目录
1 xml文件
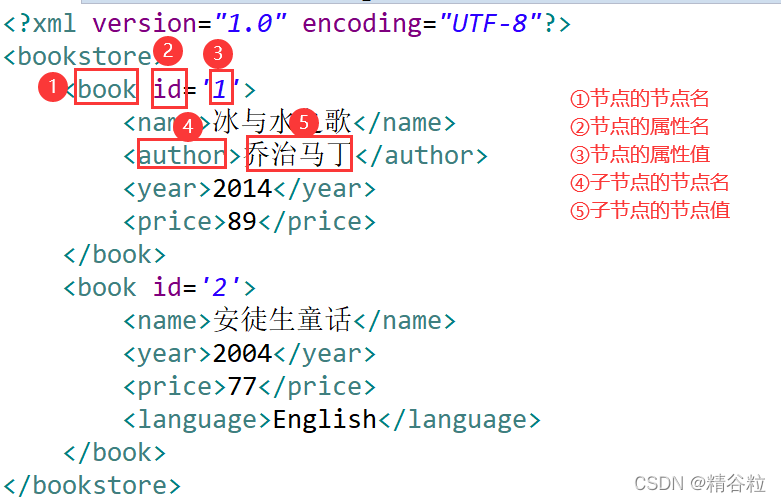
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book id='1'>
<name>冰与水之歌</name>
<author>乔治马丁</author>
<year>2014</year>
<price>89</price>
</book>
<book id='2'>
<name>安徒生童话</name>
<year>2004</year>
<price>77</price>
<language>English</language>
</book>
</bookstore>分析如下:
2 DOM解析代码实现
2.1 DOM解析步骤
步骤1:使用org.w3c.dom库的newInstance()方法创建一个DocumentBuilderFactory对象
步骤2:使用newDocumentBuilder()方法创建一个DocumentBuilder对象
步骤3:使用parser()方法加载books.xml文件到当前项目
步骤4:使用getElementsByTagName("book")获取book节点,返回NodeList节点集合对象
步骤5:获取节点book的属性名,属性值
1)首先,遍历每一个book节点
①通过nodeList的getLength()方法可以获取根节点集合bookList的长度
②使用for循环遍历节点集合中的每一个book节点
2)然后获取每一个book节点的属性名和属性值,这时候有两种方式
方式一:不知道book节点有哪些属性时候,用以下方法
①使用item()的方法获取一个book节点的具体属性,返回Node类型
②使用getAttributes()获取book节点的所有属性集合,返回NamedNodeMap类型
③通过attrs的getLength()方法可以获取属性集合的长度
④使用for循环遍历一个book节点的属性
⑤使用item()方法获取books节点属性集合中的每一个属性,返回Node类型
⑥使用getNodeName()方法获取属性的属性名
⑦使用getNodeValue()方法获取属性的属性值
方式二:知道book节点只有id一个属性的时候,用以下方法
①将book节点进行强制类型转换,转换成Element类型
②通过getAttribute("id")获取属性值
步骤6:获取book节点的子节点的节点名和节点值
这里需要补充一个知识点,就是节点类型
| 节点类型 | NodeType | Named Constant | nodename的返回值 | nodeValue的返回值 |
| Element | 1 | ELEMENT_NODE | element name | null |
| Attr | 2 | ATTRIBUTE_NODE | 属性名称 | 属性值 |
| Text | 3 | TEXT_NODE | #text | 节点内容 |
由于节点总数是算了空格和换行符的,所以要把TEXT_NODE以及ELEMENT_NODE区分开来,此处使用判断语句,只选择ELEMENT_NODE
1)首先,使用getChildNodes()方法获取book节点的所有子节点(子节点集合)
2)然后,遍历getChildNodes获取每个节点的节点名和节点值(节点数是包括空格和换行符)
①由于节点数是包括空格和换行符的,所以要把TEXT_NODE以及ELEMENT_NODE区分开来,此处使用判断语句,只选择ELEMENT_NODE。
②通过.item(k).getNodeName()方法获取book每一个子节点的节点名
③获取Element类型节点的节点值
备注:所有的ELEMENT_NODE类型的节点值都是null,那么如何获取它的节点值呢?
方法一:获取getFirstChild()的节点值,相当于它把它的节点值当做了子节点
- 用此方法,如果是<name>>冰与水之歌</name>,那么就会返回冰与火之歌
- 用此方法,如果是<name><a>aa</a>冰与水之歌</name>,那么就会返回null
方法二:使用getTextContent()方法获取这个节点所有属性值以及它子节点的属性值
- 用此方法,如果是<name>>冰与水之歌</name>,那么就会返回冰与火之歌
- 用此方法,如果是<name><a>aa</a>冰与水之歌</name>,那么就会返回aa冰与火之歌
2.2 DOM解析代码实现
package com.wl.domtest.test;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class DOMTest {
public static void main(String[] args) {
//步骤1:使用org.w3c.dom库的newInstance()方法创建一个DocumentBuilderFactory对象
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
try {
//步骤2:使用newDocumentBuilder()方法创建一个DocumentBuilder对象
DocumentBuilder db = dbf.newDocumentBuilder();
//步骤3:使用parser()方法加载books.xml文件到当前项目
Document document = db.parse("books.xml");
//步骤4:使用getElementsByTagName("book")获取book节点,返回的是NodeList对象,也就是节点集合(book不止一本书)
NodeList bookList = document.getElementsByTagName("book");
//步骤5:获取节点book的属性名,属性值
//首先,遍历每一个book节点
//通过nodeList的getLength()方法可以获取bookList的长度
//1)通过nodeList的getLength()方法可以获取根节点集合bookList的长度
System.out.println("一共有"+bookList.getLength()+"本书");
//遍历每一个book节点
for (int i=0;i<bookList.getLength();i++) {
System.out.println("=======下面开始遍历"+(i+1)+"本书的内容=======");
//这时候分为两种方法:一是不知道book节点有哪些属性时,用以下方法
//①使用item()的方法获取一个book节点的具体属性,返回Node类型
Node book = bookList.item(i);
//②使用getAttributes()获取book节点的所有属性集合,返回NamedNodeMap类型
NamedNodeMap attrs = book.getAttributes();
//③通过attrs的getLength()方法可以获取属性集合的长度
System.out.println("第"+(i+1)+"本书共有"+attrs.getLength()+"个属性");
//④使用for循环遍历一个book节点的属性
for(int j=0;j<attrs.getLength();j++ ) {
//⑤使用item()方法获取books节点属性集合中的每一个属性,返回Node类型
Node attr = attrs.item(j);
//使用getNodeName()方法获取属性的属性名
System.out.println("属性名"+ attr.getNodeName()+"的属性值是"+attr.getNodeValue());
}
//二是不知道book节点只有id这一个属性时,用以下方法
//①将book节点进行强制类型转换,转换成Element类型
// Element book = (Element) bookList.item(i);
// //②通过getAttribute("id")获取属性值
// String attrValue = book.getAttribute("id");
// System.out.println("id属性的属性值为:"+ attrValue);
// System.out.println("=======结束遍历"+(i+1)+"本书的内容=======");
//步骤6:获取book节点的子节点的节点名和节点值
//1)使用getChildNodes()方法获取book节点的所有子节点(子节点集合)
NodeList childNodes = book.getChildNodes();
//2)遍历getChildNodes获取每个节点的节点名和节点值(节点数是包括空格和换行符)
System.out.println("第"+(i+1)+"本书共有"+childNodes.getLength()+"个子节点");
for(int k=0;k<childNodes.getLength();k++ ) {
//①由于节点数是包括空格和换行符的,所以要把TEXT_NODE以及ELEMENT_NODE区分开来,
//此处使用判断语句,只选择ELEMENT_NODE
if (childNodes.item(k).getNodeType()==Node.ELEMENT_NODE){
//②通过.item(k).getNodeName()方法获取book每一个子节点的节点名
System.out.print("第"+(k+1)+"个节点的节点名:"+ childNodes.item(k).getNodeName());
//③获取Element类型节点的节点值,以下两种方法都是,争对具体情况不同使用,此种情况使用任意一个均可
//备注:所有的ELEMENT_NODE类型的节点值都是null,那肯定不是我们想要的效果,那么如何获取它的节点值呢?
//方法一:获取getFirstChild()的节点值,相当于它把它的节点值当做了子节点
System.out.println("的节点值是:"+ childNodes.item(k).getFirstChild().getNodeValue());
//用此方法,如果是<name>>冰与水之歌</name>,那么就会返回冰与火之歌
//用此方法,如果是<name><a>aa</a>冰与水之歌</name>,那么就会返回null
//方法二:使用getTextContent()方法获取这个节点所有属性值以及它子节点的属性值
//用此方法,如果是<name>>冰与水之歌</name>,那么就会返回冰与火之歌
//用此方法,如果是<name><a>aa</a>冰与水之歌</name>,那么就会返回aa冰与火之歌
//System.out.println("--节点值是:"+ childNodes.item(k).getTextContent());
}
}
System.out.println("=======结束遍历"+(i+1)+"本书的内容=======");
}
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
2.3 DOM解析代码运行结果
