声明:本博客只是简单的爬虫示范,并不涉及任何商业用途。
一.前言
前段时间春节,博主有幸去电影院看了热映的几部电影,但是我想了解下大多数人对电影的看法,于是我便想到了爬虫,由于之前爬过豆瓣和知乎,这次我将爬虫对象改为了猫眼电影。我针对猫眼上的近期热映电影的评论等数据进行了爬取,并将结果进行了简单的可视化,下面是对本次爬虫过程的记录,希望能给大家有所启迪。
二.网页分析
首先我在电脑端打开猫眼官网,结果发现在其上面并没有影评数据,通过查询其他大佬的文章,我发现了猫眼电影的评论接口(参考于文章爬虫实战:猫眼《流浪地球》影评数据爬取和分析):
https://m.maoyan.com/movie/movie_id/comments?_v_=yes
其中movie_id为待爬取的电影的id,可以在猫眼官网首页获取,例如《人潮汹涌》的id为1300936,即《人潮汹涌》影评数据的接口为:
https://m.maoyan.com/movie/1300936/comments?_v_=yes
在浏览器中贴入该链接可以看到如下界面:
点击F12键,不断进行下拉可以看到评论数据所在的json如图:
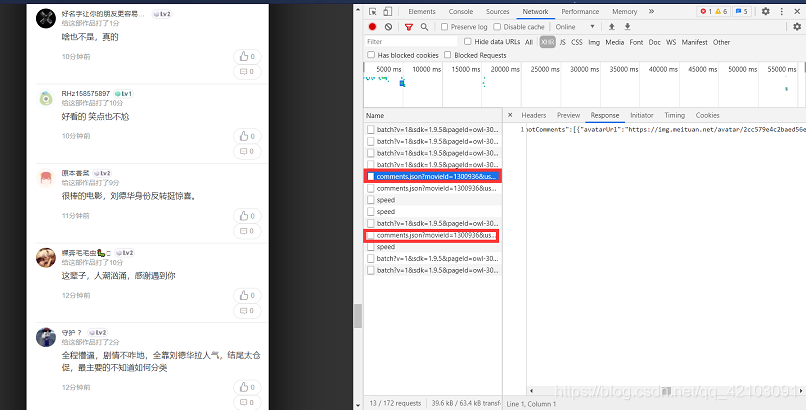
复制一个json数据连接下来如下:
https://m.maoyan.com/review/v2/comments.json?movieId=1300936&userId=-1&offset=15&limit=15&ts=1614503804212&type=3&optimus_uuid=CDD8C6B0775A11EB869539E04D007BD066D8CA91D8354B5C9BE678701804B84C&optimus_risk_level=71&optimus_code=10
多观测几个链接发现只有ts、offset等字段发生变化。对于ts字段,我通过时间戳在线转换工具得到如下结果:

从转换结果来看显然是有问题的,但我发现将该数字除以1000再进行转换发现结果正确,如图:

而对于offset字段可以明显看出其值每翻一页增加15。
三.爬虫具体过程
基于以上分析即可以确定爬虫的核心思路:先去猫眼主页获取热映电影的id,然后通过上述发现的字段变换规律去构造相应的链接即可获取对应的评论的json数据。
爬虫库的选择:requests,BeautifulSoup;
3.1 获取热映电影ID
首先打开猫眼电影主页,选中一部热映电影右键检查,可以看到电影id和电影名所在的位置如下图所示:
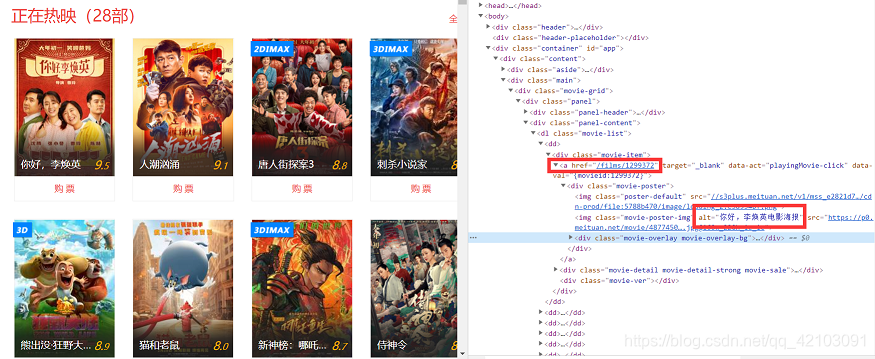
通过BeautifulSoup我们即可过滤出这些字段出来,详情参见get_hit_movieid.py,这里不做详细介绍。
3.2 构造链接
有了上述的规律,电影评论的json数据的获取其实很简单了,示例如下:
# movieId为待爬取的电影ID
# i为爬虫的页数,从0开始
# ts为获取的时间戳需要乘以1000
ts = time.time()
url = 'https://m.maoyan.com/review/v2/comments.json?movieId={}&userId=-1&offset={}&limit=15&ts={}&type=3&optimus_uuid=CDD8C6B0775A11EB869539E04D007BD066D8CA91D8354B5C9BE678701804B84C&optimus_risk_level=71&optimus_code=10'.format(self.movieId,i*15,int(ts*1000))
3.3 影评数据提取
通过构造的链接我们可以获取包含影评数据的json文件,然后利用json模块进行加载,然后便可以轻易获取自己想要的字段。
3.4 爬虫的优化措施
在爬虫的过程中具体采用的优化措施如下:
- 利用fake_useragent来获取不同的UserAgent,传入获取json数据那里对应的cookie;
- 为了加快爬虫速度,这里采用了多线程方式(通过threading模块实现),这里将每部热映电影分配一个线程进行影评数据爬虫;
3.5 数据的保存
影评数据通过Pandas模块保存为csv文件,其中包含5列数据分别为:
- id:用户id;
- content:评论内容;
- nick:昵称;
- score:用户电影打分;
- startTime:评论时间;
3.6 注意事项
由于猫眼的反扒措施,好像每部电影最多一次只能爬取1000条左右的评论数据,但是在不同时间段内可以爬到不同的影评数据,因此可以通过该种方式来获取更多的影评数据。
四.爬虫部分代码及可视化展示
4.1 爬虫主程序代码
import json
import time
import random
import requests
import traceback
import pandas as pd
from fake_useragent import UserAgent
from get_hit_movieid import getMovies,headers
from proxy_ip import ExtractIP
import threading
ua = UserAgent()
class MaoYanSpider(threading.Thread):
def __init__(self,movie_name,movieId,nums,threadname,IPs=None,append=False) -> None:
threading.Thread.__init__(self, name=threadname)
self.movieId = movieId
self.nums = nums
self.movie_name = movie_name
self.IPs = IPs
self.append = append
def run(self):
"""
爬虫主程序
self.movieId:待爬取电影的id
self.nums:待爬取的页数
self.IPs:代理IP列表
"""
clist = []
t = self.nums // 15
for i in range(nums):
try:
print('{} is clawling the {}st page'.format(self.getName(),i + 1))
ts = time.time()
url = 'https://m.maoyan.com/review/v2/comments.json?movieId={}&userId=-1&offset={}&limit=15&ts={}&type=3&optimus_uuid=CDD8C6B0775A11EB869539E04D007BD066D8CA91D8354B5C9BE678701804B84C&optimus_risk_level=71&optimus_code=10'\
.format(self.movieId,i*15,int(ts*1000))
# print(url)
# 设置代理IP
if self.IPs is not None:
index = random.randint(0,len(self.IPs) - 1)
proxies = {"http":"{}:8080".format(self.self.IPs[index])}
response = requests.get(url=url,headers=headers,proxies=proxies)
else:
proxies = {"http":"{}:8080".format('41.207.251.198')}
response = requests.get(url=url,headers=headers,proxies=proxies)
# with open('temp.html','w',encoding='utf-8') as fp:
# fp.write(response.text)
outcome = self.phrase(response.text)
# 爬取空列表则停止(猫眼爬虫有条数限制)
if outcome == []:break
clist += outcome
time.sleep(1.5)
except Exception:
traceback.print_exc()
pass
self.Saver(clist,self.append)
def phrase(self,data):
"""
解析获取的影评数据(json格式)
data:文本数据
"""
outcome = []
js_data = json.loads(data)
comments = js_data.get('data').get('comments')
if comments != None:
for comment in comments:
id = comment.get('id') # 电影ID
content = comment.get('content') # 评论的内容
nick = comment.get('nick') # 评论人的昵称
score = comment.get('score') # 评论的分数
startTime = comment.get('startTime') # 开始时间
print(id,content,nick,score,startTime)
outcome.append([id,content,nick,score,startTime])
return outcome
def Saver(self,clist,append=False):
"""
功能:保存评论为csv文件
clist:获取的数据
append:是否为追加文件到原有的文件中去
"""
datas = pd.DataFrame(clist,columns=['id','content','nick','score','startTime'])
if append:
datas.to_csv('datas/{}.csv'.format(self.movie_name),index=False,header=False,mode='a')
else:
datas.to_csv('datas/{}.csv'.format(self.movie_name),index=False)
if __name__ == "__main__":
movies = getMovies()
IPs = ExtractIP()
IPs = None if IPs == [] else IPs
i = 1
for k,v in movies.items():
movie_name = k
movieId,nums = v[0],v[1]
print(movie_name,'\t',movieId,'\t',nums)
threadname = 'spider{}'.format(i)
spider = MaoYanSpider(movie_name,movieId,nums,threadname,IPs,append=True).start()
i += 1
4.2 影评数据可视化
4.2.1 电影评分情况圆环图
对于电影的评分情况也是通过Pandas模块来进行获取,具体通过groupby函数来按评分等级进行分组然后统计,最后将0~5分的总结在了一起,代码如下所示:
def scoreDistribution(df):
"""
获取评分及评分人数
df:dataframe形式数据
"""
mdata = df[['score','id']].groupby('score').count()
score_nums = mdata['id'].tolist()[6:]
labels = mdata.index.tolist()[6:]
# 合并5分以下的
score_nums.insert(0,mdata.loc[0:5,:].sum().values.item())
labels.insert(0,'0~5')
return score_nums,labels
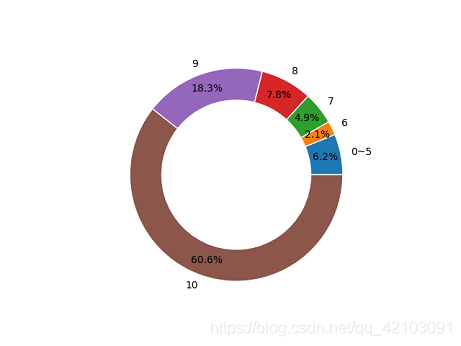
然后通过Matplotlib模块的pie函数来进行了8部热映电影的圆环图的绘制,下面挑选《人潮汹涌》的图来进行展示:
4.2.2 评论数据词云图
对于词云图的绘制,先需要利用jieba分词来对影评内容进行分词,然后利用wordcloud模块来进行词云图的绘制,这里同样展示《人潮汹涌》的词云:

从上述数据可以看出大多数人都人潮汹涌打分颇高,认为这是一部值得观看的电影,同样作为一名观影者,我也持有同样的看法。
五.结语
完整项目Github地址(求star):maoyan_movie_commit
由于获取的数据不多,因此上述的结果并不具有权威性,仅仅是作者的自娱自乐。以上便是本文的全部内容,要是觉得不错的话就点个赞或关注一下博主吧,你们的支持是博主继续创作的不解动力,当然若是有任何问题也敬请批评指正!!!