱奇艺",
"jd": "京东"
}
stocks["中文公司1"] = stocks["公司"].str.lower().map(dict_company_names)
stocks.head()
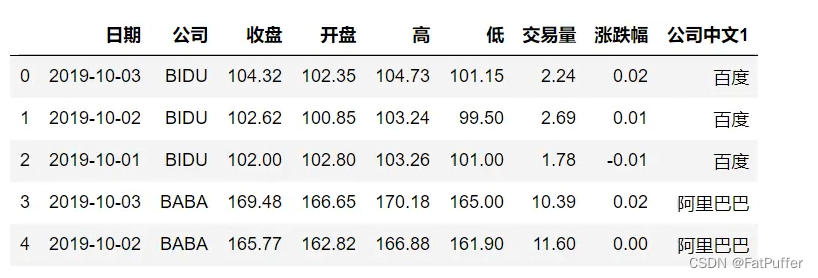
3.使用Series.map(function)进行转换
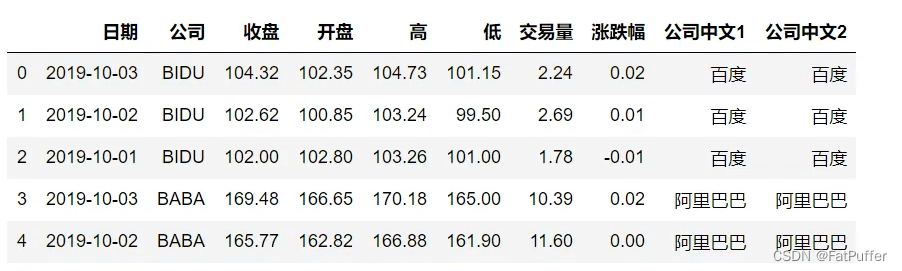
stocks["中文公司2"] = stocks["公司"].map(lambda x: dict_company_names[x.lower()])
stocks.head()
3.apply用于Series和DataFrame的转换
1.Series.apply(function),函数的参数是每个值
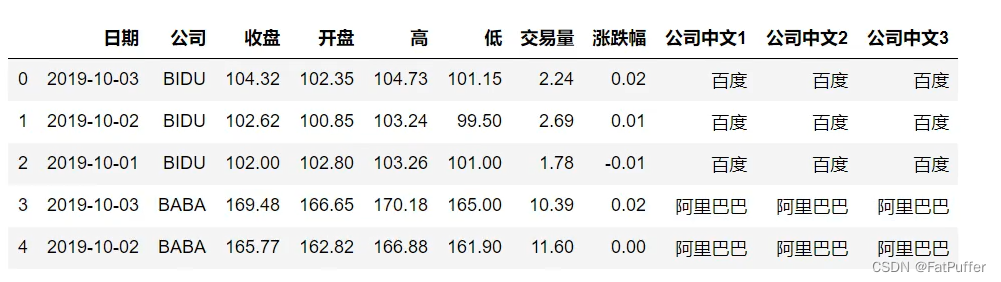
stocks["中文公司3"] = stocks["公司"].apply(lambda x: dict_company_names[x.lower()])
stocks.head()
2.DataFrame.apply(function),函数的参数是Series
stocks["中文公司3"] = stocks.apply(lambda x: dict_company_names[x["公司"].lower()], axis=1)
stocks.head()
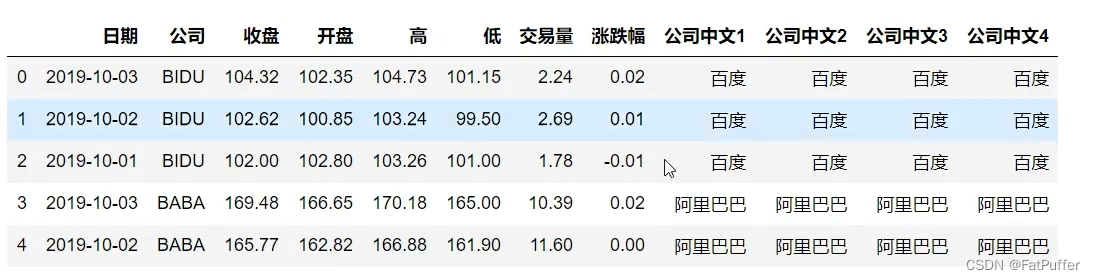
- 1.apply是在stocks这个DataFrame上进行调用;
- 2.lambda x,x是一个Series,因为指定了axis=1,所以Series的key是由列名组成,可以使用
x["公司"]获取公司这一列数据,然后进行处理
4.applymap用于DataFrame所有值的转换
sub_df = stocks[["收盘", "开盘", "高", "低", "交易量"]]
sub_df.head()
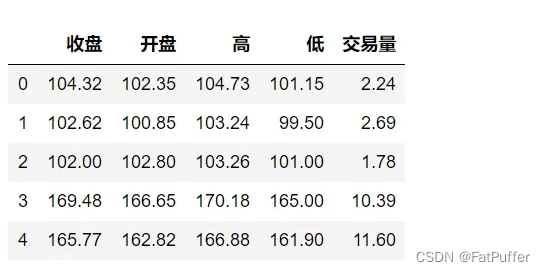
- 将上述数值取整
sub_df.applymap(lambda x: int(x))
sub_df
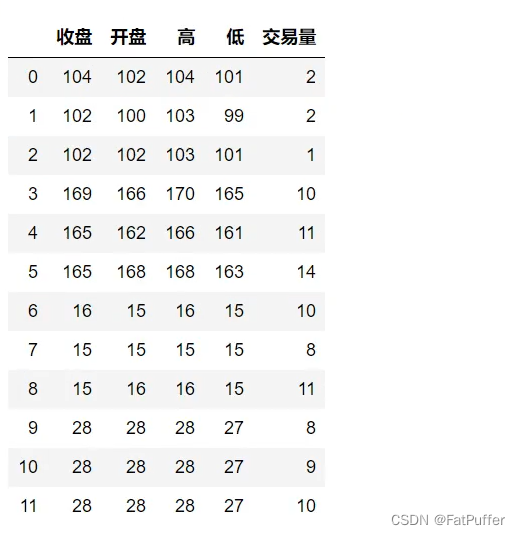
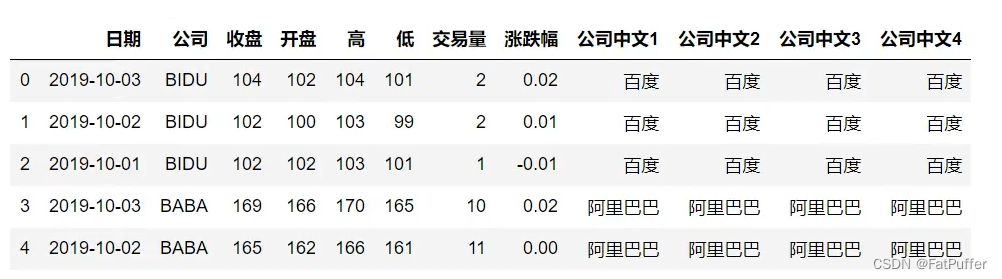
- 方法二:
stocks.loc[:, ["收盘", "开盘", "高", "低", "交易量"]] = sub_df.applymap(lambda x: int(x))
stocks.head()
19.Pandas对groupby后的数据应用apply
1.图解说明
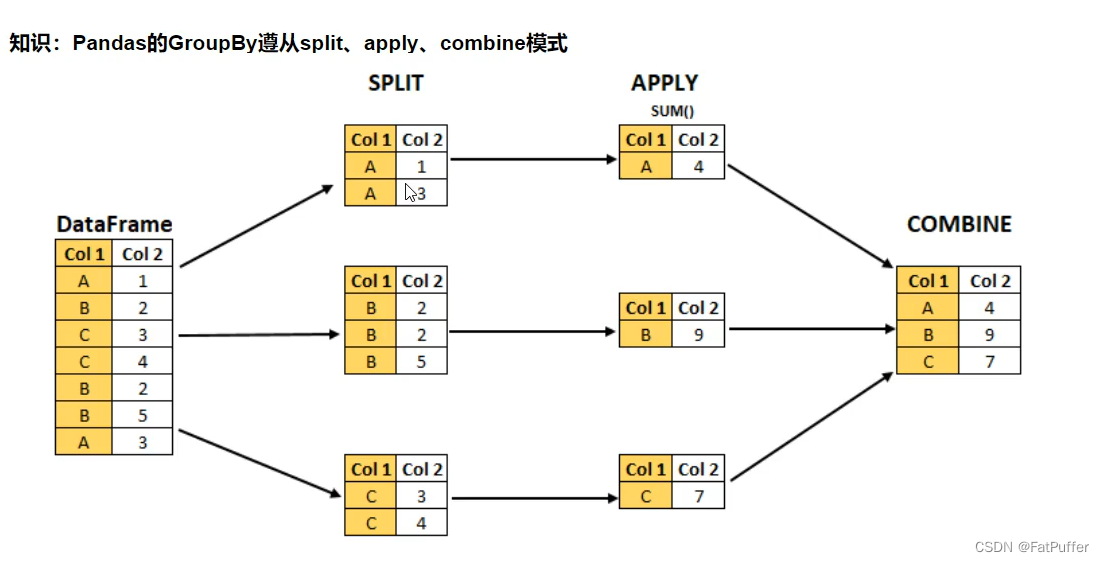
2.GroupBy(function)
function的第一个参数是dataframefunction的返回结果,可以是dataframe、series、单个值,甚至和输入DataFrame完全没有关系
3.实例演示
1.怎样对数值列按分组的归一化
- 1.归一化:将不同范围的数值进行归一化,映射到【0-1】区间
- 更容易做到数据的横向对比,比如价格字段是几百到几千,增幅字段是0到100
- 机器学习模型学的更快,性能更好

- 2.用户对电影评分的归一化
import pandas as pd
ratings = pd.read_csv(
"./data/ratings.dat",
sep="::",
engine="python",
names="UserID::MovieID::Rating::Timestamp".split("::")
)
ratings.head()
- 实现按照用户ID分组,然后对其中一列归一化
def ratings_norm(df):
min_value = df["Rating"].min()
max_value = df["Rating"].max()
df["Rating_norm"] = df["Rating"].apply(lambda x: (x - min_value) / (max_value - min_value))
return df
ratings = ratings.groupby("UserID").apply(ratings_norm)
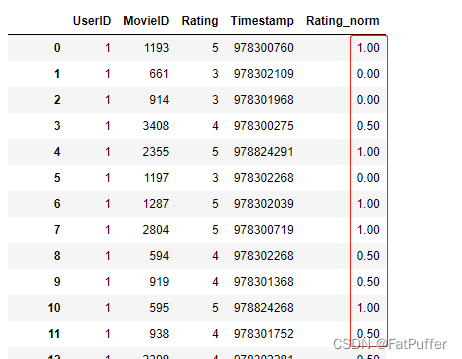
ratings[ratings["UserID"] == 1].head()
2.怎样获取每个分组的TOPN数据
fpath = "./data/beijing_tianqi_2018.csv"
df = pd.read_csv(fpath)
# 替换温度后面的 °C
df.loc[:, "bWendu"] = df["bWendu"].str.repace("°C", "").astype("int32")
df.loc[:, "yWendu"] = df["yWendu"].str.repace("°C", "").astype("int32")
# 增加一列月份
df["month"] = df["ymd"].str[:7]
df.head()
def getWenduTopN(df, topn):
"""
df: 每个月份分组group的df
"""
# df.sort_values(by="bWendu"):按高温一列升序排序
# [["ymd", "bWendu"]]:取年月日和高温两列数据
# [-topn:]:因为是升序,所以取-topn
return df.sort_values(by="bWendu")[["ymd", "bWendu"]][-topn:]
df.groupby("month").apply(getWenduTopN, topn=2).head()
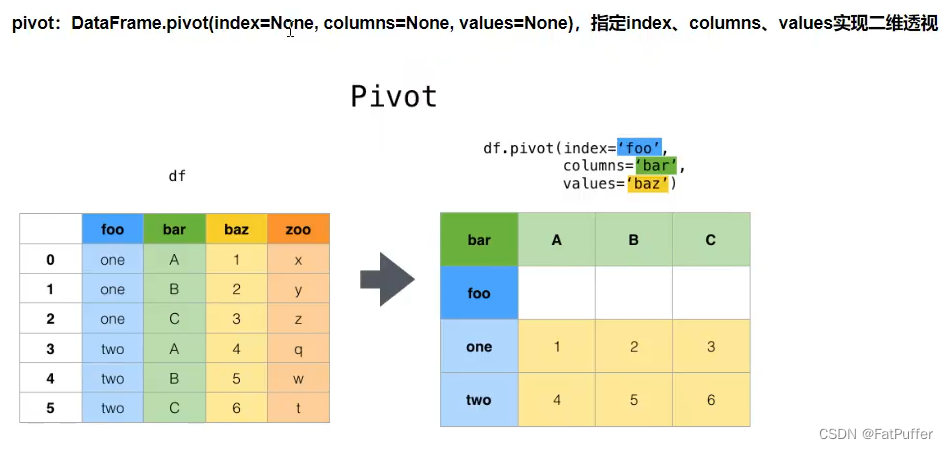
20.Pandas使用stack和pivot实现数据透视
1.作用
- 将列式数据变成二维交叉形式,便于分析,叫做重塑或透视
2.流程
- 1.经过统计得到多维度指标数据
- 2.使用unstack实现数据二维透视
- 3.使用pivot简化透视
- 4.stack、unstack、pivot的语法
3.经过统计得到多维度指标数据
1.实例:统计得到电影评分数据集,每个月份的每个分数被评分多少次(月份、分数1-5、次数)
- 1.读取数据
import pandas as pd
import numpy as np
%matplotlib inline
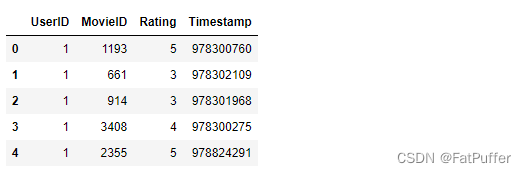
df = pd.read_csv(
"./data/ratings.dat",
header=None,
sep="::",
engine="python",
names="UserID::MovieID::Rating::Timestamp".split("::")
)
df.head()
- 2.增加一列时间日期
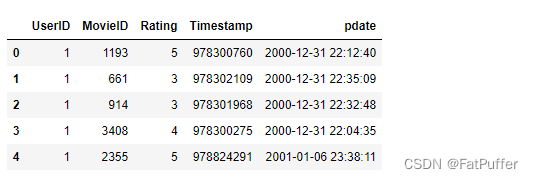
# 增加一列时间日期,由秒格式的Timestamp字段转换而来
df["pdate"] = pd.to_datetime(df["Timestamp"], unit="s")
df.head()
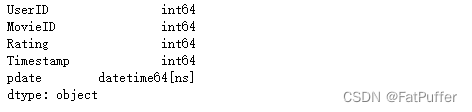
- 3.查看各个字段类型
df.dtypes
- 4.实现数据统计
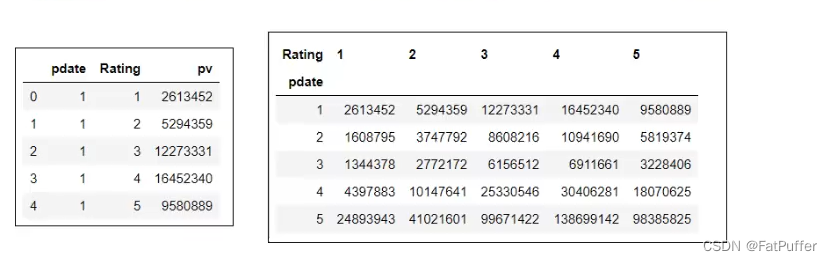
- 1.统计
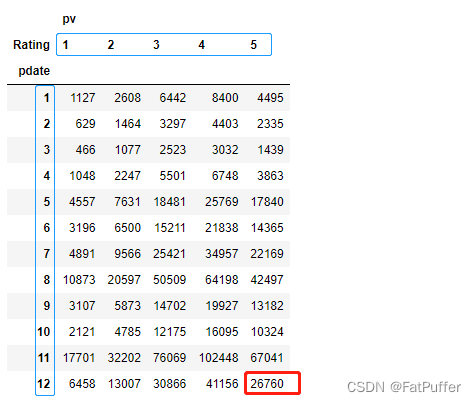
# 按照月份和评分分组,创建两个索引,取Rating这个series,统计后倒序排列(方便验证结果)
df_group = df.groupby([df["pdate"].dt.month, "Rating"])["Rating"].agg({"pv": np.size}).sort_values("pdate", ascending=False)

- 2.验证12月份5分的评价有多少条
- 1.新增一列月份
df["month"] = df["pdate"].dt.month - 2.过滤12月份评分为5分的数据,按照评分统计条数
df[(df["Rating"] == 5) & (df["month"]==12)]["Rating"].value_counts() - 3.得到结果为:
5 26760 Name: Rating, dtype: int64
- 1.新增一列月份
2.使用unstack实现数据二维透视
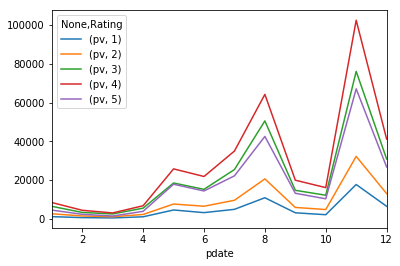
- 1.使用
unstack实现透视
df_stack = df_group.unstack()
df_stack.plot()
- 2.使用
stack还原
df_stack.stack().head()

3.使用pivot简化透视
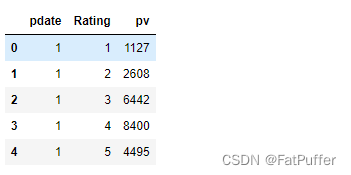
df_group.head(20)

df_reset = df_group.reset_index()
df_reset.head()
df_pivot = df_reset.pivot("pdate", "Rating", "pv")
df_pivot.head()
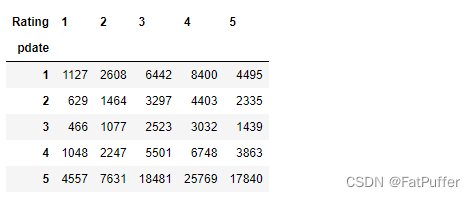
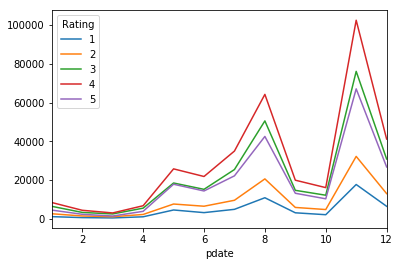
df_pivot.plot()
4.stack、unstack、pivot的语法
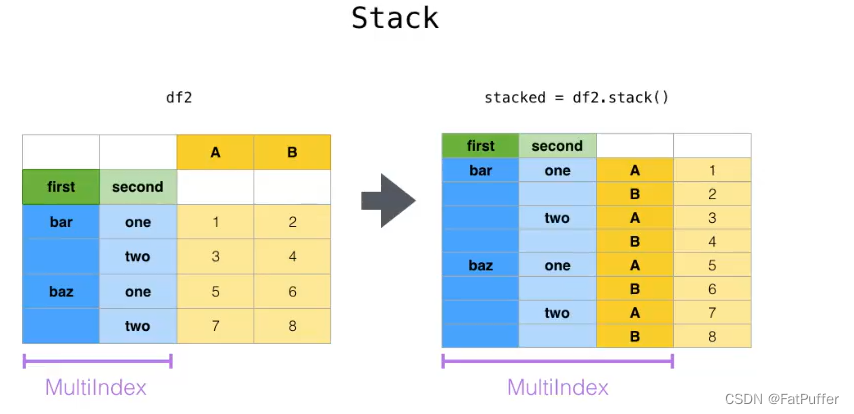
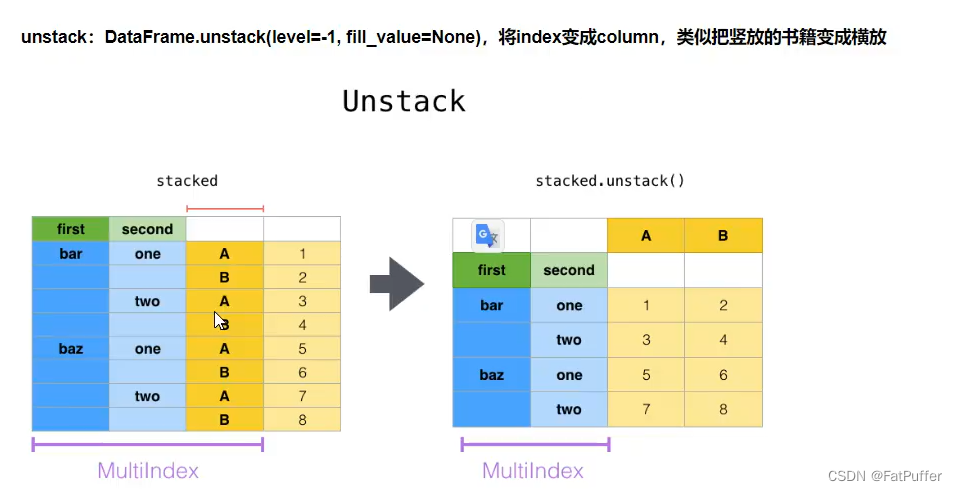
pivot:方法相当于对df使用set_index创建分层索引,然后使用unstackstack:DateFrame.stack(level=-1, dropna=True),将column变成index,类似把横放的书籍变成竖放level:-1代表错层索引的最内层,可以通过0、1、2指定多层索引对应的层
版权声明:本文为qq_42517220原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。