个人公众号:linux进击之路
网络协议栈即OSI通信模型在linux内核的描述,又叫网络子系统。网络协议栈是实现客户端和服务端通信的基础。本文内容基于2.6.9版本,主要从报文收发的流程上一步步讲解应用层套接字发送的数据是如何发送给对端,以及如何从套接字上读取到数据的。
我们淡化OSI模型中的物理层以及应用层的处理流程,主要展开说明数据链路层到传输层的逻辑,如下图所示。
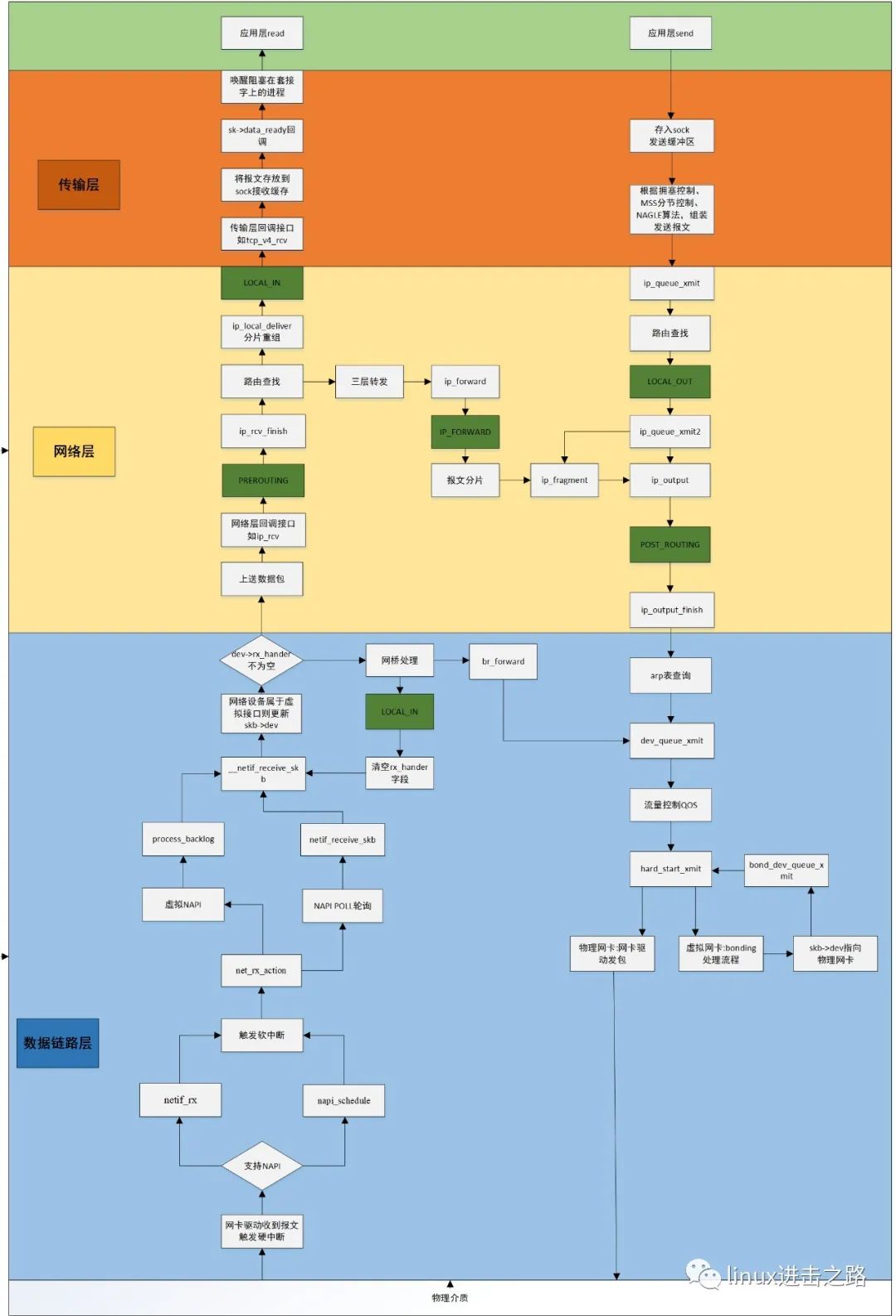
一、数据链路层接收处理报文
数据通过物理链路传输到网卡时,会存到网卡的内存空间内(每个网卡在内核中都对应一个网络设备,由net_device结构体表示),并且触发硬中断信号,内核收到信号后,开始执行硬中断处理函数。对于不支持NAPI机制的老网卡,通常调用netif_rx接口将报文存到CPU的接收队列(报文采用sk_buff结构来存储);支持NAPI的网卡,中断处理函数会将报文存储到napi结构的接收队列中。两种机制最终都会在硬中断处理函数中触发软中断,进入软中断处理流程。硬中断处理属于中断上半部,软中断处理逻辑属于中断下半部。
为了提升中断效率,内核采用中断+轮询的机制来处理报文,即软中断触发后,在软中断回调函数中,循环调用napi的轮询接口处理报文。在内核中,软中断是在网络设备初始化(net_dev_init)时,注册回调处理函数net_rx_action,该函数中会执行网卡的poll轮询接口处理网卡接收到的报文。最终调用netif_receive_skb接口(接收报文处理主函数)。
linux内核支持很多虚拟化技术,网络设备虚拟化是其中一种,如果接收报文的物理网络设备和虚拟的网卡绑定了,那么在netif_receive_skb接口中,会将skb->dev字段切换到虚拟网络设备上。同时,如果该skb->dev指向的网络设备挂接在网桥上面,那么skb->dev->rx_hander字段将不会为空指针,报文将会送到网桥中,由rx_hander指向的回调函数来处理报文。如果网桥判断报文二层头部的MAC地址是本地ip,那么会将rx_hander字段置空,重新进入netif_receive_skb处理流程,此时,报文会调用网络层给链路层注册的报文接收回调接口,对于ip协议,其回调接口为ip_rcv,处理流程见第二章节;如果网桥在本地存储的MAC转发表中,找到了报文对应的MAC,那么报文将会进入桥转发流程,由br_forward来执行。
二、网络层接收处理报文
内核启动过程中,会调用inet_init接口初始化网络,初始化过程中,调用dev_add_pack接口注册网络层协议接收报文的回调接口。以ip协议为例,netif_receive_skb接口判断报文是上送协议栈时,会执行ip_rcv接口进入网络层的处理流程。该函数经过ip头部校验后,会进入网络协议栈的第一个NETFILTER HOOK点——PREROUTING,除了网桥内部的HOOK点外,整个协议栈共有5个HOOK点,联合起来构成了网络防火墙机制,用户态可通过iptable命令来配置防火墙规则,可通过规则决定满足规则的报文该如何处理(丢弃、修改、允许通过),本文对此不深入探讨。
如果用户态没有指定对应的hook函数,那么报文会进入ip_rcv_finish接口,该接口主要功能是进行路由查找(ip协议主要功能之一),路由项决定着报文的下一步走向。大家都知道服务端和客户端通信之前,必须通过socket接口创建套接字并且绑定ip地址,内核会根据这个ip地址创建路由表项,以便收到报文后,知道报文该如何处理,如何应用层没有绑定报文ip头部的目的ip地址,那么报文将会进入三层转发流程,进入ip_forward接口中,进行分片(非必须)发送。
对于本地上送的报文,会进入ip_local_deliver接口,该接口实现ip协议的另一个主要功能——报文重组,根据ip头部的MF字段以及offset来重组ip报文负载,如何LOCAL_IN HOOK点没有限制报文,报文将在ip_local_deliver_finish接口中,获取ip头部记录的协议类型,该协议类型表征传输层使用的协议类型,根据该类型查找传输层协议回调接口,类似于ip协议的注册,传输层协议也是在inet_init接口内,通过inet_add_protocol接口来注册的,其报文回调接收函数为tcp_v4_rcv,开启传输层收报流程。
三、传输层接收处理报文
前文说过通信的前提必须在应用层创建socket,该socket是BSD socket,面向的是用户态,内核态不会使用,因此,创建socket的同时,会在内核态创建sock结构体的变量,供内核使用(主要是传输层使用)。sock结构非常重要,我们所说的套接字接收缓冲区和发送缓冲区,其实都是sock结构体的成员变量,该结构还记录这tcp socket的状态(监听、已连接、TIME_WAIT),监听队列和已连接队列。所以,当报文进入传输层回调接口后,会通过报文头部信息查询缓存的sock结构,根据其状态做不同的处理。对于已连接套接字,报文会进入接收队列中(tcp对应四个接收队列,用于处理报文乱序、应用层进程正在读取或者以及休眠时报文的存放问题)。后续安排专题讲解tcp收发报文的流程,本文重在说明报文接收流程,细节暂不展开。最终,报文进入接收缓冲区后,通过sk_data_ready回调接口唤醒阻塞在套接字上的进程读取数据(如果未指定等待队列的标记未EXCLUSIVE,那么在并发场景下会引起惊群效应,指定该选项后,内核会找到第一个具有该标记的进程并唤醒),最后内核将套接字缓冲区数据拷贝到用户态指定的内存空间。至此,报文的整个接收流程梳理完成。
四、报文发送流程
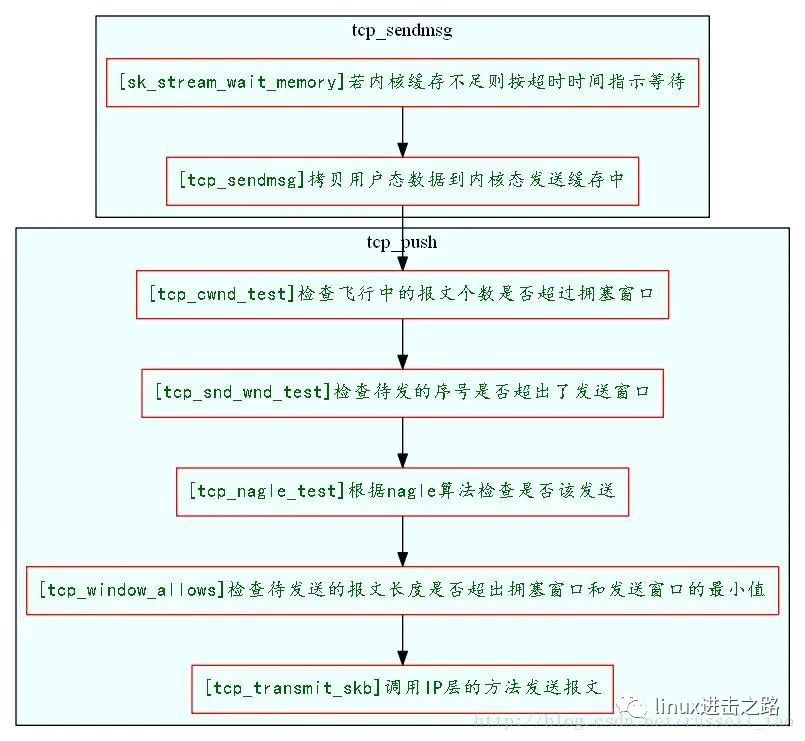
以TCP套接字发包为例,应用层调用write或者send等发送接口发送数据,进入内核空间后,根据tcp socket类型的套接字找到对应的sock结构体,最终会进入tcp_sendmsg接口中处理报文。该接口会判断sock的发送缓冲区是否有足够空间,空间不足时会按照超时时间等待(应用层发送时,如果指定了MSG_DONTWAIT标记,那么等待时间为0)。发送缓冲区空闲空间足够时,将用户态的数据拷贝到sock的发送缓冲区中(sock结构体中维护sk_write_queue和sk_send_head两个指针,来记录报文的发送,前者表示发送队列双向链表的表头,后者表示下一个待发送的报文),并填充到skb中(存报文的结构)。发送时,tcp_cwnd_test接口根据拥塞窗口的规则,限制本次允许发送报文的大小,并且在tcp_snd_wnd_test接口中校验序列号是否超过发送窗口,满足条件时,就会进入tcp_nagle_test接口,根据nagle算法判断报文是否立即发送。检测条件都满足时,最终会在tcp_transmit_skb接口中,填充skb中tcp头部数据,调用ip层发送报文接口ip_queue_xmit,传输层流程简图如下。
数据包传递到网络层后,ip协议处理流程先查找路由项,确定发送接口,并填充skb->dst目的缓存项和skb中ip头部数据,如果报文长度加上头部长度超过MTU的值,那么会执行分片动作。最后通过路由项记录的发送接口发送报文即ip_output。在ip_output接口中,查找路由缓存项记录的网络设备(net_device结构体,决定着最终从哪个网卡发送数据),填充到skb->dev字段中。然后根据ip地址查找arp表(又称邻居表),找到硬件头部缓存(hh_cache结构),填充到skb的MAC头部,调用dev_queue_xmit发送报文(接收的报文如果时二层转发,也会进入到该接口),进入数据链路层处理逻辑,这里忽略流量控制的逻辑(还没看懂 ),最终调用网卡驱动的hard_start_xmit接口发送报文到物理链路上(如果是虚拟网卡,那么会进入虚拟网卡的处理逻辑,修改skb->dev为物理网卡,最终又回到hard_start_xmit接口)。
),最终调用网卡驱动的hard_start_xmit接口发送报文到物理链路上(如果是虚拟网卡,那么会进入虚拟网卡的处理逻辑,修改skb->dev为物理网卡,最终又回到hard_start_xmit接口)。
好了好了,后面都写不动了,终于体会到了为啥那么多漫画会烂尾了 。
。