
掩码首先映射到卷积特征空间,并由共享特征推理反复进行处理。在特征完全恢复后,生成的特征图被合并在一起(上述省略了图),合并后的特征被转换回一个RGB图像。
区域识别处理和特征推理模块连续进行。经过几次推理后,将特征映射以自适应的方式合并,并生成固定通道数的输出特征映射。该模块是即插即用的,可以放置在现有网络的任意一层。
反复特征推理模块(Recurrent Feature Reasoning Module)
可以划分为三部分:
- 区域识别模块:用于识别在递归中需要推断的区域;
- 特征推理模块:用于推断所识别区域中的内容;
- 特征合并操作:用于合并中间特征映射;
模块内部,区域识别模块和特征推理模块反复交替工作。当缺失区域被完全填充后,推理过程中生成的所有特征图被合并,生成一个具有固定通道号的特征图。
区域识别模块(Area Identification)
采用部分卷积(Pconv)作为基本模块来识别每次递归中要更新的部分;部分卷积层在卷积计算后更新掩膜,并重新对特征映射进行归一化。如下公式所示: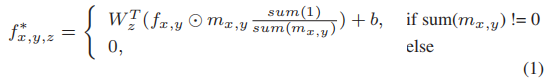
为了接收到新的较小孔洞掩膜,我们采用下述公式: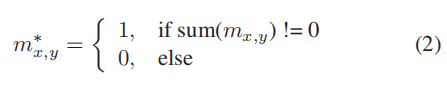
对于RFR模块中的区域识别,我们将多个部分卷积层级联在一起,以更新掩膜和特征图。
经过部分卷积层后,特征映射通过归一化层和激活函数进行处理,然后再被发送到特征推理模块。
我们将更新的掩模和输入掩模之间的差异定义为在这个递归中要推断的区域。在整个重复过程中,更新的掩模中的孔被保留,直到在下一次重复过程中进一步缩小。
特征推理(Feature Reasoning)
在识别出待处理的区域后,通过特征推理模块估计该区域中的特征值。
特征推理模块的目标是用尽可能高质量的特征值填充已识别的区域。
特征推理模块可以设计得非常复杂,以最大化其推理能力。然而,在这里,我们只是简单地堆叠一些编码和解码层,并使用跳过连接来桥接它们,这样我们就可以直观地显示特征推理模块的效率。由于RFR模块不限制中间结果的表示,更新后的掩码和部分推断的特征映射被直接发送到下一个递归点,而无需进一步处理。
特征合并(Feature Merging)
当特征映射被完全填充时,特征映射已经多次通过特征推理模块。如果我们直接使用最后一个特征图来生成输出,可能会发生梯度消失,在早期迭代中产生信号会被损坏。为了解决这个问题,我们必须合并中间特征映射。
但是,使用卷积操作限制了递归的次数,因为连接中的信道数量是固定的。
由于不同特征图中的孔区域不一致,突出的信号被平滑,直接将所有特征映射相加去除图像细节。因此采用了一个自适应的合并方案来解决这个问题。输出特征映射中的值仅从对应位置的特征映射中计算,如下公式: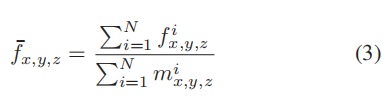
图像的除法与乘法一样可以调节图像的明亮度,图像间的除法则与减法一样可以发现图像的异同点,只是使用上存在些限制,一般情况下效果也没有减法那么好。
KCA注意力模块(Knowledge Consistent Attention)
在图像补全中,利用注意力模块可以合成较好的特征。注意模块在背景中搜索可能的纹理,并使用它们来替换孔中的纹理。
然而,直接将现有的注意力模块插入到RFR中是次优的,因为不同递归(重复操作)中的补丁交换过程是独立执行的。
KCA的注意力分数是自适应地从以前和当前的注意力分数中计算出来的,以确保特征成分的一致性。
与之前的注意机制不同,它们注意分数是独立计算的,我们的KCA中的分数是由从之前的重复中按比例累积的分数组成的。
算法细节:
首先计算每对特征像素之间的余弦相似度: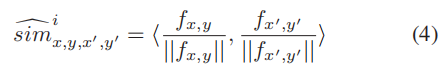
在此之后,我们通过平均相邻区域中目标像素的相似度来平滑注意力得分: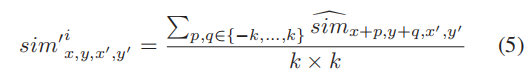
然后,我们使用softmax函数生成位置(x,y)像素的组件比例,生成的得分映射用score’表示。
为了计算一个像素的最终注意力得分,我们首先决定是否引用前一次递归中的该像素的得分。
给定一个被认为有效的像素,其当前递归的注意力得分分别计算为当前和以前递归的原始和最终得分的加权和。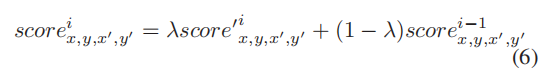
s c o r e x , y , x ′ , y ′ ( i − 1 ) score ^ {(i-1)}_{x,y,x',y'}scorex,y,x′,y′(i−1)表示最后一次递归的得分,因为最后一次递归掩膜表示为m x , y i − 1 m^{i-1}_{x,y}mx,yi−1。
否则,如果像素在最后一次递归中无效,则不进行额外操作,对当前递归中像素的最终注意评分计算如下: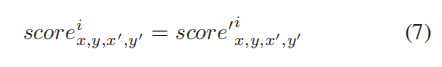
最后,利用注意力评分来重建特征贴图。位置(x, y)的新特征图计算如下: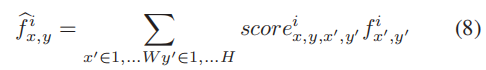
重建特征后,将输入特征F FF和重建特征F ^ \hat{F}F^拼接起来,并发送到卷积层: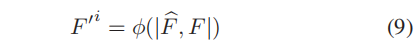
F ′ F'F′是重建的特征图,ϕ \phiϕ是像素级卷积操作。
模型结构和损失函数
在我们的实现中,我们分别在反复特征推理模块(RFR模块)前后放置了2个和4个卷积层。
手动选择重复的次数IterNum为6,KCA模块被放置在RFR模块的特征推理模块最后一层的第三个位置。
For image generation learning, the perceptual loss and style loss from a pre-trained and fixed VGG-16 are used.
对于图像生成学习,采用了固定VGG-16预训练模型参数的感知损失和风格损失,感知损失和样式损失比较了生成图像的深度特征图与ground truth之间的差异。这种损失函数可以有效的让模型学习图像的结构和纹理信息。这些损失函数的形式如下。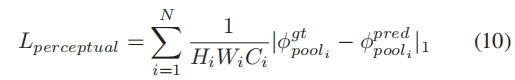

风格损失的计算公式如下: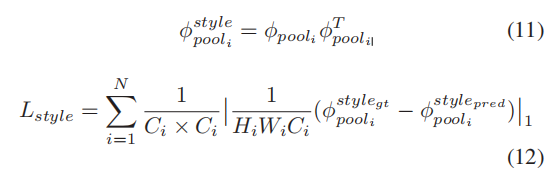
总的损失函数:
类似的对这篇文章的解读博客:
https://blog.csdn.net/weixin_39298213/article/details/112617957