一、Tesseract训练
1.下载Tesseract-OCR(相关版本自行选择)
这个就不多说了,可以百度一下。
2.下载jTessBoxEditor(运行环境为java虚拟机)
下载百度下载,有很多。打开文件夹,目录如下。
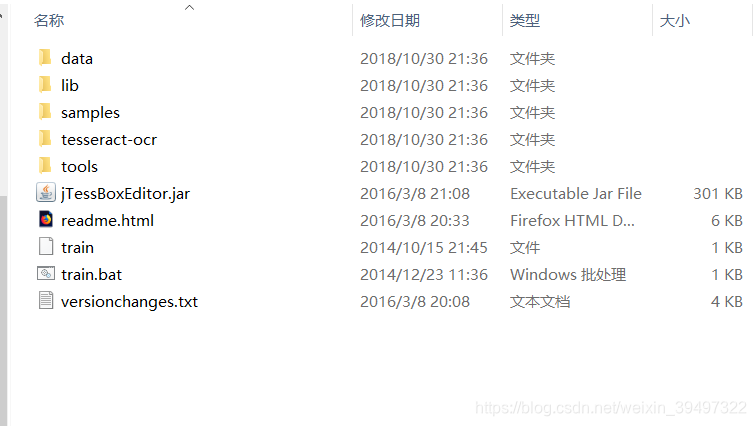
把文件下载到乌班图解压下来。运行jTessBoxEditor.jar 文件,右键终端打开。输入 java -jar jTessBoxEditor.jar

运行程序后出现
3.下面就开始进行训练
基本步骤是 获取样本文件 -> Merge样本文件 –> 生成BOX文件 -> 对样本图片用jTessBoxEditor工具进行矫正 -> 生成font_properties文件 -> 生成.tr训练文件 ->
1)获取样本文件
下载好样本文件;

2)Merge样本文件
先将验证码文件准备好,点击jTessBoxEditor 的 Tools 的Merge_TIFF。这时选择到你样本的目录,注意筛选的格式。全选,然后再填写保存的名。
 确定就在该目录下创建了 test.tif 文件。
确定就在该目录下创建了 test.tif 文件。
3)生成BOX文件
打开在 test.tif 文件目录下打开终端,执行 tesseract test.tif test makebox
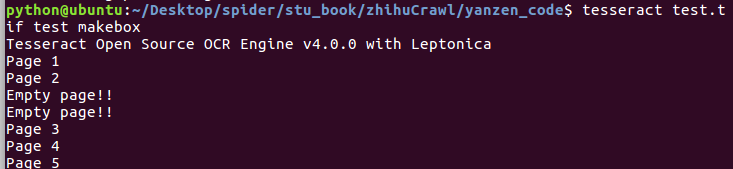
结果生成了test.box文件

4)对样本图片用jTessBoxEditor工具进行矫正
打开jTessBoxEditor,点击 Box Editor 下的 open 。选择刚刚生成的 test.tif
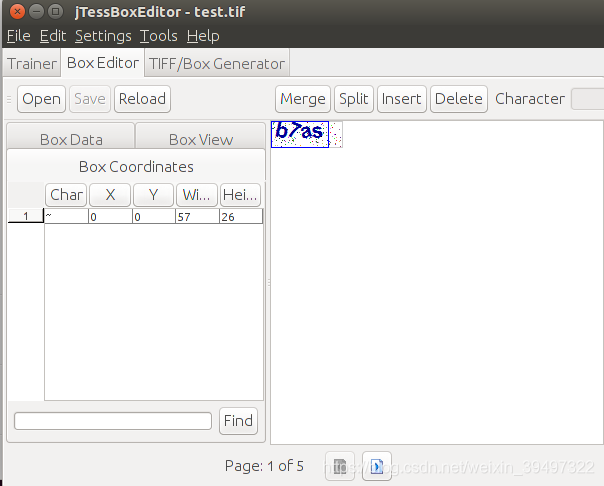
右侧为对应的Box文件数据,如果char的字符和当前的样本图片一致时就进行矫正,修改char里的字符,然后进行save,这样就矫正 了,进入下张样本图片时,同样,矫正后点击save,当所有样本图片都矫正了,这一步也就完成了
5) 生成font_properties文件(该文件没有后缀名)
在命令行执行:echo font 0 0 0 0 0 >font_properties 注意 font 是值创建 字体的名字,下面合并训练文件时 会用到。
结果生成了font_properties文件
内容为字体名font,后面带5个0,分别代表字体的粗体、斜体等属性,这里全部是0
结果生成了font_properties文件
6)生成.tr训练文件
在命令行执行: tesseract test.tif test -l eng --psm 7 nobatch box.train
注意 是 --psm 写一个 - 会报错。 成功就会生成 一下文件

7)生成字符集文件
在命令行执行 : unicharset_extractor test.box
生产 unicharset 文件
8)生成shape文件
在命令行执行 : shapeclustering -F font_properties -U unicharset -O test.unicharset test.tr
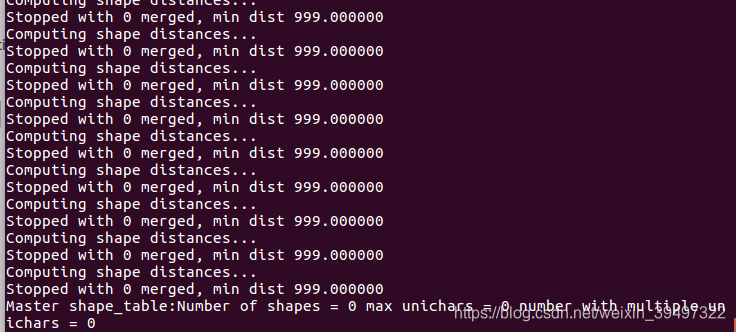
结果生成了shapetable文件和test.unicharset文件
9)生成聚集字符特征文件
在命令行执行: mftraining -F font_properties -U unicharset -O test.unicharset test.tr
结果生成了pffmtable,inttemp,unicharset文件
10).生成字符正常化特征文件
在命令行执行: cntraining test.tr

结果生成了normproto文件
11)把h,i步骤生成的文件用 mv 命令进行更名
mv normproto test.normproto
mv inttemp test.inttemp
mv pffmtable test.pffmtable
mv unicharset test.unicharset
mv shapetable test.shapetable
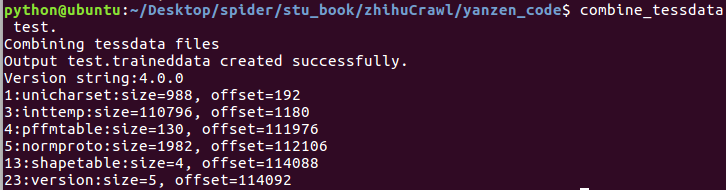
12).合并训练文件
在命令行执行: combine_tessdata test. 注意这里的 font 是与上面的一样。
13) 将fontyp.traineddata文件拷贝至Tesseract-OCR文件夹里的tessdata语言包文件夹里
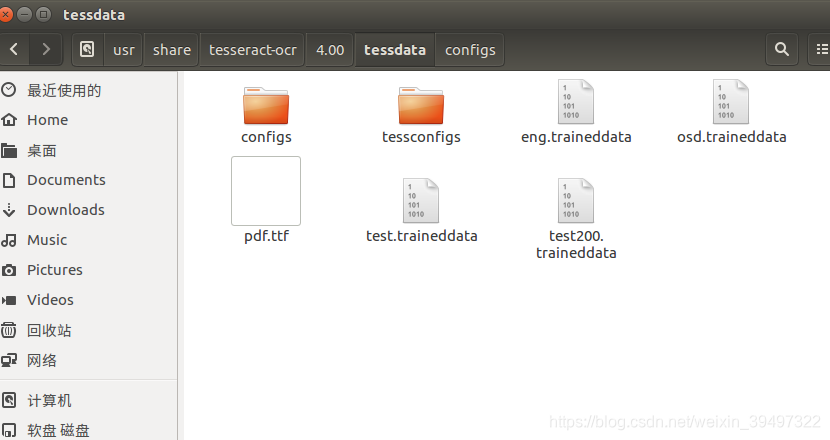
通过 命令 tesseract --list-langs 可以查看查看当前语言包有哪些 这时 发现刚刚新加的 test 添加进去了。
重新验证一遍:
python 代码: lang 参数是你选择的语言包 (afr 是我在下面的连接中下载的) psm是识别强度
import pytesseract
from PIL import Image
image1 = Image.open("yanzen_code/codeFile3.gif")
image1 = image1.convert("RGB")
text = pytesseract.image_to_string(image1,lang='afr',config='--psm 10')
print text参考资料:
1. Tesseract 在 googlecode上的项目,已停止更新,有一些资料,但是还是建议转github
【http://tesseract-ocr.googlecode.com/】
2. Tesseract 在 GITHUB 上的项目
【https://github.com/tesseract-ocr/tesseract】
3. 如何编译自己的Tesseract项目
【https://github.com/tesseract-ocr/tesseract/wiki/Compiling】
4. 各种语言的训练包,直接拿来用
【https://github.com/tesseract-ocr/tessdata】
5. 现在Tesseract负责人Ray Smith 的介绍论文
【https://github.com/tesseract-ocr/docs/blob/master/tesseracticdar2007.pdf】
6. wiki上的简介
【https://en.wikipedia.org/wiki/Tesseract_(software)】
以上是我在网上找了很多帖子,通过自己整理学习出来的。谢谢各位大佬。